
BigQueryとは?できることを初心者向けにわかりやすく解説

企業ではデータの蓄積が進む一方で、「部門ごとの分断」「分析の属人化」「定着の遅れ」といった壁に阻まれ、その活用は停滞しがちです。多くの企業がデータ活用を熱望しながらも、従来の基盤や運用面の制約から、なかなか成果を出せずにいます。
この課題を解決し、誰もが高速かつ柔軟にデータ分析を実現できる基盤として最近注目されているのが、Google Cloud の BigQueryです。本記事では、組織全体のデータ活用を加速させる BigQuery の仕組みと特徴を初心者の方にもわかりやすく解説します。
BigQuery サービス紹介資料
本資料では、Google Cloud の BigQuery を活用した最新のデータ分析基盤の構築方法を、わかりやすく解説します。AI 連携による実践的なユースケースや、導入企業の成功事例、SCSKによるスムーズな導入支援のポイントも紹介します。
目次
BigQueryとは?初心者にもわかるクラウド型データ分析基盤
BigQueryは、Google Cloud が提供するクラウド型のデータウェアハウス(DWH)で、大規模データを高速に分析できるサービスです。サーバーの準備や運用が不要な"サーバーレス型"を採用しているため、環境構築の手間を最小限に抑え、すぐにデータ分析を始められる点が強みです。
また、操作にはSQLを使えるため、専門的なエンジニアスキルがなくても扱いやすく、多くの企業でデータ活用基盤として採用されています。
BigQueryが選ばれる4つの特徴と活用メリット
BigQueryには、従来の分析基盤にはないユニークな特徴があります。ここでは代表的な4つを紹介します。
1.運用管理が不要!誰でも迷わず使えるサーバーレス基盤
BigQueryは、サーバーの管理や性能を最適な状態に保つための調整が一切不要なサーバーレス基盤です。ユーザーは必要な分だけリソースを利用するだけで済むため、IT担当者は煩雑な「環境管理」から解放され、「分析や施策立案」といった、より本質的な業務に集中できるようになります。
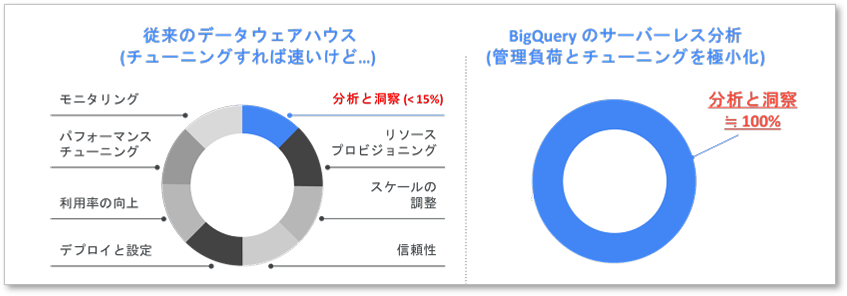
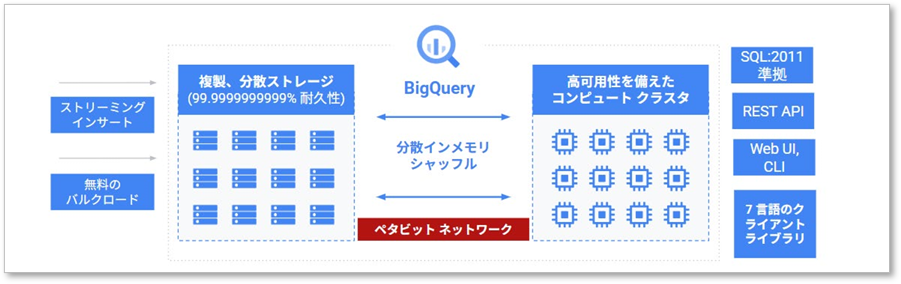
2.大量データも高速処理可能!ストレージとコンピュートの分離
BigQueryの最大の特長は、データを保存する場所(ストレージ)とデータを処理・分析する能力(コンピュート)が完全に分離されている点です。この分離構造により、データ量が増えても処理速度が落ちる心配がありません。ストレージとコンピュートをそれぞれ独立して増強(スケール)できるため、ペタバイト級の極めて大規模なデータに対しても、常に高速なクエリ実行が可能です。
3.SQLだけで機械学習も可能!BigQuery MLで簡単予測分析
BigQueryに搭載されているBigQuery MLを利用すれば、データサイエンスの専門知識がなくても、普段使いのSQLだけで機械学習モデルを構築できます。
これにより、顧客離反予測、需要予測、不正検知といった高度な予測分析に、誰もが簡単かつスピーディーに取り組めるようになり、組織全体のAI活用を一気に加速させます。

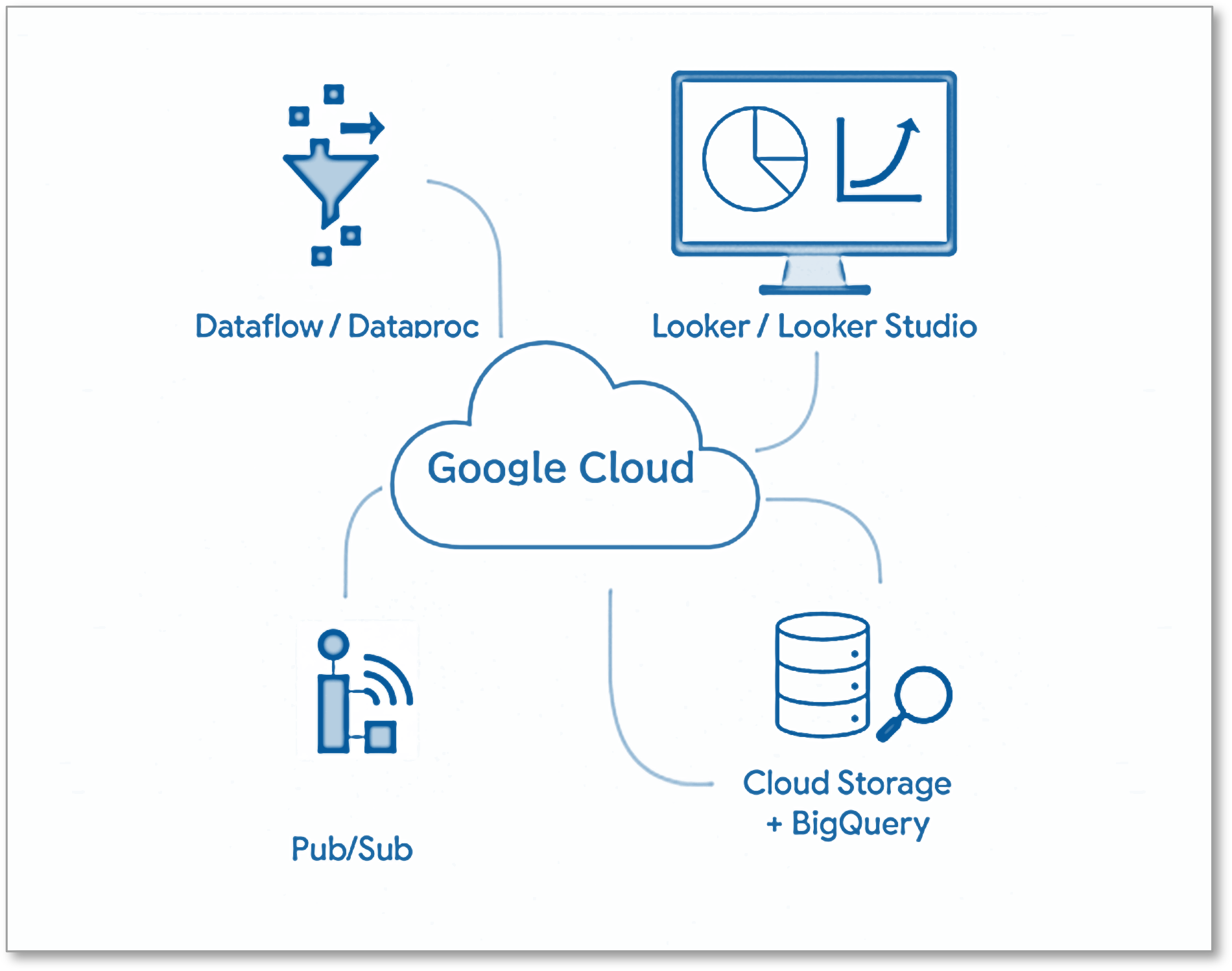
4.Google Cloudサービスと組み合わせてさらに便利に使える
BigQueryは、他のGoogle Cloudサービスとシームレスに連携することで、その真価を発揮します。
たとえば、Looker StudioやLookerといったBIツールと連携すれば、BigQueryでの分析結果を即座に使えるダッシュボードとして可視化し、組織全体で簡単に共有できます。また、DataflowやPub/Subといったストリーム処理サービスと組み合わせることで、ログやセンサーデータなどのリアルタイム性の高いデータを取り込み、ライブでの分析も可能になります。
BigQueryが必要とされる理由 - 企業が直面する3つのデータ活用課題
昨今、BigQueryが多くの企業で採用されている背景には、業種を問わず共通する根深いデータ活用課題が存在します。データ量が増大し続けるにもかかわらず、そのデータを活かしきれない理由は、次の3つに集約されます。
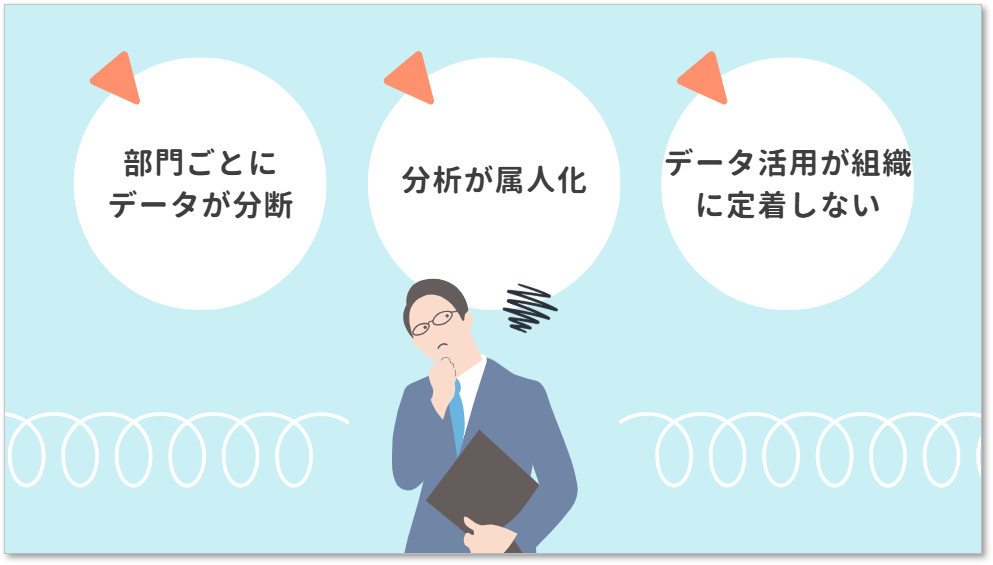
1.部門ごとにデータが分断され、一元的に活用できない
多くの企業では、営業、マーケティング、生産、顧客サポートといった部門ごとにシステムやデータベースが異なり、データが個別に管理されています。これにより、全社のデータを横断的に統合・分析することが難しく、ビジネスの全体像や、複合的な問題の原因を把握できません。
2.分析が属人化し、熟練者依存から脱却できない
従来の複雑なデータ基盤では、データの抽出や前処理、分析環境の構築に専門的な知識が必要でした。結果として、データ分析の作業が特定のIT担当者やデータサイエンティストに集中し、現場の社員が必要なときに必要な分析を行うことができず、スピーディーな意思決定の妨げとなっています。
3.データ活用が組織に定着しない
データを「見られる人」と「見られない人」が分かれると、意思決定にデータが十分に使われません。LookerやLooker Studioと組み合わせることで、誰でも必要なデータにアクセスできる環境を整え、データ活用が組織に浸透しやすくなります。
こうした「データ分断」「分析の属人化」「活用定着の遅れ」という企業の根深い課題を解決するには、膨大なデータを統合し、かつ、誰もがストレスなく高速に分析できる「新しい基盤」が必要です。
BigQueryは、インフラ管理の負荷をゼロにする「サーバーレス」、そしてペタバイト級のデータも数秒で処理する「圧倒的な処理能力」という独自のアーキテクチャによって、これらの課題を一掃します。つまり、BigQueryは単なるデータウェアハウスではなく、全社的なデータ駆動型経営を可能にするための「最も強力な選択肢の1つ」です。
次章では、このデータ駆動型経営を強力にサポートするBigQueryの仕組みを詳しく解説します。
BigQueryの仕組みをわかりやすく解説
BigQueryの驚異的な高速性を支えているのは、Googleが長年培ってきた革新的な分散処理技術です。データ分析のスピードと安定性を実現するために、以下の主要なコンポーネントが連携して動作しています。
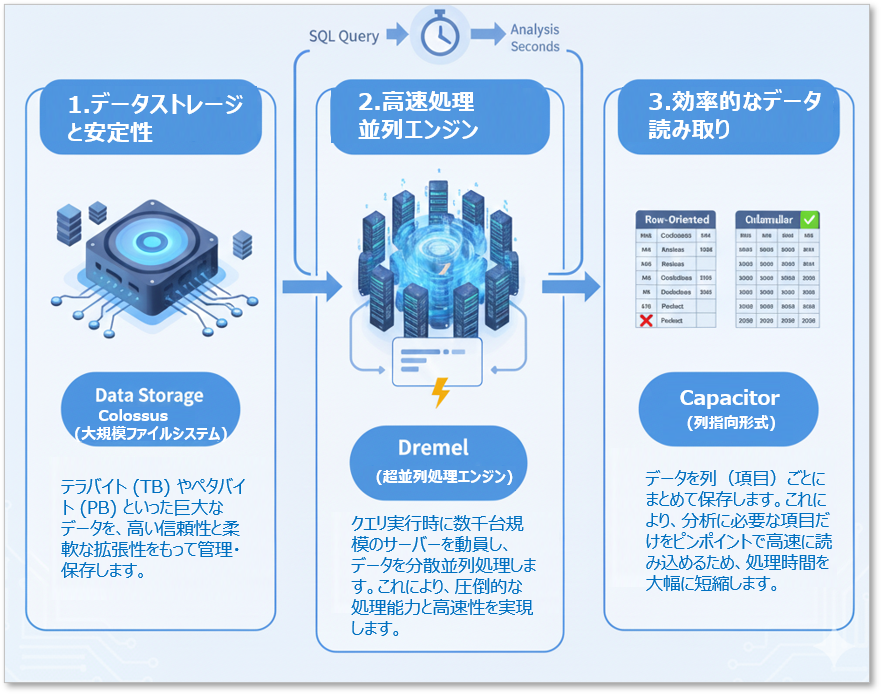
データの保存と安定性:Colossus(大規模ファイルシステム)
分析対象のデータは、Googleの大規模分散ファイルシステム「Colossus(コロッサス)」で管理されています。これにより、テラバイトやペタバイトといった巨大なデータでも、高い信頼性と柔軟な拡張性を両立させて保存・管理することが可能です
高速な処理能力:Dremel(超並列処理エンジン)
クエリ(分析要求)を実行するエンジンとして、「Dremel(ドレメル)」という超並列処理エンジンが用いられています。Dremelは、リクエストに応じて数千台規模のサーバーを動員し、データを同時に処理(分散並列処理)します。この圧倒的な処理能力により、従来のデータベースでは考えられないほどのスピードを実現しています。
効率的なデータ読み込み:Capacitor(列指向形式)
BigQueryのデータは、「Capacitor(キャパシター)」という列指向形式で保存されます。通常のデータベースが行単位でデータを保存するのに対し、列指向形式では項目(列)ごとにまとめて保存されます。これにより、分析に必要な項目のデータだけをピンポイントで、かつ高速に読み込めるため、大規模データでもわずか数秒で結果を返すことができるのです。
BigQueryでできること 業務横断のデータ活用事例
BigQueryは、企業のあらゆるデータを統合して分析できるクラウド型データ基盤です。業種や部署を問わず、マーケティング、EC・小売、製造業、システム運用など、さまざまな場面で活用されています。この章では、代表的な業界ごとのユースケースをわかりやすく紹介します。
製造業での活用例 :生産効率の向上と予防保全の実現
活用内容 : 生産ラインのセンサーデータや設備データをリアルタイムで収集・分析。
主な効果 : 稼働状況の可視化、予防保全、品質管理の改善に貢献。
設備の異常を早期に検知することで、ライン停止リスクの低減や生産効率の劇的な向上につながります。
マーケティング分野での活用例 : 高速分析による施策の最適化
活用内容 : アクセスログ、広告データ、顧客データなどを統合し、施策効果を分析。
主な効果 : 大量データでも高速に集計・分析できるため、PDCAサイクルが加速。
データに基づいた効果的なキャンペーン設計や、一人ひとりに合わせた高度なパーソナライズ施策の実施を可能にします。
EC・小売業での活用例 :需要予測による在庫の最適化
活用内容 : 売上データや在庫データ、気象データなどを組み合わせて分析。
主な効果 : 高精度な需要予測や在庫最適化を実現。
過剰在庫や欠品を防ぎ、ロスの少ない効率的な物流・販売計画の策定に役立ちます。
システム運用・その他:障害の予兆検知と全社的なデータ活用
活用内容 : システムログやサーバーログを蓄積し、障害の予兆を分析。BIツールとの連携。
主な効果 : 障害の早期検知や運用状況の正確な把握が可能になり、システム安定性が向上。
BIツールと組み合わせることで、誰でも使えるダッシュボードが構築でき、組織全体のデータ活用を強力に推進できます。
詳細は以下をご確認ください。
BigQueryの料金体系について
特筆すべきは、データを保存する料金(ストレージ)と、クエリ処理を行う料金(分析)が別々に課金される点です。これにより、企業は無駄なコストをかける必要がありません。データを保存するだけなら低コストで済み、必要なタイミングで分析を行うという、非常に合理的な仕組みとなっています。
BigQueryの料金体系に関して詳しい解説を知りたい方はこちらの記事をご確認ください。
BigQueryの料金体系を完全解説|高く感じやすい理由とコスト最適化の考え方
2026年現在の最新仕様を踏まえ、BigQueryの料金が高騰する原因を整理したうえで、現在の利用状況に合わせてコストを「予測可能な状態」で管理するための具体的なステップを解説しています。
記事を読むBigQuery導入を成功させるための3つのポイント
1.分析目的と対象データを明確にする
BigQueryを導入する前に、「何を分析し、その結果をどんな意思決定につなげたいのか」という具体的なゴールを明確に定義することが極めて重要です。目的が曖昧なままでは、必要なデータの選定や適切な基盤設計もできず、導入効果が薄れてしまいます。まずは解決したい課題から逆算して分析のスコープを定めましょう。
2.可視化ツールや連携サービスを組み合わせる
BigQueryは、その真価を他のGoogle CloudサービスやBIツールと連携することで発揮します。Looker StudioやLookerなどのBIツール、さらにはDataflowなどのデータ連携サービスと組み合わせることで、データの収集・分析から可視化、そして意思決定までの流れをエンドツーエンドでスムーズに整えることができます。
3.小さく始めて、段階的に拡張する
最初から全社規模で大規模な基盤構築を目指すのではなく、まずは一部の部門や特定のテーマに絞って小規模に導入し、早期に成功体験と実績を積む方法が効果的です。これにより、失敗リスクを抑えつつ、現場のニーズに合わせて基盤を最適化しながら、着実にデータ活用を組織全体に浸透させることができます。
まとめ BigQueryで高速データ分析を始めよう
BigQueryは、データ量の増加や分析速度の問題に直面している企業にとって、有力な解決策となるクラウド型DWHです。サーバーレスの手軽さ、Googleの先進技術による高速性、AI活用との親和性、さらにはGoogle Cloudサービスとの強力な連携など、データ活用を本格的に進めたい企業にとって最適な選択肢といえるでしょう。
SCSKが提供する BigQuery について
SCSKでは、BigQueryの料金体系や利用状況の分析に基づき、最適な設計・運用方法の整理をサポートしています。オンデマンド課金やEditions、コミットメントの選び方から、ワークロードに合わせたコスト最適化まで、企業ごとの状況に応じたアドバイスが可能です。 BigQueryの運用コストを抑えつつ、分析業務をスムーズに進めたい方は、ぜひSCSKのサービスをご活用ください。
BigQueryに関するご相談はこちら
関連コラム
BigQueryの料金体系を完全解説|高く感じやすい理由とコスト最適化の考え方
2026年現在の最新仕様を踏まえ、BigQueryの料金が高騰する原因を整理したうえで、現在の利用状況に合わせてコストを「予測可能な状態」で管理するための具体的なステップを解説しています。
記事を読む