
回帰分析における評価指標 ―①RMSE/MSE―
はじめに
H2O.AIやDriverless AIなどの自動化された機械学習プラットフォームにおいてデータサイエンティストの立場から、分析問題に対する最適化指標の選択に苦慮する方をたくさん見てきました。
確率的モデリング(ProbabilisticModeling)で誤差がひとまとめになっているのと異なり、回帰問題で評価指標の選択は特に難しくなる傾向があります。
「良いモデル」がすべての性能指標で良い結果を出すことを期待するでしょうが、そのようなことはほとんどありません。
多くの場合、最適化プロセスが開始されたタイミングでは、ほとんどの性能指標が改善されます。しかし、しばらくするとある指標での性能向上は、他の指標における性能劣化につながります。
特に平均絶対誤差(MAE)と平均二乗誤差(MSE)に関して、このような状況に何回も遭遇しています。
モデルにMAE最適化ロジックを選択したとき、アルゴリズムの最初の繰り返しでMSEもMAEも小さく(精度良く)なっていきました。ただし、しばらくするとMAEだけが改善され、MSEは増加しました。つまり、モデル最適化の際は、あなたが最も重視する指標の最適化を通じてのみ効果を最大化することが可能で、そうでなければ最適な結果とはならないでしょう。
この記事では、一般的な回帰の指標を確認して、特定の指標を利用する場合のおすすめだけでなく、それぞれのメリット・デメリットについて議論します。また、デモデータとしてKaggleの時系列売上予測データを利用します。これはリテーラーごとに異なる部署と店舗の習慣売上を予測するもので、データは140週以上の期間です。分析はH2O.aiのDriverlessAIを使います。下記がデータの概要です。
データの抜粋
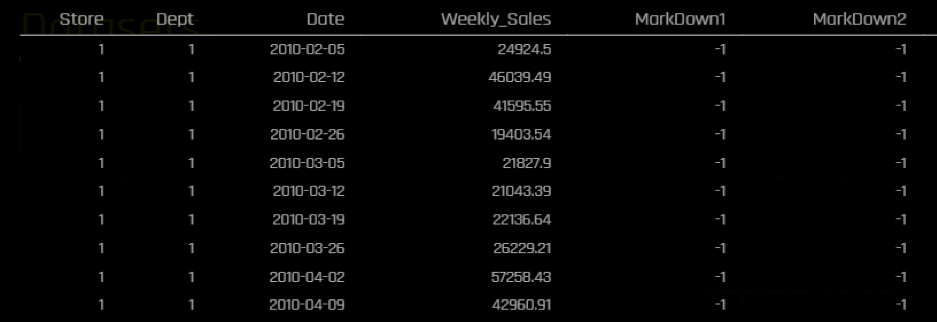
*ターゲット変数の分布は平均に対して、右側の裾がかなり伸びています。
ターゲット変数(Weekly_Sales:週間売上高)の詳細は次の通りです。
| Name |
Min(最小) |
Mean(中央) | Max(最大) | Std(標準偏差) |
| Weekly_Sales | -4,988.940 | 20,415.910 | 406,988.630 | 19,475.064 |
評価指標
RMSE(もしくはMSE)
二乗平均平方根誤差(RMSE)、平均二乗誤差(MSE)―平方根以外はRMSEと原則同じもの―は最も一般的な指標です。回帰の指標にキング/クイーンの称号があるならば、これでしょう。式は次の通りです。
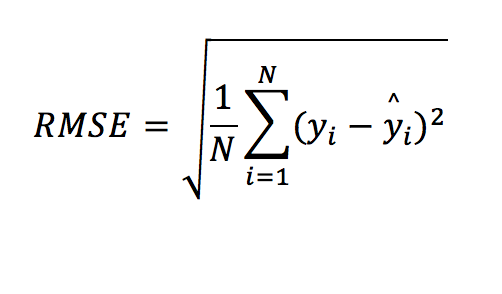
*ただし、y^iは予測値でyiが実測値
言い換えると、テストデータ/行ごとにすべての誤差(もしくは残差)を二乗して合計し、実測値の合計データ数で割ります。そのあと、指標を元のスケールに合わせるため、平方根を求めます(MSEでは実施しません)。
ポイント
- とても人気のある指標で、一般的な線形回帰を最適化/最小化する場合の指標です。最も古くから存在する指標でもあります。
- 誤差の値のため、小さいほど精度が良いです。また、0以上となります。
- 大きな誤差に大きな重みを付けます。1以下などの小さなエラーは二乗した際の累計誤差にはあまり寄与しません。一方、誤差が大きいほど、二乗による影響は大きくなります。
- 外れ値に対して脆弱です。サンプルデータの大きな誤差は累計誤差に大きな影響がありため、最適化ロジックはその1つのデータに対する誤差を最小化することに集中し、他のデータ全体に対する予測結果は悪くなります。
- 簡単に最適化可能です。二乗の性質から微分が容易なため、確率的勾配降下法(Stochastic Gradient Descent)のような勾配ベースのアルゴリズムに有利です。
- LightGBM、XGboost、Kerasなどの良く知られたアルゴリズムはRMSE/MSEの最適化ロジックを兼ね備えています。
どのような場合に使うか
大きな誤差を発生させたくないときに理想的な指標です。つまり、ある予測誤差が極端に大きくならない限り、複数のやや大きい予測誤差が発生してもよい場合に向いています。例えば、100の誤差が生じるより、+-200の誤差が生じるほうが2倍以上悪いといえるなら、RMSE/MSEは選択すべき指標です。
Experiment(H20での検証)
さて、Driverless AIの時系列モデルを利用してRMSEを最適化し、異なる店舗/部署における今後26週間の週間売上高を予測しましょう。本記事ではDriverless AIの時系列データの処理には深く触れないので、興味がある方は下記の動画*1や記事*2をご覧ください。
*1 https://www.youtube.com/watch?v=fxKF616nC1I&t=1667s
*2 http://docs.h2o.ai/driverless-ai/latest-stable/docs/userguide/time-series.html
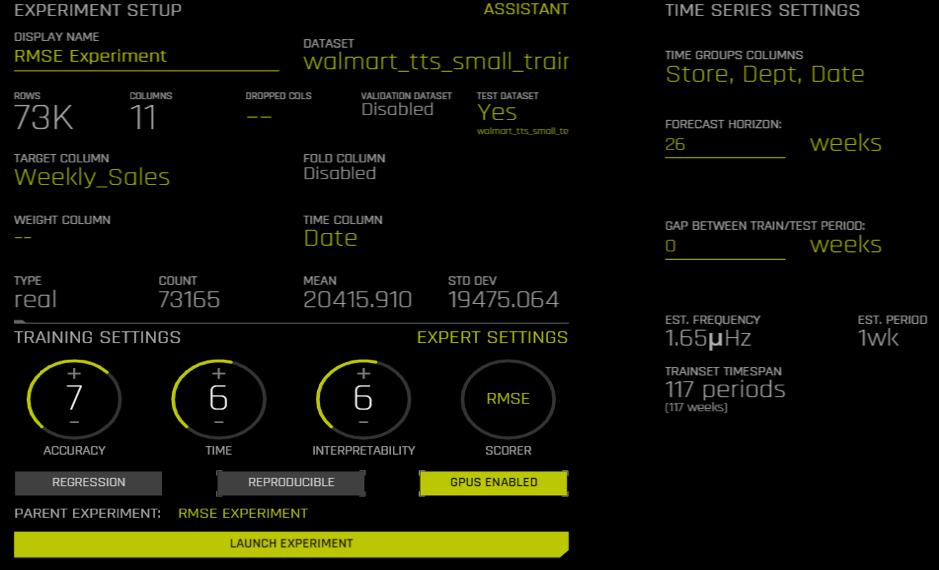
参考までにExperimentの設定は下記の通りです。
テストデータで得られた指標ごとの結果です。
|
Scorer(評価指標) |
Final test scores(最終テストスコア) |
| MAE | 2076.3 |
| MAPE | 24.196 |
| MER | 9.4783 |
| MSE | 1.3387e+07 |
|
R2 |
0.95816 |
| RMSE | 3658.8 |
| RMSLE | nan |
|
RMSPE |
17236 |
|
SMAPE |
17.048 |
RMSEで最適化されたモデルは3,658の誤差となりました。テストデータにおける目的変数の平均が20,000であることを考えると、誤差としては良い値です。特定の店舗/部署における個々の時系列を確認して、予測がどのようであったか見てみましょう。
例えば、店舗ID:39/部署ID:3では、テストデータ26週間分の実測値(黄色)と予測値(白)が確認できます。
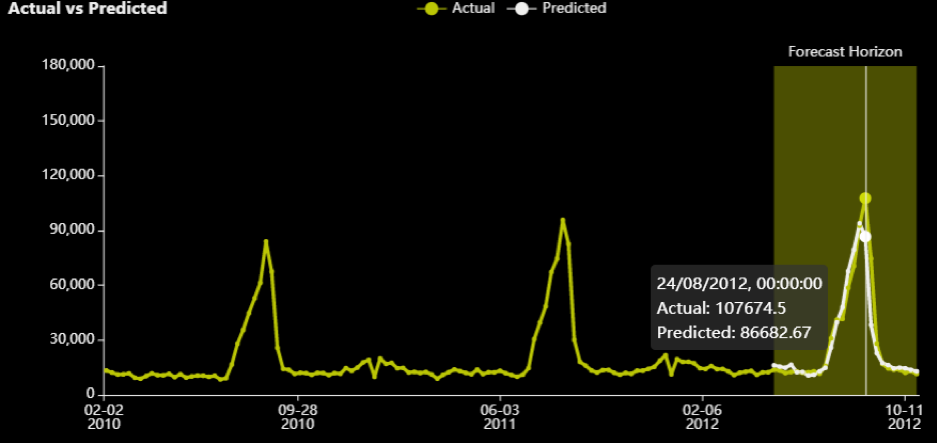
注意:8月におけるピークは他の年でも毎年発生しているため、季節的/周期的なようです。RMSEの最適化ロジックはこの予測に対する誤差を減らそうとします。
原題
(公式)H2O.ai Blog
Regression Metrics'Guide
Marios Michailidis
[次の記事に続きます。]