
Shapley値のご紹介
機械学習(ML)モデルによる恐怖の一つは、それらが説明のつかないブラックボックスであるということです。中には、あまりに複雑なため、専門家でなくとも、なぜそのような判断がなされるのか理解できないものもあります。このようなモデルが、ある人物を刑務所から釈放すべきかどうか、あるいはある患者に危険な外科手術を施すべきかどうかといった、大きなリスクを伴う判断に使われる場合、特に懸念されるのがこの点です。
説明可能あるいは解釈可能なML(しばしばXMLと表記される)の分野は、MLモデルがどのように意思決定を行うかを記述するツールや方法を作成することに焦点を当てています。この分野の基本的な手法の1つがShapley値で,この記事では,Shapley値とは何か,どのように使うかをやさしく紹介します。
Shapley値の例題
例えば、私たちが農業集団で、今年100万ドルの利益を上げたとしましょう。この金額をどのように分配すればいいのでしょうか。
各メンバーに均等に分配することができます。しかし、あるメンバーが売上の80%に貢献したとしたらどうでしょう?あるメンバーの銀行口座にお金が残っていて、公平な分配を受けられないなら全部チャリティーに出すと言われたらどうでしょう?あるメンバーが、売上は上げなかったが、みんなの生産性を上げる機械を提供し、その結果売上が20%上がったとしたらどうでしょう?
各メンバーの貢献度は様々であり、各メンバーが受け取るべき金額を決めるのは一筋縄ではいきません。この問題を解決し、各メンバーに公平に分配するために1951年にLloyd Shapleyが提唱した方法が「Shapley値」です。
Shapleyは、このツールを作ったとき、協力ゲーム理論を研究していました。しかし、これを機械学習の領域に移植するのは簡単でした。モデルの予測を「利益」、各特徴を「集団における農民」として扱うだけでいいのです。Shapley値は、各要素が予測にどれだけの影響を与えるか、(より正確には)各特徴が予測を平均的な予測からどれだけ遠ざけるかを教えてくれます。
Shapley値の算出
以下は、一つの特徴量Fに対するShapley値の計算手順です。
- すべての可能な特徴の組み合わせの集合(提携と呼ぶ)を作成
- モデルの平均的な予測値を算出
- 各提携について、Fを含まないモデルの予測値と平均予測値との差を計算
- 各提携について、Fを使ったモデルの予測と平均的な予測との差を計算
- 各提携について、Fがモデルの予測値を平均値からどれだけ変えたか(つまり、手順4-手順3)を計算 - これがFの限界貢献度
- Shapley値=手順5で算出した全ての値の平均値(つまりFの限界貢献度の平均値)
つまり、ある特徴量FのShapley値とは、Fがモデルに与える限界貢献度を、すべての可能な連合に対して平均化したものです。
簡単な説明にするため、厳密な数学的定義は避けますが、必要であればWikipediaやChristoph Molnar著の無料書籍「Interpretable Machine Learning」にアクセスしてください。計算が大変だと思われるかもしれませんが、その通りです。K個の特徴があれば、2**K個の連合があり、Shapley値の計算は指数関数的にスケールするのです。このため、Shapley値の計算をするのは非常に大変です。この性質が、何十年もの間、活用を困難にしていました。しかし、最近、大発見がありました。
PythonでのShapley値
2017年、LundbergとLeeは「A Unified Approach to Interpreting Model Predictions」と題する論文を発表しました。彼らは、Shapley値を他のいくつかのモデル説明手法と組み合わせて、SHAP値(SHapley Additive exPlanations)とそれに対応するSHAPライブラリを作成しました。
もし、あなたが自分のモデルのためにShapley値を作りたいのであれば、実際にはSHAP値を生成することになるでしょう。実際、私たちの調査では、Shapley値を実装したライブラリは見つかりませんでした。これは、SHAPがShapley値のすべての利点を取り、多くのマイナス面を改善したことを示しており、素晴らしいことです。SHAPライブラリの詳細な分析については、今後の記事のためにとっておきますが、あなたの興味をそそるように、いくつかの有用な可視化手法を共有したいと思います。
ここでは、KaggleのWine Rating & Priceデータセットのサブセットを使用します。このデータセットには5つのcsvファイルがありますが、今回はRed.csvのみ、約8,500行を扱います。このデータセットには、世界最大のワイン市場であるVivino.comからかき集めたデータが含まれています。このサイトの各ワインには、購入の判断に役立つ評価が付けられています。特徴列のサンプルを使って、各ワインの評価(5段階中)を予測し、SHAPライブラリを使ってShapley値を評価します。
# Standard imports import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns # Import shap and our model import shap from lightgbm import LGBMRegressor # Nicest style for SHAP plots sns.set(style='ticks')
最初に、ライブラリをロードします。ここではLightGBMを使用しますが、任意の回帰アルゴリズムを利用可能です。
red = pd.read_csv('Red.csv')
# Drop the 8 rows that are Non-Vintage i.e. NaNs
non_vintage = red.Year == 'N.V.'
red = red.drop(red[non_vintage].index, axis=0)
# Just keep numeric columns
X = red[['Price', 'Year', 'NumberOfRatings']]
# Cast all columns to numeric type
X = X.apply(pd.to_numeric)
y = red.Rating
csvファイルを読み込み、8つのNaN行を削除し、数値列からXを作成し、評価(Rating)をターゲット列としてyを作成します。
Priceはユーロでのワインの価格、Yearはワインが生産された年、NumberOfRatingsはこのワインをすでに評価した人の数です。
Create and fit model model = LGBMRegressor() model.fit(X, y)
次に、LightGBM回帰モデルをインスタンス化して学習させます(これは、CPUでも2秒未満で完了します)。
Create Explainer and get shap_valuese xplainer = shap.Explainer(model, X) shap_values = explainer(X)
次に、Explainerオブジェクトを生成し、そこからSHAP値を取得します。
# Create Explainer and get shap_valuese xplainer = shap.Explainer(model, X) shap_values = explainer(X)
次に、Explainerオブジェクトを生成し、そこからSHAP値を取得します。
print(shap_values.shape) # (8658, 3) print(shap_values.shape == X.shape) # True print(type(shap_values)) # <class 'shap._explanation.Explanation'>
shap_valuesオブジェクトはXと同じ形で、Explanationオブジェクトです。
print(shap_values[1]) .values = array([-0.13709112, 0.04292881, 0.01909666]) .base_values =3.892730293342654 .data =array([ 15.5, 2017. , 100. ])
shap_valuesのインデックス1の内容を見ると、次のものが含まれていることがわかります。
・.values - SHAP値自体
・.base_values -モデルの平均予測
・.data -元のXデータ
必要に応じて、dot notation accessorを使用してこれらのそれぞれに個別にアクセスできます。ありがたいことに、ほとんどのshapプロットは、Explanationオブジェクトを受け入れ、バックグラウンドで手間のかかる作業を行います。
ウォーターフォールプロットをいくつか作りましょう。
shap.plots.waterfall(shap_values[1])
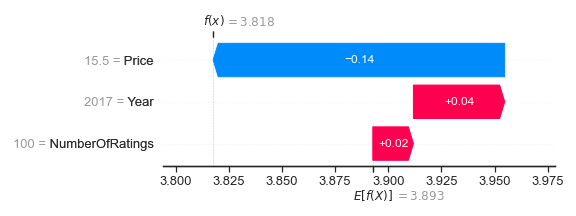
ウォーターフォールプロットは、SHAP値がモデル予測をチャートの下部に表示されている期待値E [f(X)]から上部の予測値f(x)にどのように移動させるかを示しています。これらは、最小のSHAP値を一番下にしてソートされます。
shap_values.base_valuesによって与えられる期待値3.893は、プロットの下部にあります。 shap_values.dataによって指定された元のXデータは、左側に特徴とそれに対応する値を示しています。最後に、shap_values.valuesで指定されたSHAP値は、予測値が増加するか減少するかに応じて、赤または青の矢印で表示されます。
NumberOfRatings = 100およびYear = 2017は、このワインにプラスの影響を与え、合計ゲインは0.02 + 0.04 = 0.06であることがわかります。ただし、Price =€15.50では、予測値の評価(Rating)が0.14減少します。したがって、このワインの評価(Rating)予測は3.893 + 0.02 + 0.04 - 0.14 = 3.818であり、プロットの上部に表示されます。 SHAP値を合計することにより、このワインの評価は平均予測より0.02 + 0.04 - 0.14 = -0.08低いと計算されます。 SHAP値を一緒に足し合わせられることは重要な特性の1つであり、それらがShapley additive explanation(直訳:シャプレイの加法的な説明)と呼ばれる理由の1つです。
もう一つの例を見てみましょう。
shap.plots.waterfall(shap_values[14])
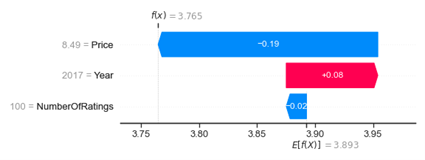
このワインもNumberOfRatings = 100とYear = 2017ですが、SHAP値は異なります。最初のプロットでは、NumberOfRatings = 100の結果は+0.02になりましたが、このプロットの場合は-0.02です。最初のプロットでは、Year = 2017は+0.04でしたが、このプロットでは+0.08です。この不一致は、サンプルが特定の特徴に対して同じ値を持っている場合でも、それらが同じSHAP値を持っていることを保証するものではないことを示しています。この理由をこの記事では説明しませんが、今のところ知っておくだけで十分でしょう。
最後に、決定木ベースのモデルで一般的に使われる特徴重要度のプロットを見てみましょう。
shap.plots.bar(shap_values)
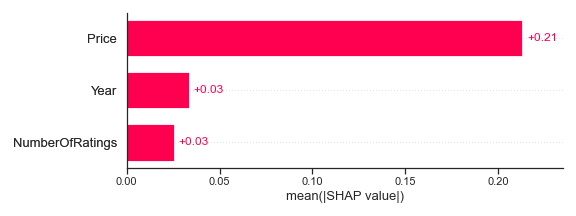
各特徴の平均SHAP値をプロットしました。Priceは最も高く平均+0.21ですが、YearとNumberOfRatingsはそれぞれ+0.03で近い値です。したがって、これらの特徴量の値が大きくなると、一般に予測される評価(Rating)が高くなります。
Shapley値とH2O
H2Oでは、Shapley / SHAP値とその他の世界クラスのモデル解釈可能性手法を、AIハイブリッドクラウド(Driverless AIを介して)とH2O-3の両方に組み込みました。たとえば、Driverless AIでは、オリジナル特徴量のShapley値を、特徴量エンジニアリングで変換された特徴量のShapley値と比較できます。この手法は、手間のかかる特徴エンジニアリングを行っていて、2つのセット間の予測力の違いを知りたい場合に役立ちます。
結論
Shapley値は、協力ゲームでの公平な支払いを保証するために70年以上前に作成されました。現在、機械学習コミュニティはそれらを採用し、理論的に適切な方法でモデルを解釈するためにそれらを使用しています。この強力で価値のあるツールについては、氷山の一角を取り上げました。この記事がブラックボックスのモデルをより理解できるようなガラスボックスへ変えるためにShapleyやSHAPを活用する勇気を与え、世の中に大きなポジティブな影響を作り出せることを願っております。
原題
(公式)H2O.ai Blog
Shapley Values - A Gentle Introduction
Adam Murphy