
回帰分析における評価指標―⑤R2(決定係数)―
評価指標
R2
R2(決定係数)は線形回帰と評価について学び始めた時に、最初に目にする指標でしょう。線形の場合、R2の計算は以下と同値です。
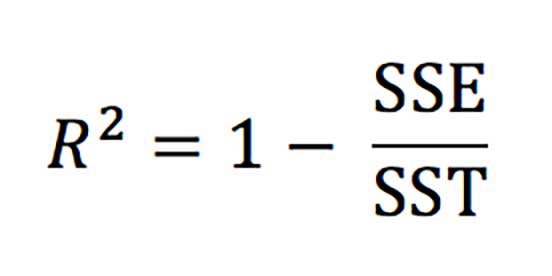
公式の要素を分解すると、
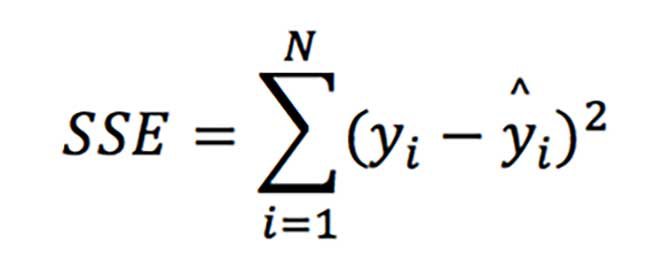
つまり、SSE(残差平方和)はRMSEの式における平均や平方根を求めない二乗誤差です。
SST(二乗平均)は以下の定義です。は目的変数の平均値です。
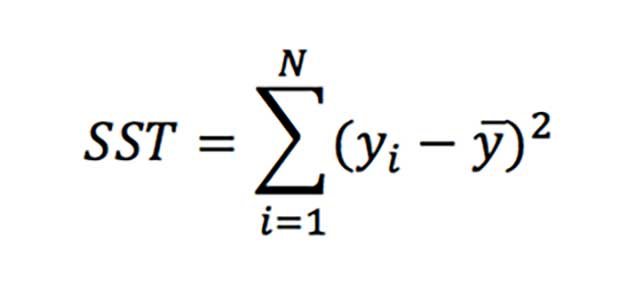
R2の公式に戻ると、予測値にターゲット変数の平均値を用いただけの単純なモデルと、作成したモデルを比較(前者で後者を割っている)だけです。それゆえ、この指標は非常に単純なモデルと比較した場合のパフォーマンスを示しています。いくつかのケースでは、R2係数はマイナスとなります(ターゲット変数の平均値よりも予測精度が悪い場合)。
ポイント
- とても人気です。MSEに次ぐ評判です。
- 高いほど良いモデルです。値域は-∞から1までです。
- デル間の比較が簡単で一貫したものとなります。例えばRMSEで誤差が5の場合を考えると、「誤差が5です」というセリフは文脈無しでは意味を持ちません。もし日ごとの気温を予測している時には、5という数値は正常な範囲のエラーに思えます。しかし、家族内の子供の数を予測している場合、+-5の誤差は良いとは言えません。平均的に子供の期待値を5も間違えていることになります。この様な場合だと原始的なモデルの方が良い精度になるでしょう。しかし、R2は基本的なモデルと精度を比較している指標になるため、これはモデル間で比較可能な値になります。経験的に下表を参考にR2の精度を確認できます。コンテクスト無しにこのような表を別のモデルで作成することはできません。
R-squared(R2の値)
Assessment(評価)
<0.0
ターゲット変数の平均値を予測するより悪い
<0.1
悪い
<0.2
やや悪い
<0.3
悪い~普通
<0.5
普通
<0.7
普通~良い
<0.9
良い
>0.9
非常に良い!
- 精度の低いモデルでも価値があるということは忘れないでください。「すべてのモデルは間違っているが、中には役立つものもある」という格言もあります。時には、平均よりやや良いモデルは利用して価値があるものです。例えば、直近の気象情報から3時間後の風速を予測する場合、これまでのⅹ時間の平均より優れた予測は、飛行機の離陸判断など人命を救うかもしれません。
一方で、R2が高いからと言って利用価値があるとはいえないでしょう。例えば、マーケティング会社がDM会社に1,000ドルの支払いを行い、その製品を宣伝されている異なるユーザに毎日100,000通のメールを送る契約をしたとします。この100,000通のメールから商品を購入したユーザにより、10,000ドルの収益が発生します。ほとんどの収入がメール対象ユーザのごく一部から発生していると仮定しましょう。マーケティング会社は500ドルで10,000通送付する別のDM会社を選ぶことで費用を削減できます(元々は1,000ドルで100,000通です)。100,000の人から発生する総収益を予測するモデルを作成し、最も購買確率が高いと予測された10,000人分を安価なDMサービスへ切り替えてコスト削減を行ったのです。このモデルは一人当たり収益予測でかなり高いR2のモデル(例えば0.9)だったとします。その場合、購買確率が高かった10,000のケースで、100,000名すべてのユーザにコンタクトしていた場合に予想された収益の90%(もしくは9,000/10,000ドル)を占めます。完璧でなくとも、かなり優れた予測結果と思えます。 しかし、10%の収益(1,000ドル分)は失われたままであり、変更後のDMサービスで送付されなかった90,000名の予想収益は500ドルのDM費用削減効果を上回ります。 この例では、出来上がった高精度モデルでは企業に利益をもたらさない、使えないモデルです。 - 平均誤差についてはあまりわかりません。前述の通り、基本的なモデルよりどの程度精度が良いかを示すためです。そのため、この指標はRMSEやMAE、その他の誤差を確認できる指標と合わせて確認することをお勧めします。
- 無限に負の値となるため、直感に反します。
- MSEやRMSEの最適化ロジックが使えます。
- ほとんどの製品/パッケージで最適化ロジックを持っています。
どのような場合に使うか
予測値にターゲット変数の平均値を利用する基本的なモデルに対して、どの程度の精度が出せるのか確認したいときです。理想的には、なんらかの形式で誤差を測定できる他の指標と合わせて利用すべきです。この指標は全く異なるものを予測するモデル間の精度比較の助けになります。
相関係数とR2
モデル間の比較が可能というR2を利用するメリットを覆しかねないのが、無限の負の値です。これを避けるため、Driverless AIではR2はピアソンのr(ピアソンの積率相関係数)を二乗することでR2を計算しています。MSE線形回帰の最適化ロジックの場合、結果は前のセクションと同じ公式から計算されます。他のタイプのモデルでは、R2は異なる式でしょう。
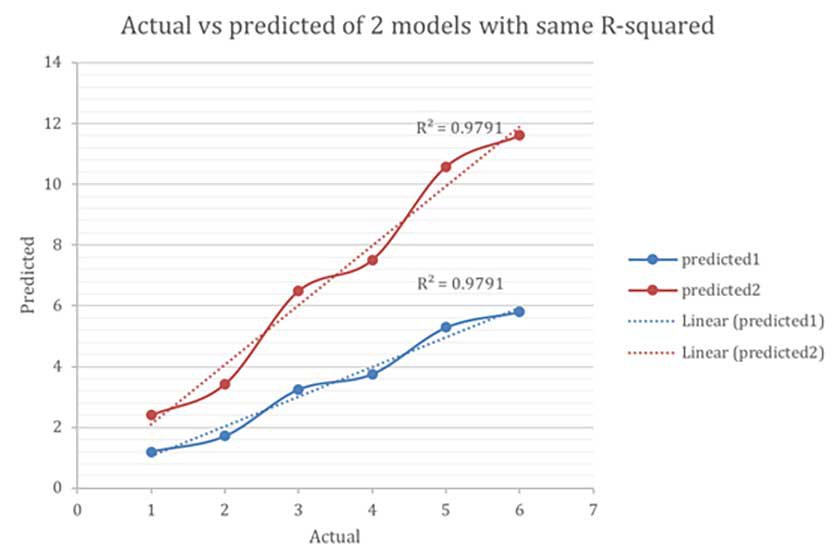
この式では、R2は予測と実測値の共に変化する度合いを表現しています。この状態のR2は0~1の間で変化します。0は予測と実測に相関が一切なく、1は完全な相関があることを意味します。しかし、内部的にMSE最適化ロジックを利用することにより大幅に最小化を行うこの手法の弱点は、計算上の誤差を完全に無視するという仕様にあります。まず程度はともかく実測値と予測値を近似させることに注力します。例えば、下記の2モデルは同じR2スコアです。
青の系列はより誤差が少ないですが、どちらのモデルもターゲット変数変動を予測するという点で同じ能力をもちます。これまで述べた通り、この欠点はMSEの最適化ロジックで最小化された場合に軽減されます。
Experiment
R2による検証結果は以下となりました。
|
Scorer(評価指標) |
Final test scores(最終テストスコア) |
|
GINI |
0.9867 |
|
MAE |
1898 |
|
MAPE |
23.193 |
|
MER |
8.2822 |
|
MSE |
1.1824e+07 |
|
R2 |
0.96271 |
|
RMSE |
3438.5 |
|
RMSLE |
nan |
|
RMSPE |
15894 |
|
SMAPE |
15.666 |
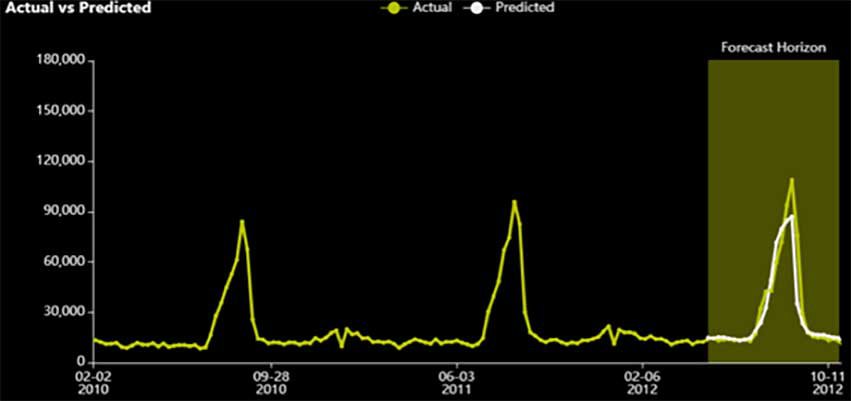
0.96271のR2はすべてのExperimentで最も高い値で、予測と実測値の比較はMAPEのケースに似ています。
原題
(公式)H2O.ai Blog
Regression Metrics'Guide
Marios Michailidis