
回帰分析における評価指標 ―③MAPE―
評価指標
MAPE
平均絶対パーセント誤差(MAPE)は実際の値でなく、パーセントで誤差の度合いを計測します。本質的にはMAEと同じですが、各データの絶対誤差が実測値(絶対値)で除算されているため、単位がパーセンテージとなっています。
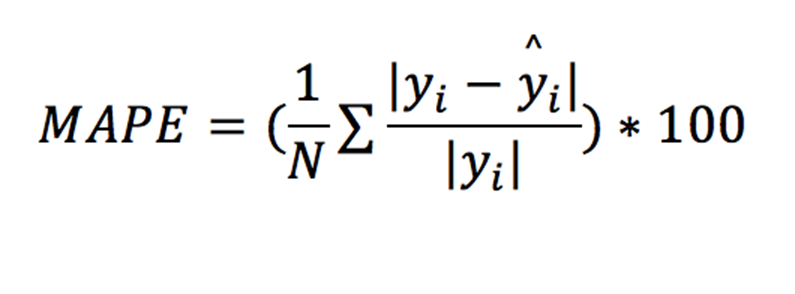
これは私が見た中では、最もトリッキーな指標だと思います。この指標で評価するときはいつも苦労します。(気にしないでほしいですが、)この指標について語るときはすこし感情的かもしれません。
ポイント
- ビジネスシーンでは人気があります。パーセント表示のため、簡単に理解でき活用することができるからです。例)「予測モデルにおける誤差は平均してⅹ%です」
- 小さいほど良い値です。100%以上も取りうる点は注記します。
- すべてのパーセント化された誤差は同じ重みをもちます。20%の誤差は10%の誤差の2倍悪いです。
- MAPEは誤差における量や単位を考慮しません。10,000ドルの実測値に対して1,000ドルの誤差は「1,000$/10,000$ =10%」となりますが、「1,000,000$ /10,000,000$ =10%」の誤差と同じ値となります。他の例でも、0.1ドルに対して絶対誤差が0.2ドルであった場合、MAPEは200%となってしまい前の例の20倍悪い結果です。そして、最適化の際にも20倍の重みをもちます。このことから、いくつかの値で百万、十億という誤差を生じさせる一方で、パーセンテージ比では小さい量の誤差となってしまい、過小な誤差を報告してしまう可能性があります。すべての誤差が実測値に対して相対的な値となります。
- MAPEは実測値がゼロの場合に定義できません。これに対する対処方法はいくつかあります。たとえば、計算からゼロの実測値を除いたり制約条件を追加したりなどです。ただ、どの対処法も欠点があるため、ゼロデータの多い場合にはMAPEはおすすめできません。のちに検討する対照平均絶対パーセント誤差(SMAPE)がこのような場合に適しています。他の代替策は加重絶対パーセント誤差(WAPE)でしょう。基本的にMAPEと同じですが、違いとして最初に全ての誤差と実測値が合計されて、実測値の合計に対する絶対誤差の合計の比を計算します。このようにして、(もちろんデータ次第ですが)実測値がゼロに近づく可能性はかなり低くなりますが、個々のデータのWAPEに対する影響はほぼ無くなるため、大きな誤差が生じたデータは無視されて個別データに依存しなくなり、目的変数のばらつきを捉えるのが難しくなります。つまり、目的変数の変動に対して少し鈍感すぎてしまいます。
- RMSEやMAE同様に外れ値に対して脆弱です。一つ二つの大きな誤差程度でMAPEは"荒れ狂いません"が、同時に実測値も大きい場合は、目的変数の分布から問題が生じます(次のポイントを参照ください)。
- ゼロや極小な値が多く含まれるような大きな値域と標準偏差のデータで予測が難しい目的変数の場合、MAPEは小さなパーセンテージから大きなパーセンテージへ"爆発"します。信じられませんが、悲しいことに何回もMAPEが1000000000%になったことがあります。例えば、大きい金額の株式ポートフォリオにおける日次損益予測といったようなユースケースは高難易度です。ある日は0.03ドル儲かるかもしれないし、その翌日は10,000ドル失うかもしれません(*我々のアルゴリズムは高い精度なので、弊社製品を利用頂ければこのようなことはそう簡単に起きないでしょう😊😊)。では、過去実績から申し分ない値である100,000ドルが翌日分の予測値であったとして、結果的には0.01ドルしか儲からなかったとしましょう。この場合のMAPEは「999999.99$/0.01 = 9,999,999,900%」になります!目的変数の幅が広く予期せぬスパイクがある場合にMAPEは使い物になりません。また、これによりMAPE最適化のロジックが働かなくなり、一定値の予測値しかとらないようになります。こういった場合の最適解は、目的変数の取りうる範囲を説明するのに十分な数値になるように、すべての目的変数に一定の値を加えることです。私はこの値をExperimentごとのハイパーパラメータとしています。この値が大きすぎるとモデルが予測値のばらつきを学習出来なくなり、小さすぎるとMAPEはかなり大きな値のままとなります。ベストな値を見つけるためには複数のExperimentが必要です。予測後には加えた値をマイナスすることを忘れずに。
- MAPEもまた最適化が難しいです
- いくつかのパッケージで最適化ロジックが準備されています(例:Tensorflow/Keras、LightGBM)。覚えておかないといけないのは、MAPEの最適化が難しく上手く動作させるためにその他のハイパーパラメータの最適化が必要になるため、この最適化が常に機能するとは限らないことです。
Experiment
MAPEを選択して①RMSE/MSE、②MAEと同じパラメータでExperimentを実行しました。下記が結果です。
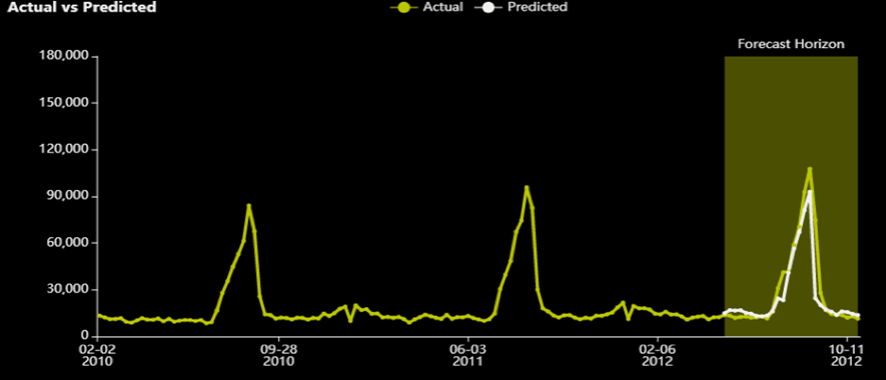
MAPEはこれまでの最小値で16.77%となりました。MAEは1998.4でMAEのExperiment(1,883)より悪化していて、RMSEは3812.6となりRMSEのExperiment(3658.8)より悪化しています。またしてもMAPE最適化はMAPEのスコアを改善し、他のスコアラーを選択したExperimentよりも他の値は悪化しました。経験的にも実際の値でも、MAPE最適化の結果はMAE最適化の結果に近くなります。ただ、店舗ID:39/部署ID:3のグラフから明確わかるわけではないです。
グラフで特徴的な点は、誤差がゼロのデータがほとんどないことです。予測の系列は実測の系列に近いもののほぼ重なっていません。RMSEとMAEの2つの最適化ロジックは誤差がゼロとなる箇所がいくつもありましが、MAPEはRMSEのグラフのピークで誤差が生じたのと同様の状態です。
次のセクションに移る前に、もう一つ例を挙げます。スコアリングに利用したテストデータセットは異なる店舗/部署の組合せで16,280行あります。MAPEは16.77%でした。2012/03/08の店舗ID:10/部署ID:2のデータは113,930.5でDriverless AIは112,740.76と予測しました。この行のMAPEは1.04%です。仮にこの日に多くの返品があり、実際の売上高が0.01ドルだった場合、この日(この行)のMAPEは1,127,407,600%となります。そして、すべての行に対するモデル全体のMAPEは69,767.00%になってしまいます!小さい実測値に対する一つの悪い予測結果がMAPEの計算ロジックではとても大きな重みをもち、モデル全体の精度がとても低く見えます。
どのような場合に使うか
目的変数のばらつきが少なく標準偏差が小さい場合に使うことが理想的です。予期せぬスパイクがなく、分布に極端な凹凸がない正の値を目的変数が取るような場合です。また、パーセンテージの指標で簡単に誤差を説明出来たり、それをプロジェクト関係者が好む場合も良いでしょう。
原題
(公式)H2O.ai Blog
Regression Metrics'Guide
Marios Michailidis