
文脈を考慮した特徴抽出による自然言語処理モデルの性能向上
今回は、テキスト分析の特徴量エンジニアリングを改善するためのシンプルで非常に効果的な方法を紹介したいと思います。この記事を読んだ後、私たちのH2O AI Cloudを使って同じステップで試すことができるようになります。
最初に、H2O Driverless AI(AI CloudのAutoML製品の1つ)の既成の自然言語処理(NLP)レシピを見てみましょう。Term Frequency-Inverse Document Frequency(TF-IDF)のような標準的なテキスト変換レシピから、Convolutional Neural Network(CNN)、Bi-directional Gated Recurrent Unit(BiGRU)、Bidirectional Encoder Representations from Transformers(BERT)のような複雑なレシピもあります。利用可能なテキスト変換の全リストはこちらでご覧いただけます。
H2O Drivereless AIの既成のNLPレシピ
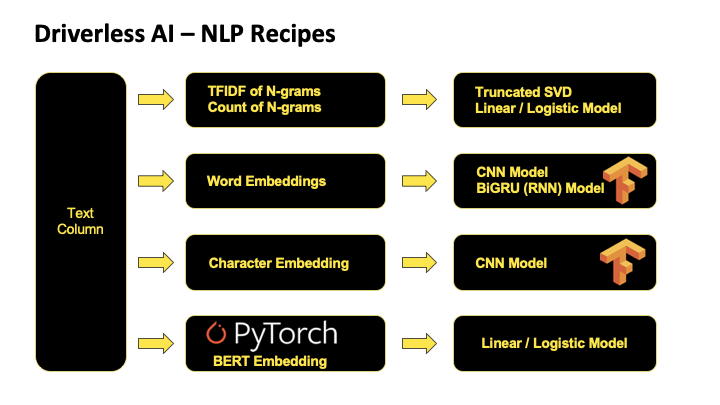
私たちは最も一般的なテキスト分析のユースケースをカバーする、多くの汎用的なNLPレシピをすでに持っています。しかし、それだけではありません。私たちは、スマートな、そしてより重要なドメイン固有の特徴抽出によって、予測性能をさらに向上させることが可能であることを理解しています。そのため、Driverless AIのNLP機能は、カスタムレシピによって拡張できるようになっています。リサーチコミュニティが提供する最先端のNLPモデルを活用し、Driverless AIで最小限の労力で文脈を考慮した特徴抽出を行うことができるのです。それでは、どのように行うのかお見せしましょう。
簡単なチュートリアル - 航空会社のTwitterセンチメント分析
航空会社のTwitterセンチメント分析用データセットは2015年に取得されました。これをポジティブ、ネガティブ、ニュートラルなツイートを分類するという問題です。データセットの詳細については、こちらからダウンロードできます。データセットで利用可能な20列のうち、text(唯一の特徴量)とairline_sentiment(目的変数)のみ利用します。

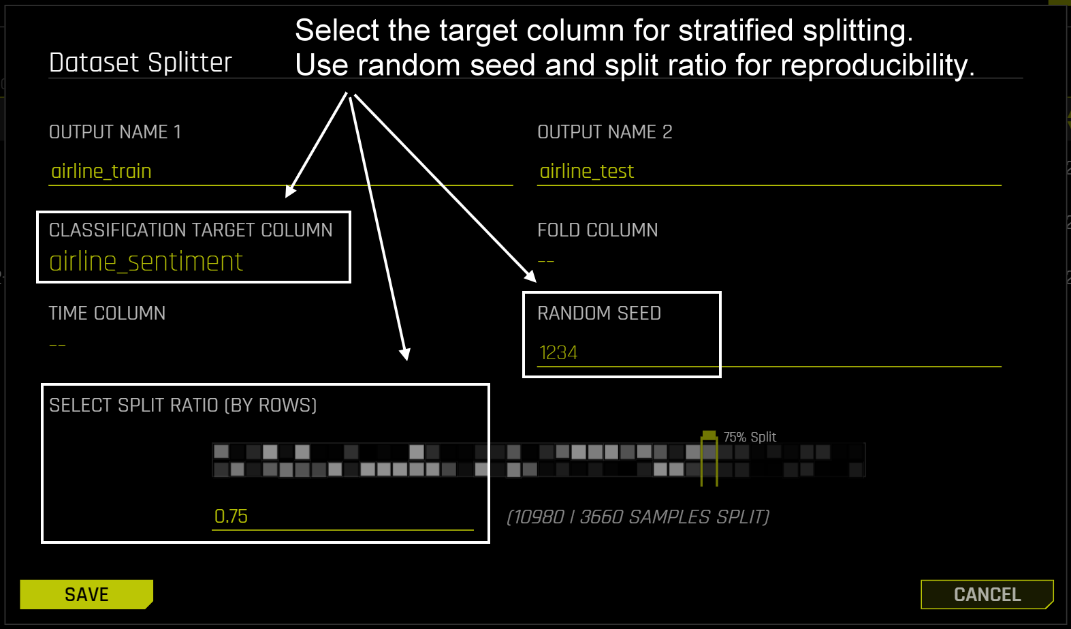
ステップ1 - データ分割
以下の手順で、航空会社のデータセットをDriverless AIにインポートします。航空会社のTwitterセンチメント分析用データセットは、専用のテストデータセットがない1つのCSVであるため、以下のようにデータ分割機能を利用して、データセットをairline_train(学習データ)とairline_test(テストデータ)に分割します。
ステップ2 - ベースラインモデルの構築
さて、airline_trainを使って最初のモデルを学習し、airline_testで未知データへのパフォーマンスを評価する準備ができました。最初のベースラインモデルでは、ほとんどの設定をデフォルトのままにしておきます。この演習では、単一の特徴としてtext列のみを使用するため、experimentを開始する前に残りの設定を削除する必要があります(下記のdrop columns 設定を参照)。
ベースラインモデルのDriverless AIモデル学習設定
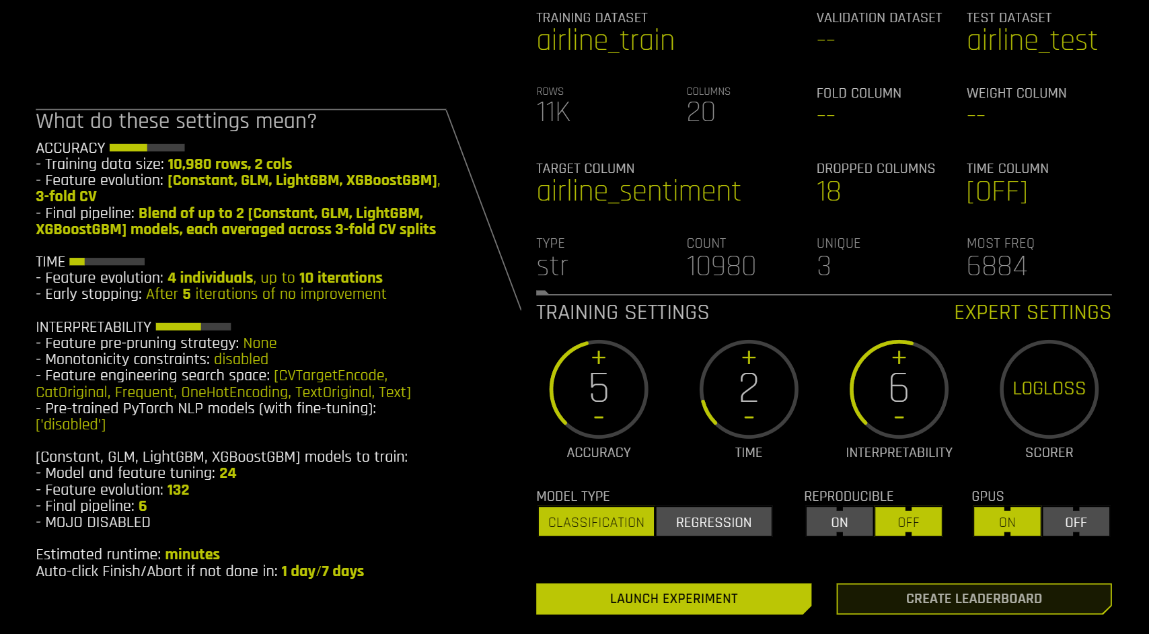
drop columnsの設定でtext以外を落とすことを忘れずに

複雑なテキスト変換(例:CNN、BiGRU、BERT)を無効化しているため、この単純なexperimentから変換された特徴は全てTF-IDFベースです。このベースラインモデルは、より複雑な変換を行うことで、確実に改善することができますので、次のステップに進みましょう。
ベースラインモデルで最も重要な特徴は、TF-IDFベースの単語埋め込み

ステップ3 - CNNとBiGRUによる特徴量変換でベースラインを改善
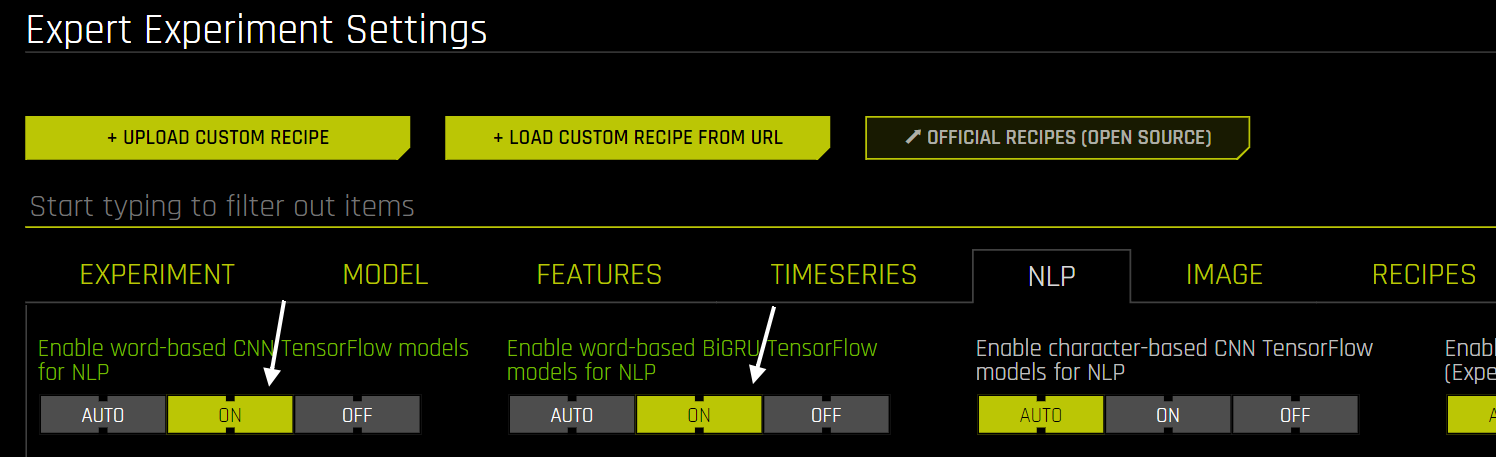
より複雑なテキスト変換を有効にするために、エキスパート設定で下記のように2つの値を変更する必要があります。これにより、自動特徴エンジニアリングパイプラインで単語ベースのCNNとBiGRUテキスト変換が有効になります。その結果、experimentではCNNとBiGRUに基づいて重要な特徴量が作成されていることがわかります(ベースラインモデルではTF-IDFベースの特徴)。また、モデル性能の向上も確認できます(例えば、loglossやエラーレートの低下)。この性能をさらに向上させることはできるのでしょうか?
NLPエキスパート環境における単語ベースのCNNおよびBiGRUモデルの有効化
CNNとBiGRUの新機能により予測性能が向上

Hugging Face Model Hubへの参入
次のステップに行く前に、Hugging Faceという素晴らしいプラットフォームを紹介しましょう。彼らのホームページには、こんな文言があります。
"人工知能🔥を進化させるという目標"に向かって、コミュニティが協力し合うことを支援しています。1つの企業、たとえITの巨人であっても、それだけで「AIを解決」することはできません。私たちがこれを達成する唯一の方法は、知識とリソースを共有することなのです。Hugging Face Hubでは、すべての人のためにAIを民主化し進歩させるために、モデル、データセット、メトリクスの最大コレクションを構築しています🚀。Hugging Face Hubは、誰もがモデルやデータセットを共有して検索できる中心的な場所として機能します。" (引用元:Hugging Face)
ステップ4 - ドメイン固有のトランスフォーマーの探索
Hugging Faceで"twitter"というキーワードで検索すると、Cardiff NLPグループのtwitter-roberta-base-sentimentというモデルを見つけることができます。このモデルは多くの異なるツイートに対して学習されたものです。これは私たちのユースケースと関係がありそうなので、試してみましょう。
Hugging Faceに関するドメイン固有モデルの探索
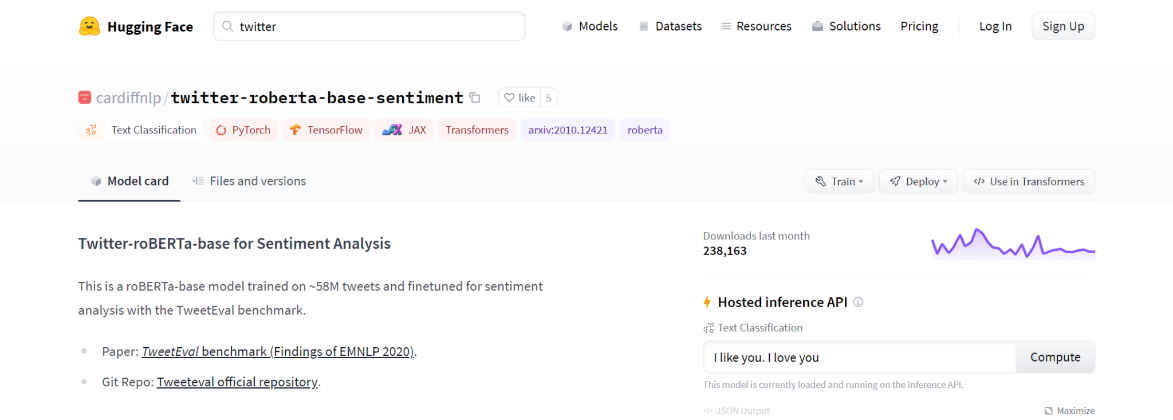
新しい特徴量として利用できそうなtwitter-roberta-base-sentimentモデルの出力例

ステップ5 - Twitter-Roberta-based Transformerで文脈を考慮した特徴を抽出
さて、ここが最も重要なステップです。これを正しく行えば、Hugging Faceからさらに多くのtransformerをインポートすることができるようになります。
まず、Driverless AI に twitter-roberta-base-sentiment transformerをインポートする簡単な Python スクリプトを作成する必要があります。このスクリプトをTwitterRobertaTransformer.pyと呼ぶことにしましょう。このスクリプトで最も重要なパラメータは、MODEL_NAMEとclassです。これらをHugging Faceの他のtransformerと置き換えることで、多くのtransformerをDriverless AIにインポートすることができるようになります。
from h2oaicore.systemutils import config from h2oaicore.transformer_utils import CustomTransformer from h2oaicore.transformers_nlp import BERTTransformer MODEL_NAME = 'cardiffnlp/twitter-roberta-base-sentiment' class TwitterRoberta(BERTTransformer, CustomTransformer): _mojo = False @staticmethod def get_default_properties(): return dict(col_type="text", min_cols=1, max_cols=1, relative_importance=1) @staticmethod def get_parameter_choices(): return dict(model_type=[MODEL_NAME], batch_size=[config.pytorch_nlp_fine_tuning_batch_size], seq_length=[config.pytorch_nlp_fine_tuning_padding_length] )
スクリプトが準備出来たら、エキスパート設定のレシピタブで、以下のようにスクリプトをアップロードします。また、特定のtransformer設定でTwitterRobertaを選択して有効にする必要があります。その後、特徴量エンジニアリングの検索スペースにTwitterRobertaが表示されるようになります。
カスタムレシピによる新機能変換の追加
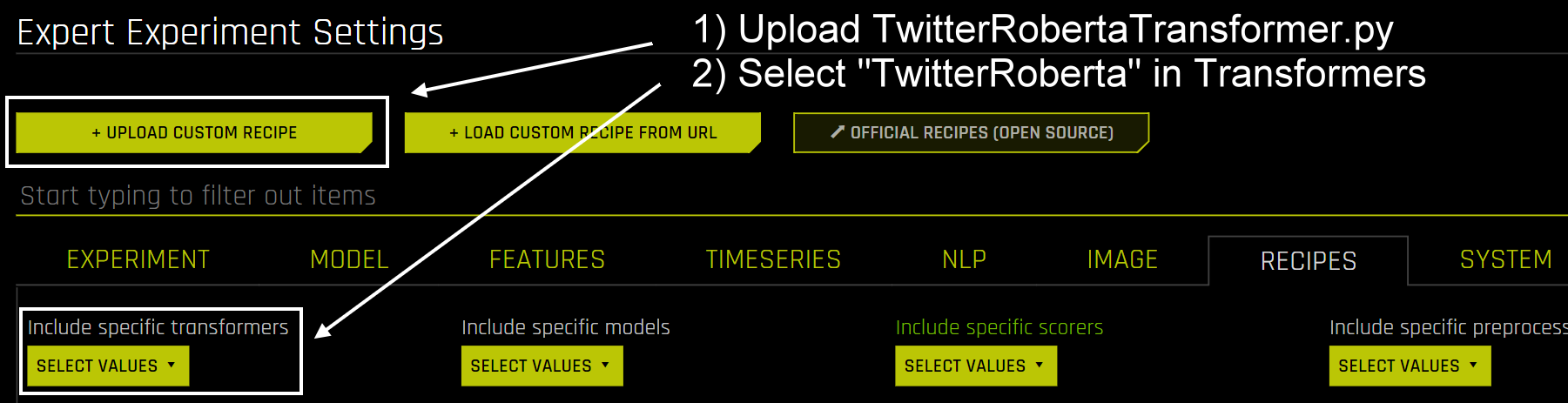
Twitter-Robertaベースの変換が特徴量エンジニアリングパイプラインで利用可能
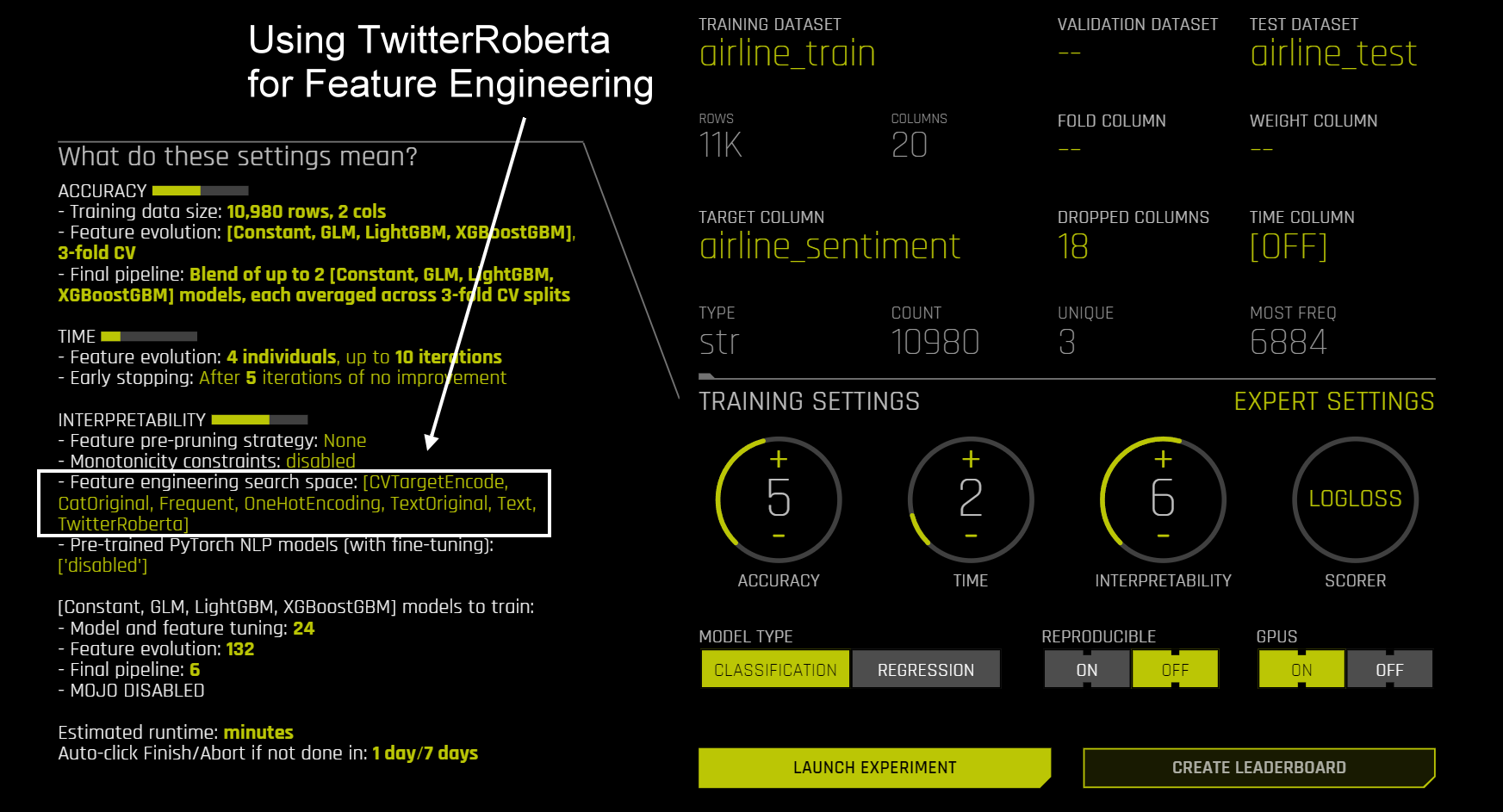
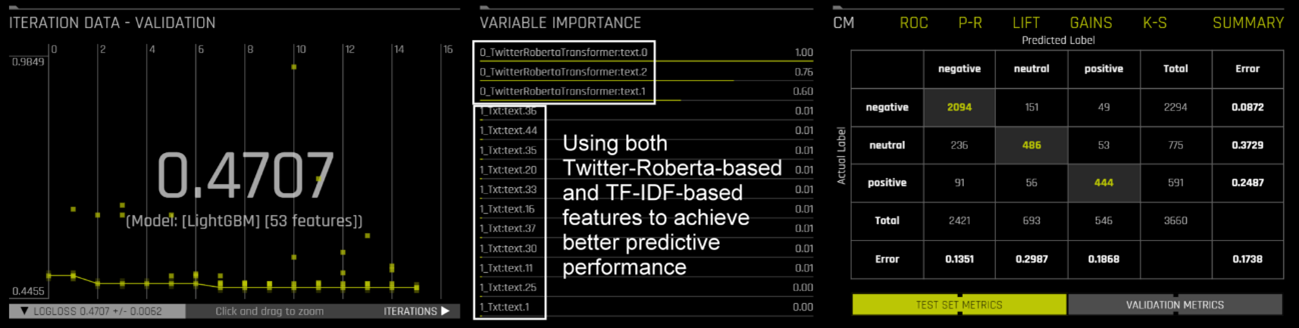
期待通り、twitter-roberta-base-sentimentモデルからドメイン固有の特徴を用いて、より良い予測性能を得ることができました。
Twitter-Robertaベースの特徴が予測性能をさらに向上
まとめ
本内容はTF-IDFのような標準的なテキスト変換を用いたシンプルなベースラインモデルから始めて、CNN/BiGRUの特徴変換を用いて性能を向上させるというものでした。さらに、文脈を考慮したドメイン固有な特徴抽出を行うために、twitter-roberta-base-sentiment transfomrerを導入し、モデル性能をさらに向上させることができます。
様々なテキスト変換に基づくモデル性能の比較
(スコア = logloss, 低いほど良い)

次はあなたの番です!
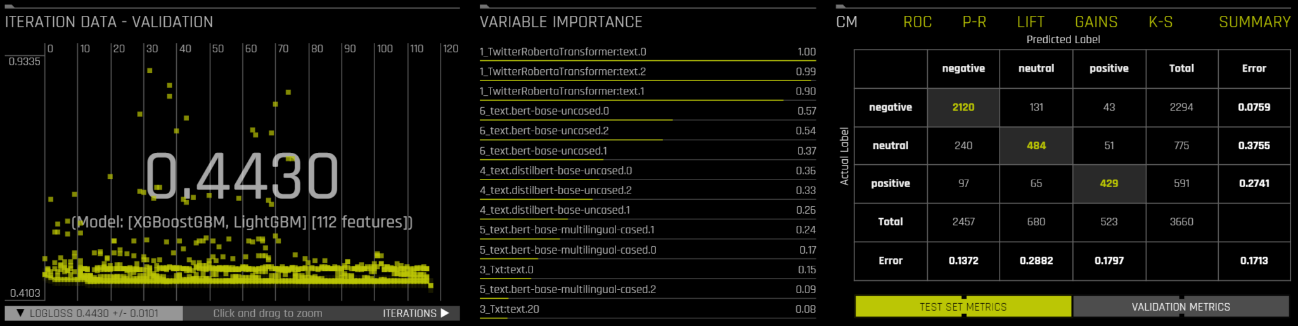
このモデルをさらに改良することも可能です(下のスクリーンショットをご覧ください)。具体的な方法は控えますが、きっとすぐにお分かりになるはずです。ここにいくつかのヒントがあります。
- Driverless AIに付属する他のBERT transformerをオンにすることは可能か?
- 精度/時間/解釈可能性の設定を変えてみてはどうか?リーダーボード機能が役に立つかもしれません。
- Hugging Faceの他のtransformerを組み合わせて使うことはできるか?
異なるtext transformerを混在させることができます。そう、これよりもっといいものができるのです
キーポイント
カスタムレシピを使えば、AIコミュニティの最先端のモデルを用いて、Driverless AIのテキスト変換を拡張・改善することが可能です。このように、私たちは、自動特徴量エンジニアリングパイプラインを将来にわたって維持するための技術をすでに持っています。私たちは、ユーザーがさまざまなtransformerを使って何ができるかを見ることにワクワクしています。例えば、ヘルスケアのユースケースのためにBioBertで予測に使える特徴を抽出することは可能でしょうか?FinBertから得られる特徴を使って、株式市場で競争力をつけることは可能でしょうか?可能性は無限大です。私たちは、この技術によって、ユーザーが最小限の労力で最新のtransformerの恩恵を受けられるようになることを願っています。
無償トライアル
H2OのNLP機能を実際に検証されたい方には、ハンズオンセミナーや無償トライアル環境を提供しております。お問合せフォームからご連絡ください。
原題
(公式)H2O.ai Blog
Improving NLP Model Performance with Context-Aware Feature Extraction
Jo-Fai Chow