
Driverless AIを顧客購買分析に利用してみた!(後編)
Driverless AI(1.7.0以降)は、BYOR(Bring Your Own Recipesの略)と呼ばれる重要な機能を実装しています。レシピとは、Driverless AIプラットフォームのカスタマイズおよび拡張機能です。独自のレシピを作成することもできますし、https://github.com/h2oai/driverlessai-recipes リポジトリで利用可能な複数のレシピから選択することもできます。ここでは、利用可能なレシピの1つを使用して、Driverless AIによるレコメンデーションシステムを開発します。
目的
映画レコメンデーションシステムを作ってみましょう。このシステムは、ユーザや映画に関する事前の知識を持たず、ユーザが与えた評価を通じて、ユーザと映画との相互作用のみを考慮します。データから学習し、自己および他者の行動に基づいて、ユーザに最適な映画をレコメンドします。
ここで重要なのは、これが回帰問題であるということです。一方、ユーザが特定の商品を購入するかどうかを予測したい場合は、分類問題となります。
データセット
このデータセットは、有名なサイト「Movielens」のものです。MovieLensは、あなたが好きな映画を見つけるのに役立ちます。映画を評価して自分好みのプロフィールを作成すると、MovieLensが他の映画をレコメンドしてくれます。オリジナルのデータには、13万8000人の無作為に選ばれた匿名のユーザによる2000万件以上の評価が含まれています。
この記事では、他の人がすぐに実験を再現できるように、オリジナルデータの一部のみを使用することにしました。ここでは、トレーニングデータの最初の数行を紹介します。
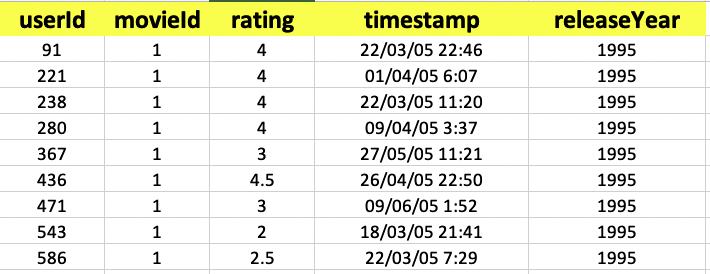
- userId:お客様のID
- movieId: 各ムービーに固有のID
- rating: 1から5までの5段階評価。今回のTarget変数
- timestamp: レーティングが行われた日付と時刻
- releaseYear:映画が公開された年
協調フィルタリングの手法
ここでは協調フィルタリングレシピの手法を簡単に説明します。
1.Driverless AIへのデータのアップロード
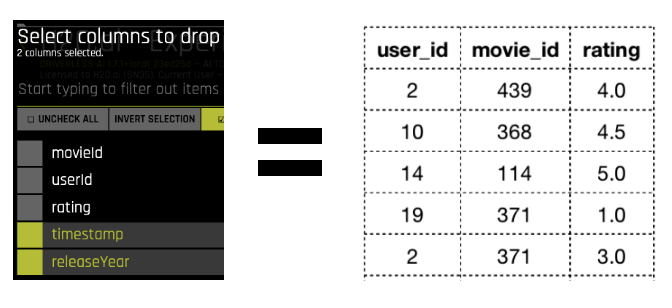
トレーニングデータとテストデータは、新しいDriverless AIのインスタンスにロードされます。協調フィルタリングモデルでは、データはユーザーアイテムまたはユーティリティマトリックスの形式である必要があり、各セルは与えられたアイテムに対するユーザの好みの度合いを表します。そこで、データセットから以下の列のみを使用して、評価をターゲット列とする協調フィルタリングを実装することにします。
2.カスタムレシピのアップロード
GitHub リポジトリからレコメンデーションレシピファイルをローカルシステムにダウンロードします。トランスフォーマ(特徴量変換)の初期化で、データセットのカラム名と一致するように、userカラム名とitemカラム名を編集してください。MovielensデータセットのuserとitemはそれぞれuserIdとmovieIdとなっているので、コードファイル中のuserとitemをそれらに置き換えます。

コードファイルでこれらの値を編集して保存し、レシピを以下のようにDriverless AI Experimentにアップロードします。
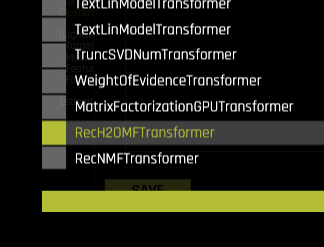
次に、「エキスパート設定」→「レシピ」→「特定の特徴量変換を含める」と進み、RecH2OMFTトランスフォーマーのみを選択し、他のトランスフォーマーの選択をすべて解除します。
Experimentタイプとして「回帰」、スコアラーとして「RMSE」を選択し、Experimentを開始します。

Matrix Factorizationトランスフォーマーが何をしているのか、簡単に理解してみましょう。
まず、映画評価データフレームを次のようにユーザ項目行列(ユーティリティ行列とも呼ばれる)に変換します。
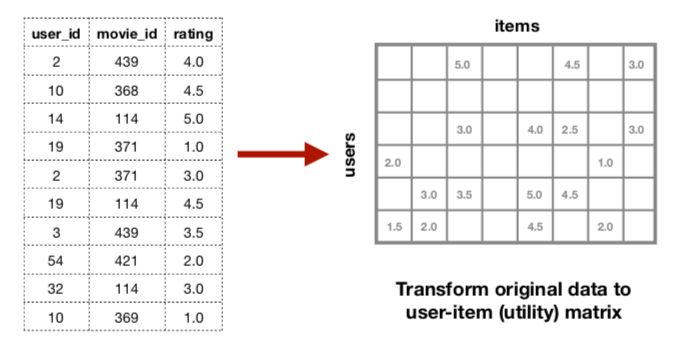
この行列の各セルには,ユーザが映画に与えた評価が入ります。
これは、スパースな評価行列 X (m×n, N_z 個の非ゼロ要素を持つ) を m×k と k×f の行列に変換するもので、潜在因子は K で表されます。この再構成された行列は、元のユーザ項目行列の空のセルを埋めるので、スパースな行列の未知の評価が既知になります。
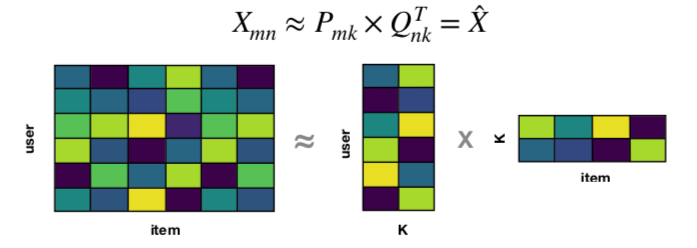
H2O4GPUによるMF技術の実装
行列因子分解は、ユーザとアイテムの相互作用行列を、より低次元の2つの長方形の行列の積に分解する、協調フィルタリングでよく使われる手法です。行列分解の背景にある考え方は、ユーザとアイテムを低次元の潜在因子を用いて表現することです。

Driverless AIでは、h2o4gpu.solvers.factorizationモジュールを介して行列因数分解が実装されています。h2o4gpu.solvers.FactorizationH2Oは、Alternating Least Square(ALS)アルゴリズムによるGPU上の行列因子分解を実装します。
コンテンツベースフィルタリングの手法
コンテンツベースフィルタリングでは、ユーザの属性やアイテム自体の属性に基づいてアイテムをレコメンドします。そこで今回は、与えられた学習データのうち、タイムスタンプの列を除くすべての列を対象とします。
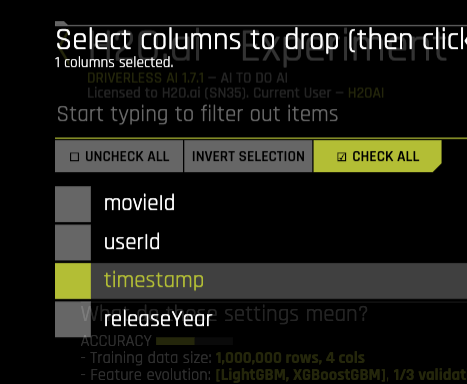
次に、RecH2OMFTトランスフォーマーの選択を解除しますが、デフォルトのものはすべてそのままにしておきます。その他のパラメータは先ほどのExperimentと同じにして、Launchボタンを押します。
ハイブリッドフィルタリングの手法
ハイブリッドフィルタリングは、その名が示すように、コンテンツベースフィルタリングと協調的フィルタリングの両方の特性を組み合わせて、ユーザーアイテムとトランザクションデータの両方を活用してレコメンドを行う手法です。このExperimentでも、コンテンツベースのExperimentと同様に、データセットのすべての列を選択します(タイムスタンプ列を除く)。しかし、ここでの違いは、他のデフォルトのトランスフォーマーに加えて、RecH2OMFTトランスフォーマーを選択することです。

RecH2OMFTトランスフォーマーが、Experimentページで選択された他のトランスフォーマーとともに反映されていることを確認します。続けて、Experimentを開始します。Driverless AIは、様々なトランスフォーマーを使って複数の機能を構築し、コンテンツ機能とコラボレーション機能の間の重みを最適化するために複数のモデルを試します。
Experiment結果の概要
下のスクリーンショットは、コンテンツベースフィルタリング、協調フィルタリング、ハイブリッドフィルタリングの結果を比較したものです。

純粋な協調フィルタリング手法のRMSEは0.96で、コンテンツベースフィルタリング手法のRMSEは0.94でした。両者を組み合わせたハイブリッドフィルタリング手法では、RMSE が 0.92 となり、それぞれを明らかに上回っています。
また、同じMovieLensデータセットで、XGBoostが生の特徴量に対して0.98のスコアを出しているのに対し、LightGBMは0.99のスコアを出しているのも興味深い点です。
したがって、Driverless AIのレコメンデーションレシピは、特徴エンジニアリングとモデル最適化を組み合わせたものであり、オープンソースのアルゴリズムを使用した場合と比較して優れた性能を発揮すると結論付けてよいでしょう。
トップNのレコメンデーション商品
Experimentが終わると、ユーザは他のドライバーレスAIのExperimentと同様に、予測結果をダウンロードすることができます。

そして、予測された評価をすべてソートして、そのユーザに対する上位N個のレコメンデーションを得ることができます。また、ユーザが以前に利用したことのあるアイテムを除外したり、フィルタリングしたい場合もあります。映画の場合、ユーザが以前に見たことのある映画をレコメンドしても意味がありません。
結論
レコメンデーションシステムは、顧客ごとにパーソナライズされたショッピング体験を提供することで、ターゲットマーケティングの効果的な形態を提供します。レコメンデーションシステムは、現代の顧客サービスには欠かせないものであり、それによってユーザのエンゲージメントを高めることができます。
Driverless AIを使えば、どんな企業でもレコメンデーションシステムを簡単にビジネスに取り入れることができます。詳しくは以下の資料をご覧ください。
- H2O.aiのウェブサイトでDriverless AIについて詳しく知る
- Bring your own Recipe機能についての詳細
- レシピのアップロードと操作に関するハンズオンチュートリアル
原題
(公式)H2O.ai Blog
Driverless AI can help you choose what you consume next
Parul Pandey