SCSKが推奨するHPE ProLiantシリーズおよびHPE Cray XDシリーズにNVIDIA製GPUを搭載するサーバーは、ベースに汎用のIAサーバーを利用することによって、高い信頼性とリプレースの自由度を両立することができます。
HPE ProLiant DL380a Gen11
- 極めてスケーラブルな設計と先進的なGPUを搭載したAI推論に最適なプラットフォーム


最大4基のダブルワイドGPUを搭載。高いデータ転送とネットワーク速度によって、大規模なAI推論にも対応します
HPE ProLiant Compute DL380a Gen12
- NVIDIAと共同で独自に開発
- 極めてスケーラブルなGPUアクセラレーションにより、大規模なワークロード向けの卓越したAIのファインチューニングと推論を実現


最大4基のダブルワイドGPUを搭載し、様々なAIワークロードに対応します
HPE ProLiant DL385 Gen11
- 2UサイズでNVIDIA H100 GPUと第4世代AMD EPYCプロセッサを搭載した高性能サーバー


エッジからクラウドまで。パフォーマンスをカスタマイズし、ビジネス向けのハイブリッドニーズ応えます
HPE ProLiant Compute DL384 Gen12
- 革新的AI、HPC対応!GH200スーパーチップで未来を先取り!


AIとHPCに特化した高性能GPUとメモリを搭載し、大規模なファインチューニングやRAG推論に対応
HPE Cray Supercomputing XD670
- NVIDIA H100 または H200 Tensor Core GPU を8基搭載可能
- 多様なAIワークロードをサポート


各種のAIベンチマークにおいて卓越したパフォーマンスを発揮。AI環境のスモールスタートから大規模展開も可能
HPE Cray XD2000
- 高密度設計によりラック搭載スペースを削減
- CPUとGPUの組み合わせにより強力な計算性能を提供


高度な集約・柔軟な設計により、ビジネスニーズに合わせた高拡張性を誇ります
HPE Machine Learning Development Environment(MLDE) ―機械学習モデルの開発を推進―
最も迅速、簡単に機械学習モデルを構築する方法
HPE MLDEの導入によって、数日から数週間かかっていたトレーニングを数時間に短縮し、より高精度なモデルを構築し、GPUコストを管理しながらさまざまな実験を追跡また再現できるようになります。Determined AIのオープンソース型トレーニングプラットフォームを基盤とするこのソリューションでは、機械学習モデル開発の簡素化と関連コストの削減が実現するため、イノベーションに向けてインフラストラクチャの管理ではなく、モデルの構築に注力できるようになります。
モデルのトレーニングを高速化
MLエンジニアは、マルチノードマルチGPUの分散トレーニングや最先端の自動ハイパーパラメータ探索を活用してモデルのトレーニングを高速化できます。マシン、ネットワーキング、データロード、およびフォールトトレランスのプロビジョニングを管理して、分散モデルトレーニングを迅速かつ容易に行えるため、あらゆる規模でトレーニングを行うことができます。
複雑さを解消してコストを削減
IT管理者によるAIコンピュートクラスタのセットアップ、管理、セキュリティ確保、共有が容易になるため、MLモデル開発者が成果を実現するまでの時間を短縮できます。デベロッパーはスマートスケジューリングでGPUを有効活用するとともに、スポットインスタンスのシームレスな活用でクラウドのGPUコストを削減できます。
データサイエンスとのコラボレーションの強化
実験の追跡やモデルの容易な再現などの機能によって、MLチームのコラボレーションが容易になり、ミッションを迅速化します。結果として、チームは実験結果を容易に解釈し、実験を再現・活用できます。
MLエンジニアのニーズに対応
HPE MLDEは、イノベーションに注力して本稼働までの時間を短縮できる、新しいソリューションを探し続けている機械学習(ML)エンジニアとデータサイエンティストのニーズに対応します。MLモデルの開発を簡素化するとともに、関連コストを削減し、MLモデル開発者の成果達成までの時間を短縮します。
クラウド、オンプレミスで展開されるインフラストラクチャがともにサポートされているHPE MLDEでは、PyTorch、TensorFlow、Kerasを使用してモデルを開発でき、データ準備やモデル展開向けのMLツールとのシームレスな統合も可能です。
-
インフラストラクチャのコード記述が不要
-
IT管理者は、AIコンピュートクラスタを簡単にセットアップ、管理、保護、共有が可能
-
容易に設定可能な最新の分散型トレーニングによってモデルのトレーニングに必要な時間を短縮
-
最新のチューニングアルゴリズム作成者による高度なハイパーパラメータチューニングを使用して高品質モデルを自動検索
-
スマートスケジューリングでGPUを有効活用するとともに、スポットインスタンスの活用でクラウドのGPUコストを削減
-
コードのバージョン、メトリクス、チェックポイント、ハイパーパラメータを網羅する実験追跡機能で作業の追跡と完全な再現が可能
簡単に実行できる、分散型トレーニングのシームレスな拡張
HPE MLDEでは、MLエンジニアはモデルコードを変更することなく、MLトレーニングを複数のノード、また数百個のGPUへとシームレスに拡張できます。分散型トレーニングのジョブは、1つの設定を変更するだけで簡単に開始できます。MLエンジニアによるHPE MLDEの拡張をサポートするべく、拡張に向けたインフラストラクチャコードのトレーニング、さらにマシンのプロビジョニング、ネットワーキング、データロード、フォールトトレランスなどのサポートも提供しています。
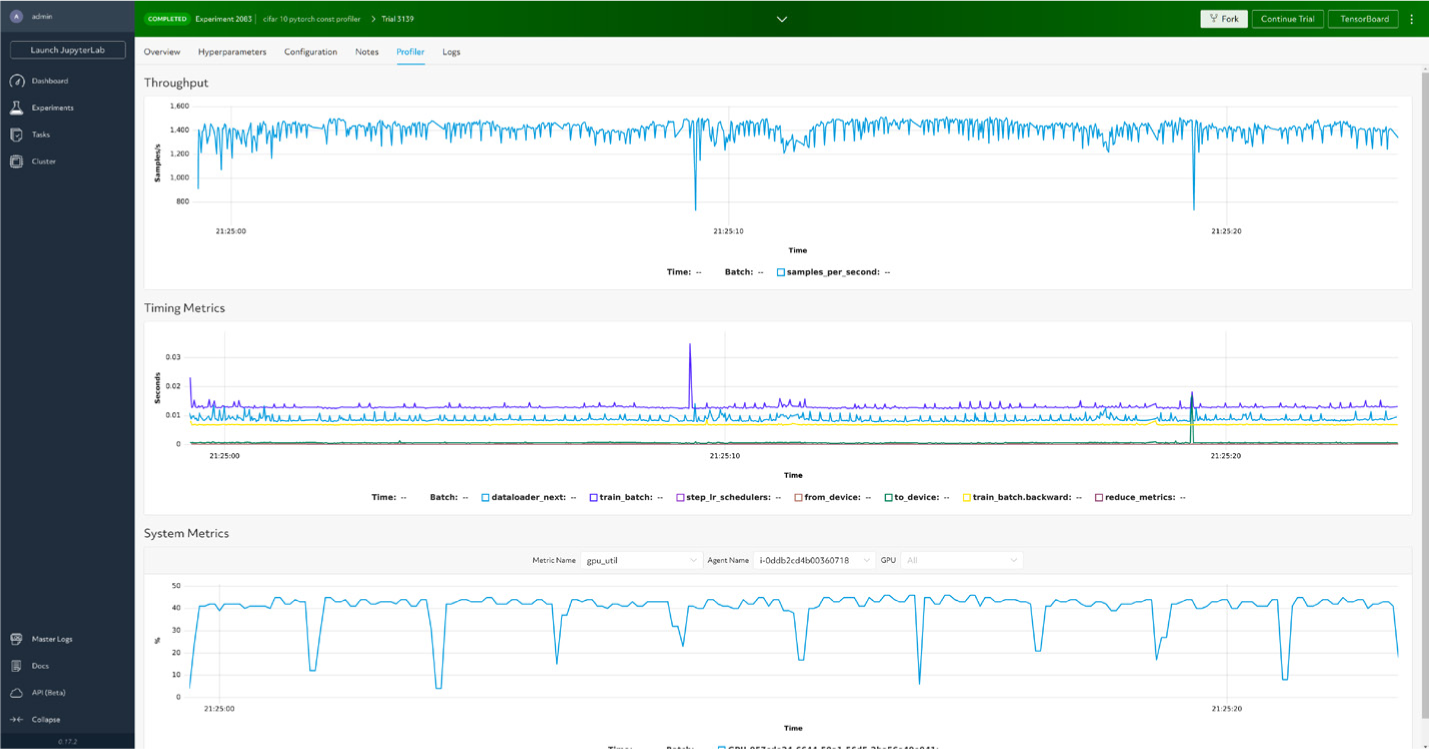
最新のハイパーパラメータチューニングを活用した高精度モデルの構築
MLの開発プロセスに欠かせないハイパーパラメータチューニングは、モデルの予測パフォーマンスを最大化するうえで重要な役割を果たします。ハイパーパラメータチューニングを実際に活用するには、分散型トレーニングやクラスタ管理など、重要なインフラストラクチャ機能が必要となります。HPE MLDEは、自動ハイパーパラメータ探索機能に加え、最新のチューニングアルゴリズムをサポートしているため、リソースを削減しつつ、短時間でより高精度なモデルを開発できます。
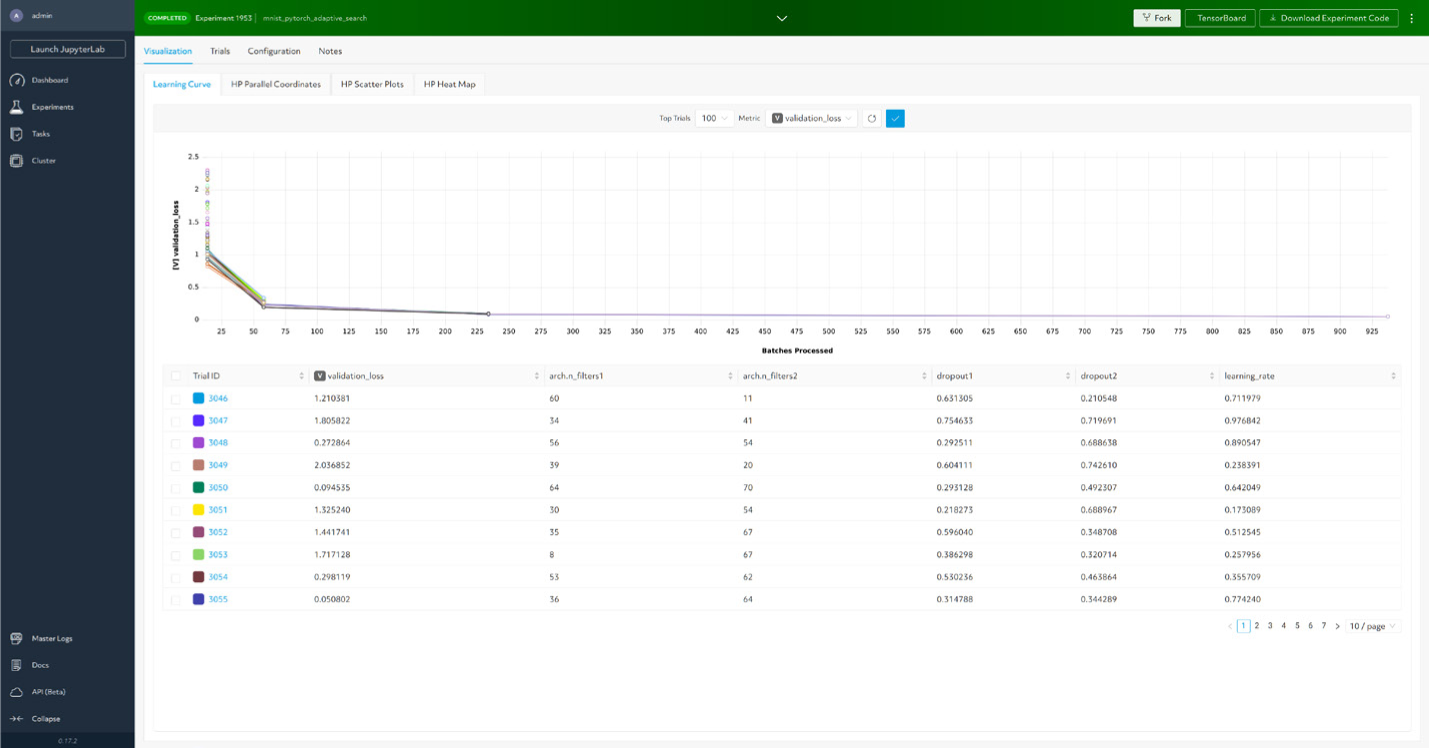
自動実験追跡で結果を分析
MLエンジニアによる結果の分析と再現をサポートするため、HPE MLDEは、実験管理機能に高度な可視化手法を組み合わせて活用しています。HPE MLDEでは、モデルコード、ライブラリ依存関係、ハイパーパラメータ、設定が自動で維持されるため、MLエンジニアは以前に実施された実験を簡単に再現できます。組み込みのモデルレジストリは、トレーニング済みモデルを追跡し、成功する可能性の高いバージョンや重要なバージョンを特定できます。拡大したMLチームでチームメンバーが簡単かつ迅速に共有、拡張できるようになります。こうしたツールの存在は極めて重要です。
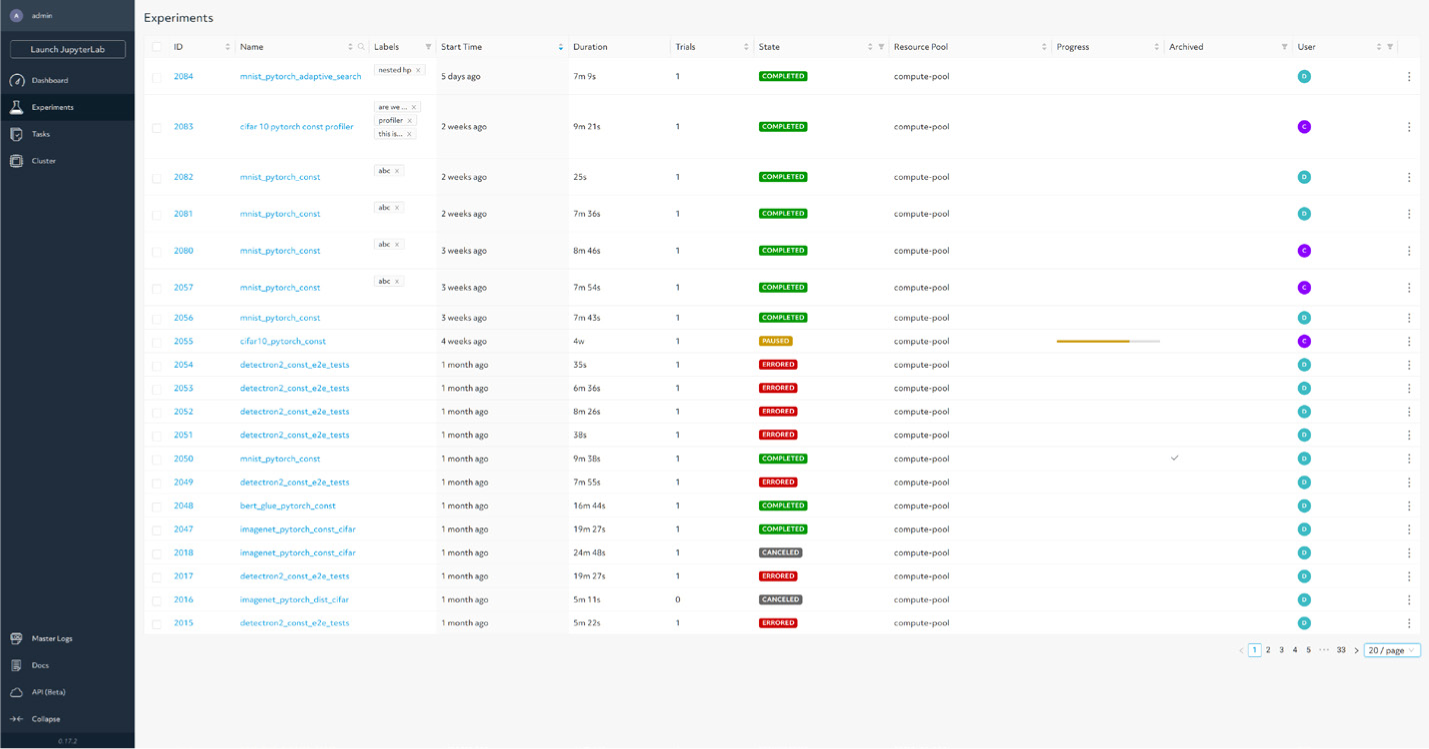
組み込みのリソース管理機能でさまざまなクラスタリソースを共有
HPE MLDEには、リソース管理機能が組み込まれており、オンプレミスまたはクラウドのクラスタ運用を簡素化してクラスタ稼働率を高めます。チームメンバーは、MLDE組み込みのクラスタスケジューラでフェアシェアや優先度設定を活用してジョブを投げることができます。KubernetesやSlurm、PBSなど異なるオーケストレーションツール、スケジューラと連携して動かすこともできます。HPE MLDEの組み込みスケジューラは、下記のような機能を提供する最高クラスのMLワークロードをサポートしています。
- ハイパーパラメータチューニングのスケジューリング
- 長期間実行されるジョブの一時停止と再起動
- 自動フォールトトレランス
- スポットインスタンスのシームレスな活用
- オンデマンドのインスタンス課金
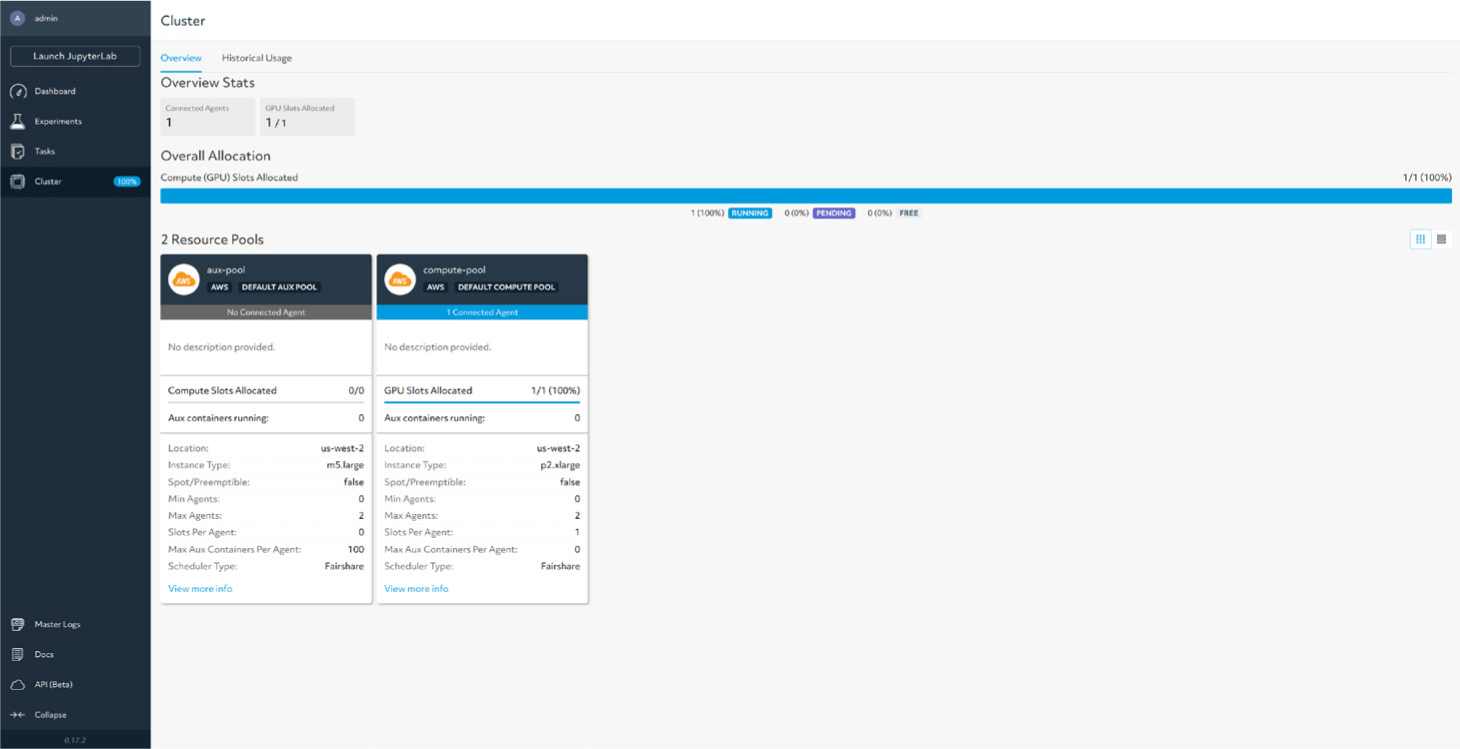
AIデータ サイエンティストが求めていたソリューションを実現
ビジネスの成長の機会を求めていくには、HPE MLDEは最適なソリューションです。AI、ML展開の拡張をサポートする、将来を見据えたプラットフォームを導入することで、エクサスケール時代のHPCをスムーズに運用しながら、ITリソースの統合によってMLモデル開発を簡素化し、関連コストも削減できます。
SCSKでは、GPUを搭載する各種AIサーバーを用意しています。
GPU性能を極限まで引き出したいなら…… NVIDIA DGXシリーズへ
[AI Server]トップに戻る…… NVIDIA AI対応GPU搭載サーバー
HPEの関連サイトは…… HPE Crayスーパーコンピューティング