No.27 『Corticon のルールシートでの条件の表記方法を検証する』
2018.05.25 Progress Corticon
本エントリーは株式会社アシスト様が寄稿したエントリー(https://www.ashisuto.co.jp/product/category/brms/progress_corticon/column/detail/brmstech27.html)を転載したものとなります。
|
|

2016年4月からProgress製品を担当しています棚橋浩志です。
さてこの技術コラムを4回書いてまいりましたが内容が難しい!とご指摘頂く機会も多いために今回は簡単なコラムに纏めてみたいと思います。
Corticonでは、Corticonという世界で、ある判断を行う処理をある程度自由に記述できるため、同じ判断でも記述する人によって微妙に異なる表現となることがあります。今回は、その条件文の書き方で2つの異なる記述方法について表現して違いを明らかにしたいと思います。設計をする際の開発方針決めの一つとしてお考えいただくことがあれば幸いです。
条件文の記述方法
語彙属性と設定値
| エンティティ名 | 属性名 | データ型 | 必須 | モード | 説明 |
| test | エンティティ名 | ||||
| _str | 文字列 | いいえ | 一過性 | 文字列型のワークエリア | |
| TGT_NUMERIC | 整数 | はい | ベース | 事前に定義される数字 | |
単純に文字列型の属性と整数型の属性があると考えて下さい。エンティティ名や属性名や必須およびモードの設定は無視して下さい。
この語彙を使用して下記ルールを実装してみましょう。
test.TGT_NUMERIC の値が 7 の場合には test._str には "SEVEN" という値を代入する。
test.TGT_NUMERIC の値が 7以外 の場合には test._str には "NOT SEVEN" という値を代入する。
このルールを記述する時に条件文の記述方法は下記の図の様に2通りあります。
|
|
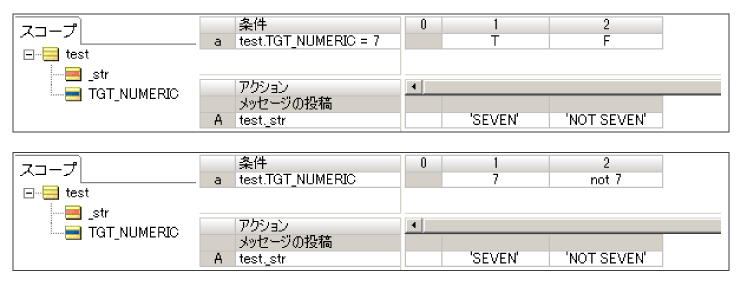
皆さんはどちらで記述しますか?ここでパフォーマンスという観点で検証してみましょう。言い換えればどちらの処理が早いか調べてみましょうという事です。
一般的に開発言語で記述するプログラムで使用する命令文の処理速度は、機械語に置き換えられた時の命令語が解析できる為にその命令語のサイクル数によっておおよその処理時間がわかります。 そのためこの命令文は早い、この命令文は遅いと客観的に判定出来ます。しかしCorticonではルールシートが最適化されるため、検証して確認するよりほかにありません。
しかしこの処理時間の比較は他の割り込み処理の要因が多いために一概に比べることも出来ませんし、命令語での数サイクル程度の違いは殆ど検出できないと思われますが、試行回数を増やしてみてその傾向を捉えてみたいと思います。
処理時間を計測するルールを作成する (拡張演算子作成)
Java7 で計測出来る一番小さな時間はナノ秒になり下記メソッドが使用出来ます。
long型 System.nanoTime()
このメソッドを使って拡張演算子を実装して速度計測のために使用します。拡張演算子の作成方法はNo.10 Corticonの【拡張演算子】と【サービスコールアウト】を使ったルール実装のしかた (2016年12月22日)または Corticonの『拡張演算子ガイド 第10章 拡張プラグインの作成』マニュアルに詳しく書かれていますのでご参考にして下さい。
以下作成した拡張演算子のjavaソースです。
public class Extended implements ICcStandAloneExtension
{
public static java.math.BigInteger getNanoTime()
{
long wlong = System.nanoTime();
return new java.math.BigInteger(Long.toString(wlong));
}
}
余談ですが Corticonはこの様な拡張性に優れていますので足らないメソッドはどんどん作成してパワーアップして下さい。
処理時間を計測するルールを作成する -1-
語彙属性と設定値
| エンティティ名 | 属性名 | データ型 | 必須 | モード | 説明 |
|---|---|---|---|---|---|
| test | エンティティ名 | ||||
| _end | 整数 | いいえ | 一過性 | 終了時のナノ秒 | |
| _nanotime | 整数 | いいえ | 一過性 | 計算されたナノ秒 | |
| _start | 整数 | いいえ | 一過性 | 開始時のナノ秒 | |
| _times | 整数 | いいえ | 一過性 | カウンター | |
| ave | デシマル | いいえ | ベース | 計算されたナノ秒の平均 | |
| max | デシマル | いいえ | ベース | 計算されたナノ秒の最大値 | |
| min | デシマル | いいえ | ベース | 計算されたナノ秒の最小値 | |
| TGT_NUMERIC | 整数 | はい | ベース | 事前に定義される数字 | |
| TIMES | 整数 | はい | ベース | 事前に定義される指定回数 | |
傾向をつかむために指定回数実行さて、平均値、最大値および最小値を取得させる目的で語彙を実装しています。
この語彙を使用してルールシートを作成します。
まずは初期化処理を実行するルールシートを作成します。
|
|

アクションA行では『カウンター』を0と設定しています。アクションB行では『計算されたナノ秒の平均』を0と設定しています。以上は0列目で初期化処理として実装します。
|
|
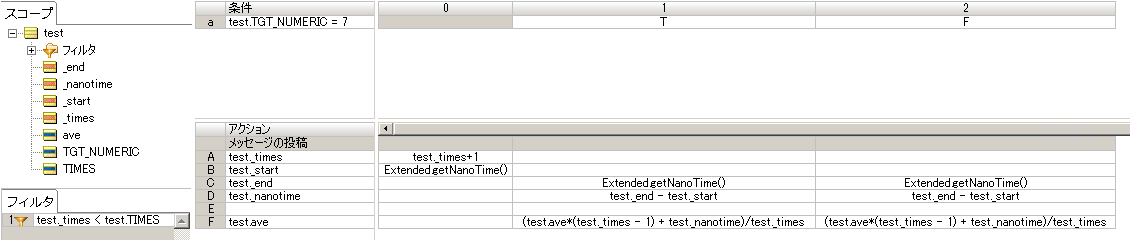
画像をクリックで拡大
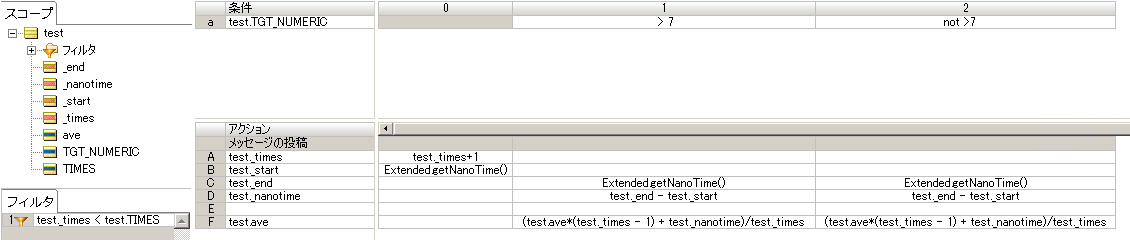
フィルターで『事前に定義される指定回数』の制限を設定しています。 条件分に入れると繁雑になりやすいのでファイルターに設定しました。 まずアクションA行では『カウンター』をインクリメントしています。 アクションB行では実装した拡張演算子を使用して『開始時のナノ秒』の値を取得しています。 以上は条件の0列目で初期化処理として実装します。
条件a行で test.TGT_NUMERIC が 7かどうかを T(true)/F(false) で判定しています。 しかしこのルールの目的は条件処理時間の計測なので、条件分岐後は同じ処理を設定しています。アクションC行では条件判定後の『終了時のナノ秒』の値を取得しています。測定したいのは分岐処理なのでこのような記述になりT(true)/F(false)共に設定しています。 アクションD行では test.nanotime に『計算されたナノ秒』を『終了時のナノ秒』と『開始時のナノ秒』差分を計算して代入しています。javaのSystem.nanoTime()は瞬間の値をナノ秒単位で取得するメソッドになるので差分を計算すると実時間が計算されます。 アクションD行では 『計算されたナノ秒の平均』としてtest.nanotime の平均を計算しています。 今回取得する値は数学でいうところの"十分大きい値"になるので、計算中にオーバーフローする可能性があります。 そこでオーバーフローを回避するためにこのような計算を定義しています。
計測目的からすれば不要かもしれませんが、計算されたナノ秒の最大値と最小値を保持するルールシートを作成します。
|
|
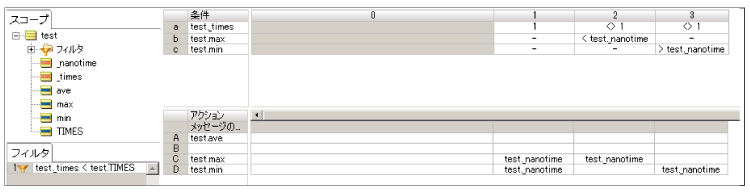
ルールフローで初期処理と測定処理を配置します。
|
|
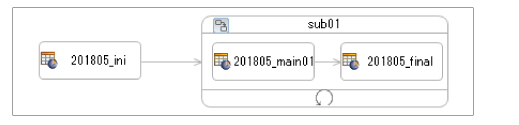
処理の順序があるために"接続"を使用しています。
ルールテストで測定してみましょう。
|
|
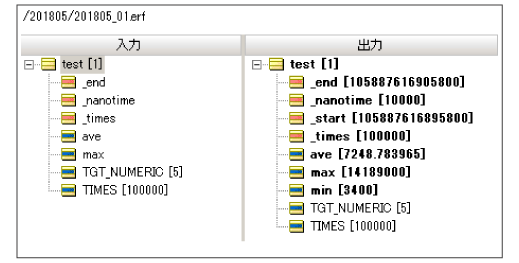
10万回試行した結果ですが最大値と最小値が4000倍にもなる位誤差が大きな値になりましたが、平均で7ミリ秒になりました。
処理時間を計測するルールを作成する -2-
同様に比較対象となるルールシートおよびルールフローを作成します。
|
|
画像をクリックで拡大
条件の記述方法が異なる以外すべて同じです。
|
|
ルールテストで測定してみましょう。
|
|
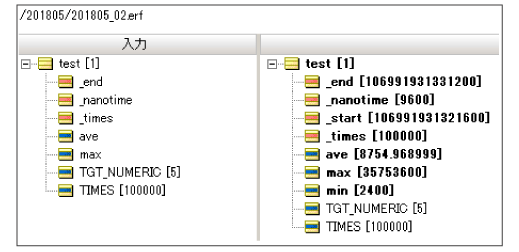
10万回試行した結果ですが最大値と最小値が15000倍にもなりましたが、平均で8.5ミリ秒になりました。
測定結果を考察する
私はこのルールを実装しながらきっと2-3倍の違いが出ると予想していましたが、何度も実行した結果はどちらかが大きな値になるという事はありませんでした。計測する単位が小さすぎて誤差が大きすぎる為に傾向がつかめないというところが正直なところです。
一方でルールシートのメンテナンス性という観点では、条件判定がT(true)/F(false)ではない方が、将来、2択ではない条件判定とすることも容易です。そして、T(true)/F(false)を使用しない方がCorticonの特性を利用した使い方といえると思います。Corticonはスプレットシートでルールを管理します。これは2択ではなく多選択に優れたルール定義方法よる恩恵になります。
