No.26 集合体(コレクション)データを操作する演算子たち
2018.03.30 Progress Corticon
本エントリーは株式会社アシスト様が寄稿したエントリー(https://www.ashisuto.co.jp/product/category/brms/progress_corticon/column/detail/brmstech26.html)を転載したものとなります。
|
|

今回は、Corticonが得意な集合体(コレクション)データを操作するコレクション演算子や、エンティティを操作するエンティティ演算子を紹介します。集合体と書きましたが同じ属性に異なるデータを保持するものの集まりのことで、コレクション演算子やエンティティ演算子は、その集合体のデータを集計したり、並べ替えて大小判断したり、存在確認したりする演算子のことです。
お題:ある車販売会社が所有する車両を、いくつかの条件で分類します。
<車両データ>
|
|
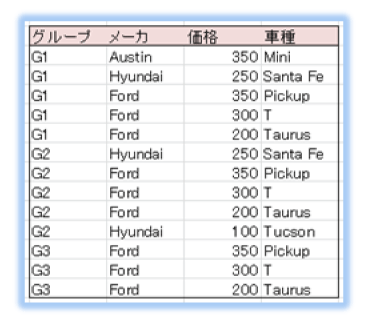
以下の条件に基づき、車両を分類します。
- 1.特定のグループにのみ存在するメーカと車種
- 2.全グループに共通して存在するメーカと車種
- 3.車両のメーカや車種は問わない各グループ内で一番値段が高い車両
<分類後のデータ>
|
|
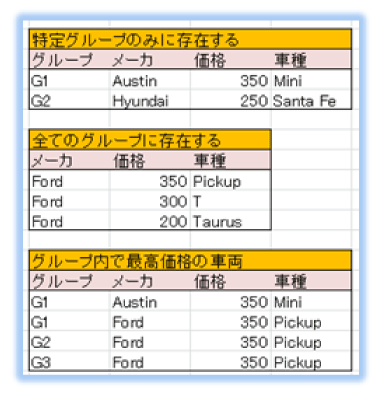
今回のサンプルでは、入力データと出力データは、構造化していない平面的な形式のデータを扱います。
入力データは1件の車両に所属するグループ、メーカ、価格、車種をもっています。
出力は条件で分類したデータのみに分けて返します。
|
|
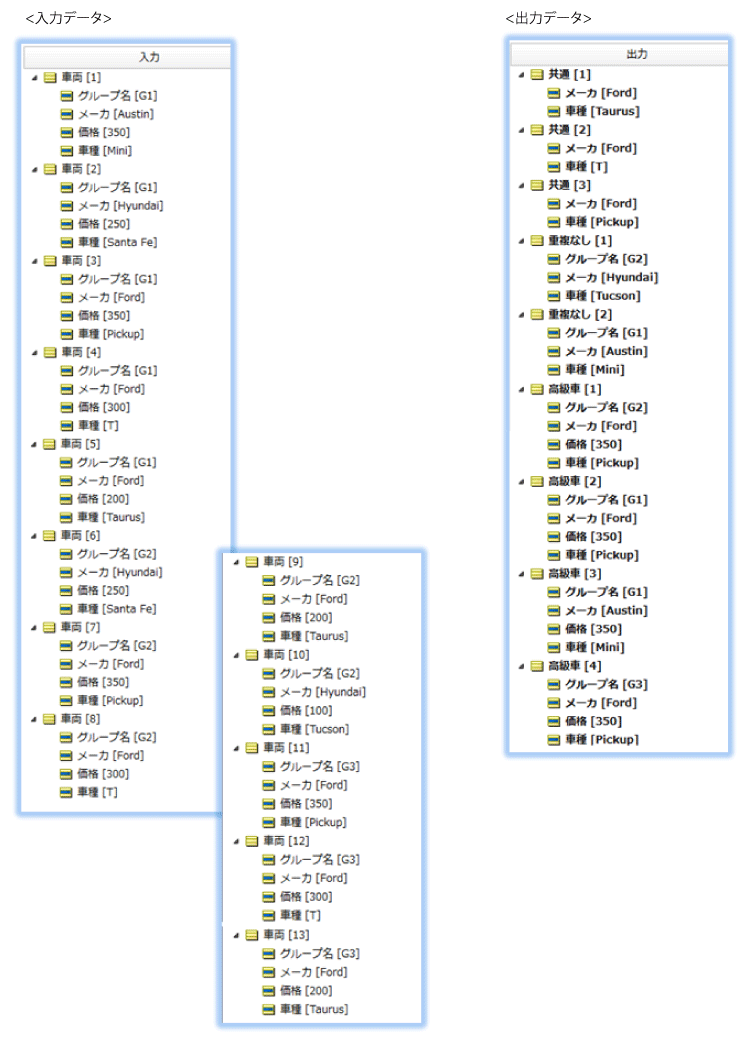
この要件に応える2つのルール実装例をとおして、コレクションデータを操作する様々な演算子をみていきましょう。
- ※本記事執筆時の環境:Corticon 5.6.1.15を使用しています。
【ルール実装例1】
語彙
入力データの車両エンティティと、出力のデータをセットする3種類(共通、高級車、重複なし)のエンティティを用意します。
これらエンティティ間に関連性はなく独立しています。
|
|

ルールフロー
大まかな流れを見てみましょう。
|
|
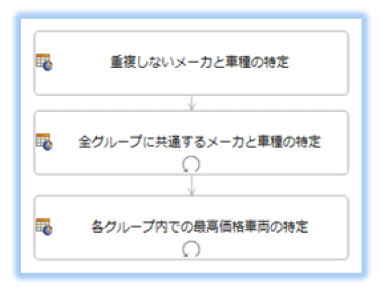
データを分類する3つの条件ごとに、ルールシートを分けます。
ルールシート
1. 重複しないメーカと車種の特定
特定のグループのみに存在する車両データ(メーカと車種)を探します。
|
|
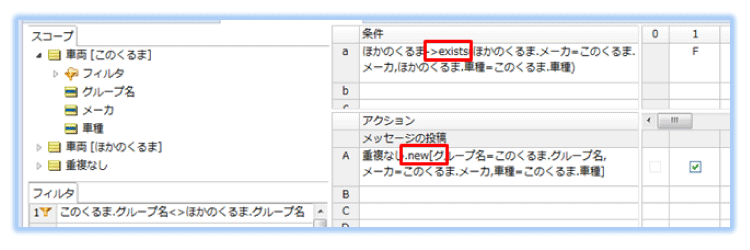
スコープ セクションに車両エンティティに対してエイリアスを2つ(このくるま、ほかのくるま)設定します。
フィルタ セクションで、今注目したい"このくるま"のグループ名とは異なるグループ名を持つ"ほかのくるま"をルールの対象とします。
条件「a」行で、集合(コレクション)データを処理する演算子 ->exists を使用して、エイリアス名"ほかのくるま"に"このくるま"と同じメーカと車種のデータが存在するかどうかを確認します。
条件「a1」列の結果、"ほかのグループ"に存在しなければ、アクション「A」行で重複なしエンティティを作成( .new )します。これで重複しない車両のリストが得られます。
2. 全グループに共通するメーカと車種の特定
全てのグループに存在する車両データ(メーカと車種)を探します。
|
|
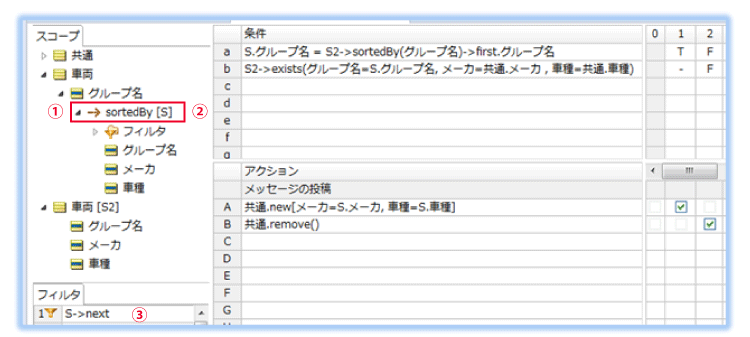
スコープ セクションで、コレクションを処理する演算子 ->sortedBy を使用して車両データをグループ名で並び替えし(①)、並び替え後のデータのエイリアスS(②)に特別な演算子 ->next を設定(③)します。この特別な演算子は、並び替え後のコレクションに対してのみ使用可能です。
さらに、ルールフロー上でこのルールシートに対してループを設定(④)します。
|
|
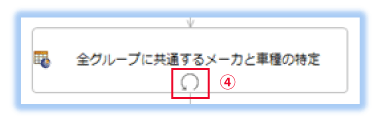
並び替え後のコレクションに対して->nextを指定し、ルールシート上でループの指定をすると、並び替え後のデータが内部的にキャッシュされます。
この例では、車両のグループ名ごとのデータ(グループ名G1のデータセット、G2のデータセット、G3のデータセット)が内部的に用意され、グループ名でのデータセットごとにルールの条件を評価します。
条件「a1」では、意味深に見えますが、1回目のルールシート実行時(グループ名G1のデータセット)に、当該グループ(グループ名G1のデータ)の車両データのメーカと車種で、共通エンティティを作成しています。
2回目以降のルールシート繰り返し処理(G2のデータセット、G3のデータセット)時には、1列目の条件は満たさず、2列目に入ります。条件「b2」で他のグループに同じデータの存在を確認し、他のグループに存在しない(全グループ共通ではない)ため、先に作成したエンティティを削除( .remove )します。
3. 各グループ内での最高価格車両の特定
今度は、グループ内で価格が最高値の車両(メーカと車種)を探します。
|
|
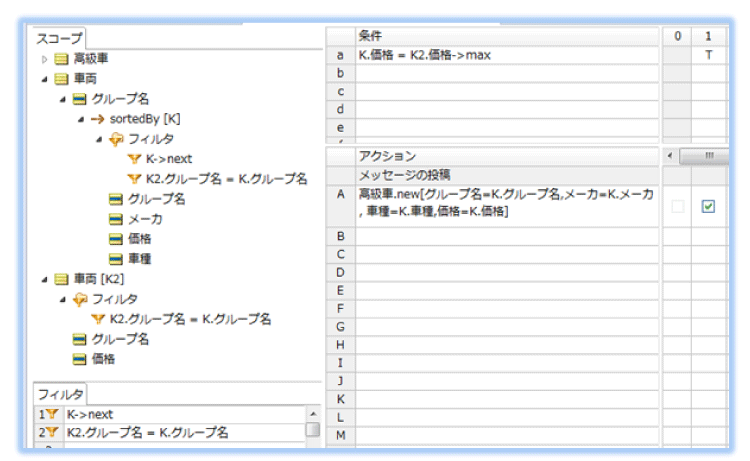
基本的な考え方、ルールの書き方は、前のルールシート「2. 全グループに共通するメーカと車種の特定」と同じです。
本ルールシートで違うところは、フィルタで処理の対象を同じグループ名で指定していることと、コレクション演算子 ->max を使用して、エイリアス名K2(同じグループ名の車両データ)コレクション内の最大値を求めているところです。
スコープセクションで ->sortedBy 、フィルタセクションで ->next 、ルールフロー上でルールシートに対して
ループの指定 をすると、sortedByで指定した項目で並び替え後のデータが内部的にキャッシュされ、その当該ルールシート内でコレクションとして処理することができます。
ちょっと変わった使い方ですね。慣れるまでは難しいかもしれません。
前述の入力データを使用して、ルール実装例1で作成したルールを実行し、期待する出力結果が得られることを確認してください。
次に、もう1つ、別のルール実装例を見ていきましょう。
【ルール実装例2】
今回の処理の場合、入力データ形式が「グループ」と「車両」エンティティとに分かれていて、関連性をもった構造化されたデータであれば、もう少しシンプルなルールで書くことができます。
しかし、今回 Corticon に渡されるデータは構造化されていません。
ということで、Corticonの中で①入力データをグループに分けて再編成(関連性を使用して構造化)したのちに、②データの集合体(コレクション)に対して条件に見合うデータを見つけることにします。
語彙
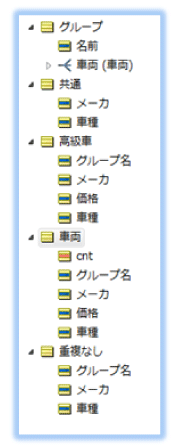
ここでは、入力データとして受け取る車両エンティティのほか、再編成に必要なグループエンティティと、条件で分類して出力するエンティティ(高級車、重複なし、共通)を用意します。グループエンティティと車両エンティティは、1:多の関連性を設定します。また、処理上一時的に必要な属性(cnt)も追加しています。
|
|
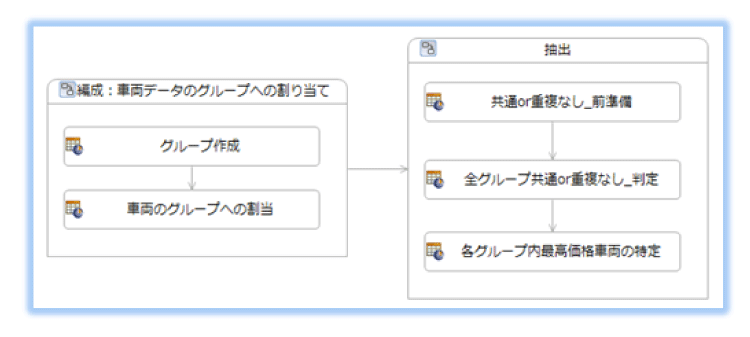
ルールフロー
前述のように2段階に分けます。
- ①入力データを再編成する(関連性を使用して構造化する)
- ②条件に合うデータを見つける
|
|
ルールシート
再編成 - その1:グループ作成
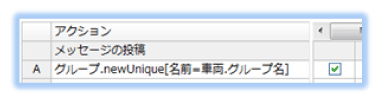
車両データのグループ名に基づくグループを、重複しないように新規に作成します。
|
|
再編成 - その2:車両のグループへの割当
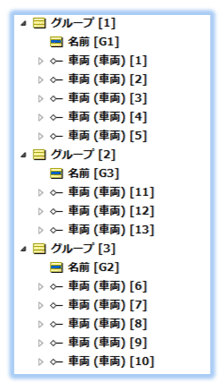
車両データのグループ名と、前のルールシートで作成したグループの名前とを比較し、等しい場合は当該車両をグループに関連付けます。
|
|

鳥の足跡のようなマークは1:多の関連性を示しており、1つのグループに複数の車両データが属していることを示しています。
車両データからみると、1つの車両データは1つのグループのみに属します。車両データは同時に複数のグループに属することができません。この「1:多」関連性では、車両データを他のグループに移動すると、移動前のグループから外れます。
再編成後のデータは以下のようになります。
|
|
抽出 - その1:共通or重複なし_前処理
グループAの車両(くるまA)のメーカと車種と等しいデータが、各グループ内の車両(グループB)に存在するかどうか、コレクション演算子 ->exists を使用して確認します。
|
|
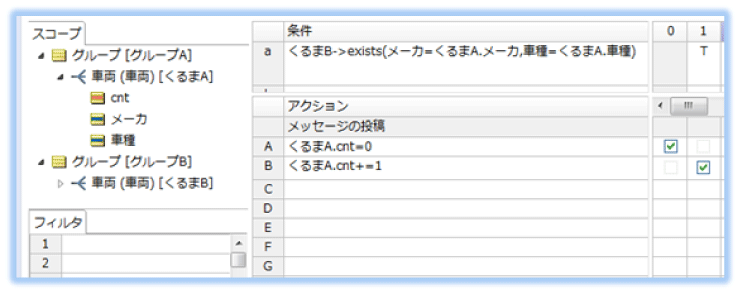
->exists 演算子は、自動的に当該グループ内のすべての「車両」に対してテストします。当該グループ内の各車両に対する繰り返し処理の指定は不要です。
グループBに、くるまAと同じメーカと車種の車両(くるまB)が存在する場合、カウントアップ「+1」しています。
これにより、同じメーカと車種の車両が「存在するグループ数」がわかります。
なお、フィルタを設定していないため比較対象として自分自身も含んでおり、このため必ず「1」は設定されます。
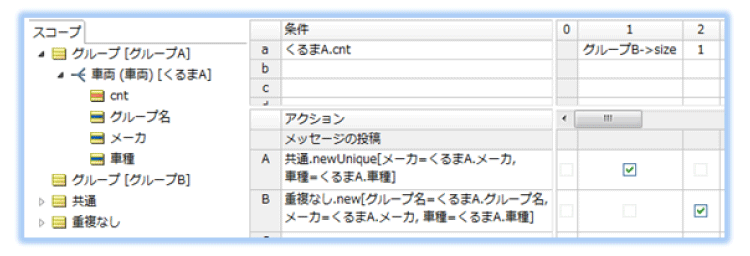
抽出 - その2:全グループ共通or重複なし_判定
コレクション演算子 ->size を使用して、コレクションの要素数を取得します。
このルールシートでも、フィルタを設定していないため比較対象として自分自身も含みます。
前のルールシートで取得したcnt(件数)を基に、全グループに存在する共通のデータか、または、他のグループに同じデータがないことを判定し、該当する出力用エンティティを作成します。
|
|
抽出 - その3:各グループ内最高価格車両の特定
グループ内の実際の車両とその価格に注目します。
|
|
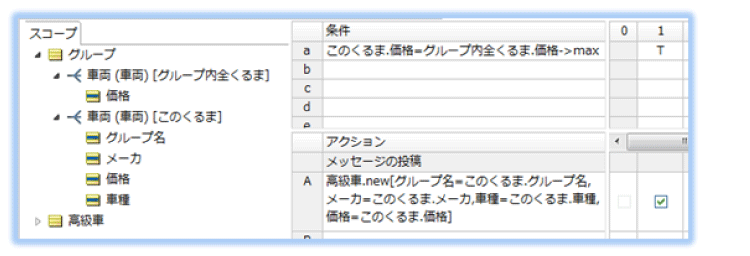
コレクション演算子 ->max を使用して、コレクション内の最大値を求めます。
"このくるま"の価格が、この車が属する"グループ内全くるま"の中で最大値と等しい場合に、該当するエンティティを作成( .new )します。
前述の入力データを使用して、ルール実装例2で作成したルールを実行し、期待する出力結果が得られることを確認してください。
なお、ルール実装例2では、条件で分類して出力する3種類のデータ(高級車、重複なし、共通)と併せて再編成後のグループデータも出力しています。
このグループデータを返したくない場合には、後処理として、グループエンティティデータを削除する( .remove )処理を追加するとよいでしょう。
まとめ
今回の記事では、Corticon の便利機能であるコレクションを操作する演算子について、2つの実装例を通して紹介しました。
コレクションとしてデータを操作する場合、構造化されたデータのほうがルールはとてもシンプルで分かり易く簡単になります。このためCorticon に渡す前に、構造化(関連性を設定した)データに整形することを検討してみてください。
とはいえ、構造化されていないデータであっても、上記2例のように、フラットなデータ形式のままでもコレクションとして処理できますし、また、Corticon の中でデータを構造化データに再編成してから処理することも考えられます。
読者の皆様のほうで、もっと簡単で分かり易いルールで書けましたら、是非、 弊社サポートセンター までご連絡ください。
ご連絡いただく際には、当コラムNo.26 と、お名前、ご連絡先を明記の上、ルールアセット一式とルールのポイント等々コメントを添えて頂けると嬉しく思います。
ご連絡いただいたルール実装例が集まりましたら、当コラム上で皆様と共有していきたいと考えております。
著者紹介
|
|
株式会社アシスト 情報基盤事業部 製品統括部プログレス推進部 |

