はじめに
こんにちは。SCSKの松谷です。SCSKに新卒で入社し、今年で2年目になります。
本連載では、ローカルLLM実装に向けた検証過程の具体的な作業内容や得られた知見を共有していきます。
第0回で記載したローカルLLM実装の手順は以下の通りでした。
- 1. CUDA Toolkit, NVIDIAドライバのインストール(第1回)
- 2. Dockerのインストール(第2回)
- 3. NVIDIA Container Toolkitのインストール(第3回)
- 4. OllamaによるローカルLLMの実行(第4回) ←今回はここ!
- 5. Ollama + Open WebUIによるローカルLLMの実行(第5回)
第4回の今回は、「Ollama」というソフトウェアを利用して、ローカルLLMを実行した際の内容などについて記載しています。
検証機のスペック
| 項目 | 説明 | |
|---|---|---|
| 1 | OS | Rocky Linux 8.10(Green Obsidian) |
| 2 | CPUコア数 | 8 |
| 3 | メモリ容量 | 32GB |
| 4 | ディスク容量 | 300GB |
| 5 | GPU | NVIDIA A100 PCIe 40GB |
Ollamaについて
Ollamaは、オープンソースな大規模言語モデル(llama3やgemma2など)をダウンロードし、ローカル環境で実行するための、オープンソースなCLI(コマンドラインインターフェース)ツールです。以下のように、Dockerのようなものだと考えると良いと思います。
- Dockerは、Docker Hubなどのリポジトリからイメージをダウンロードして、コンテナを実行する
- Ollamaは、Ollamaのリポジトリなどからモデルをダウンロードして、モデルを実行する
- Dockerでは、イメージのダウンロード:docker image pull イメージ名、イメージの実行:docker container run イメージ名
- Ollamaでは、モデルのダウンロード:ollama pull モデル名、モデルの実行:ollama run モデル名
Ollamaを利用することで、誰でも簡単にローカルLLMを利用することができます。今回はこのOllamaのDockerコンテナを利用して、ローカルLLMを実行します!
OllamaでローカルLLMを実行
Ollamaコンテナの実行
Docker Hubで「ollama」と検索し、一番上に表示されるものをクリックしてOllamaコンテナの実行方法を確認します。(イメージ名はollama/ollama)

確認した方法で、Ollamaコンテナを実行します。(第1回、第2回、第3回の作業が完了していることを前提としています。)
[root@aitest ~]$ docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
Unable to find image 'ollama/ollama:latest' locally
latest: Pulling from ollama/ollama
3713021b0277: Pull complete
f634e1e7c42b: Pull complete
2cdfb1178166: Pull complete
Digest: sha256:e3105b32922c6a5a1f1ff632c4da04580a569fe6df7f69949e97cb6630371f7d
Status: Downloaded newer image for ollama/ollama:latest
fb6e2190e344318500707798c18d5e9a1ef1ff62fd395319a1022be27e8dd9ba実行したコマンドである docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama の解釈は以下のようになります。
| 項目 | 説明 |
|---|---|
| docker run | コンテナを起動する |
| -d | コンテナをバックグラウンドで実行する |
| --gpus=all | すべてのGPUをコンテナに割り当てる |
| -v ollama:/root/.ollama | 「ollama」というボリューム領域をコンテナの/root/.ollamaディレクトリにマウントする |
| -p 11434:11434 | ホストマシンの11434ポートとコンテナの11434ポートを紐づける |
| --name ollama | 実行するコンテナの名前を「ollama」にする |
| ollama/ollama | コンテナイメージ「ollama/ollama」を指定する |
これでOllamaコンテナが起動され、ローカルLLMを実行する準備が整いました!
実行するモデルの選択
ローカルLLMを実行する準備が整ったので、次は実際に実行するモデルを決めたいと思います。
Ollamaでサポートされているモデルを以下公式サイトから確認します。
library(ollama.com)
今回は、Meta社が提供する「Llama3.1」を選択します。
Llama3.1は、8B,70B,405Bの3つのパラメーター数で提供されています。パラメーター数が多いほど性能が向上する傾向がありますが、多くの計算資源を必要とするため、今回は8BのLlama3.1を選択します。
[8b]を選択し、実行方法を確認します。
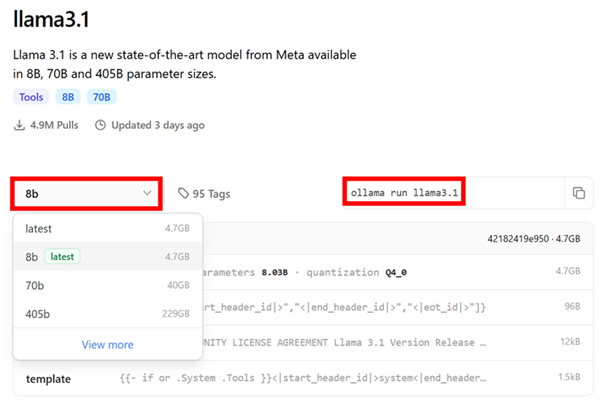
モデルの実行
起動したOllamaコンテナに接続し、モデルを取得・実行します。
[root@aitest ~]# docker container exec -it ollama /bin/bash
root@fb6e2190e344:/# ollama run llama3.1
pulling manifest
⋮
verifying sha256 digest
writing manifest
removing any unused layers
success
>>>
モデルのダウンロードが終了し、 >>> が表示されるとチャットを行うことができる状態です。チャット終了時は[Ctrl + d]を入力します。
>>> AIに関する知見を得るにはどうしたらいいですか?
以下のステップを参考にしてください:
1. **オンラインコースを受講**: Udemy、Coursera、edXなどのプラットフォームで提供されているAI関連のオンラインコースを受講してみましょう。学習コンテンツは豊富にあり、専門家によるレクチャーもあります。
2. **本を読む**: AIに関する本や論文を読んで知識を深めましょう。特にAIの基礎となる数学と統計学の知識が必要な場合は、関連する分野の研究論文を読むことが役立ちます。
3. **セミナー・ワークショップに参加**: AIに関するセミナーやワークショップには、アクティブなディスカッションや実践的なアプローチが多くあり、これは知見の獲得に非常に役立ちます。
4. **研究グループへの参加**: AIを専門とする研究グループへの参加も、最新のAIに関する情報と知識を取得するための良い方法です。研究者とディスカッションを行い、彼らが取り組んでいるプロジェクトについて学びましょう。
5. **オープンソースのライブラリやフレームワーク**: オープンソースのライブラリやフレームワークを使ってAIの実装を試みてみましょう。PyTorch、TensorFlow、scikit-learnなどは人気のあるライブラリです。
6. **関連する企業へのインターンシップまたはジョブ**: AIに関係する企業にインターンシップやジョブを受けてみましょう。これはAIに関する知識を実践的に活かすための良い機会です。
以上が、AIに関する知見を得るために利用できる方法です。
>>>Ctrl + d
root@fb6e2190e344:/#上記のようにチャットを行うことができました!
おわりに
今回は、第4回として「ローカルLLMの実行」に焦点を当て、紹介しました。
アイデアの壁打ちなどの用途で利用するには十分な精度と応答速度だったので、普段の業務でも積極的に活用していこうと思います!
(応答速度は搭載しているGPUの性能によりますが…)
Ollamaを利用してローカルLLMを実行する際の手助けになれば幸いです。
次回は、ローカルLLMをWebユーザーインターフェースを通して実行できるようにする方法などについて記載します。
お楽しみに!
次回(第5回)のコラムはこちら
著者プロフィール

松谷 康平(まつたに こうへい)
SCSK株式会社 インフラエンジニア
2023年に新卒で入社。現在はお客様のインフラ環境の構築を担当。
所属組織では、AI検証活動を積極的に行っている。
お問い合わせ・資料DL
NVIDIAソリューションに関するご相談や、各種資料ダウンロードはこちらから
