時間がかかる解析の効果を短時間で出すためのAI活用法
関連コンテンツ:ベイズ最適化のための手法と流れ

「ベイズ最適化」は、高価な評価コストを要する目的関数を安価に代数式近似する「サロゲートモデル」の上で、モデルの推定誤差を加味しながら最適解を高速に探索する「データ駆動型」のアプローチです。ベイズ最適化に関する概念的な話と応用事例については、既に筆者の技術コラム[時間がかかる解析の効果を短時間で出すためのAI活用法 第二回:サロゲートモデルとベイズ最適化, 第三回:ベイズ最適化の応用事例] で簡単に紹介しました。ここでは、ベイズ最適化のための手法に焦点を当てて、単目的そして多目的のベイズ最適化の流れを、これまでに筆者らが取り組んできた研究を交えて紹介します。
1.単目的ベイズ最適化
1つの目的関数 f (x) を最小化する設計変数 x の組み合わせ(最適解)を求める、単目的最適化問題を考えます。
ステップ1: サンプルデータの生成(実験計画法)
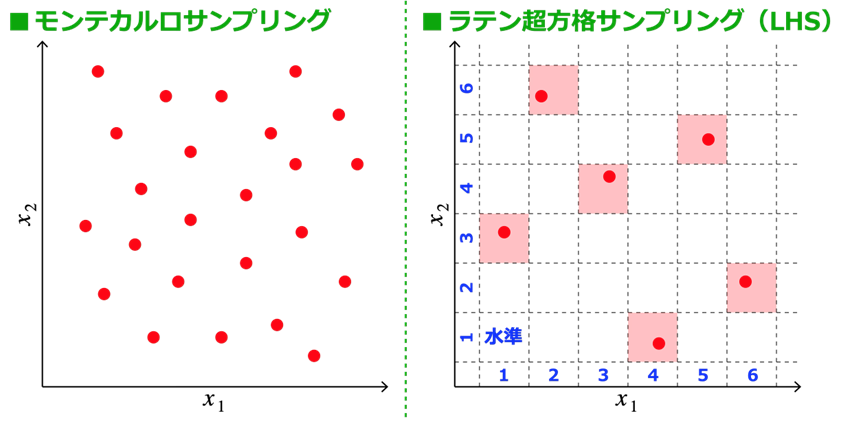
設計変数 x の異なる組み合わせにおいて、目的関数の真値 f (x) を評価(サンプル)します。この作業は「実験計画法(Design of Experiment: DOE)」とも呼ばれ、なるべく少ないサンプルデータで設計変数 x の空間全体を網羅することが理想とされます。サンプルをランダムに生成する方法(いわゆる「モンテカルロサンプリング」)に比べ、生成されるサンプルの直交性(すべての設計変数について、すべての水準が重複なく1回だけ選ばれる状態)を保証する「ラテン超方格サンプリング(Latin Hypercube Sampling: LHS)」[1]が理想的なDOEとして提案されています。
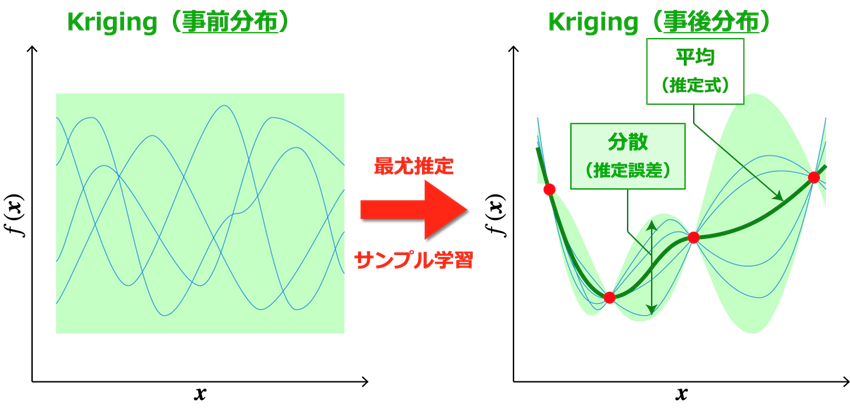
ステップ2: サロゲートモデル(Kriging)の構築
ステップ1で生成されたサンプルデータを学習することで、目的関数 f (x) を代数式近似したサロゲートモデルを構築します。ベイズ最適化では、サンプルデータに適合する確率過程をモデル化する「Kriging」[2] (「ガウス過程」[3]もほぼ同義)が使用されます。サンプルデータを学習する前の時点(事前分布)では、確率過程は明確な傾向を示さずにランダムに振る舞う無数のモデルの集合体に過ぎず、サロゲートモデルとしての体を成していません。そこで、「最尤推定」により、サンプルデータを最も正確に再現できる確率過程の状態(事後分布)を求めます。最尤推定は、サンプルデータの再現確率を最大化するように、モデルの形状を制御するパラメータを求める最適化問題を解くことで行われます。こうして求められた確率過程の平均は目的関数の推定式として、確率過程の分散は推定に含まれうる「不確かさ」(すなわち、推定誤差・エラーバー)を表す式としてそれぞれ導出されます。
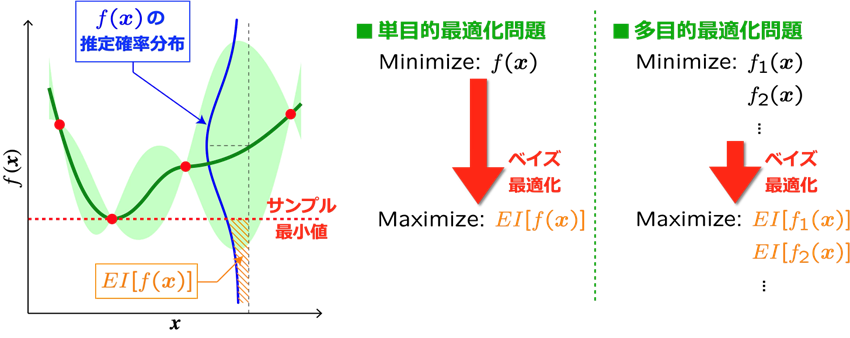
ステップ3: 獲得関数「EI」に基づく最適解の探索
ステップ2で構築されたサロゲートモデルには推定誤差が含まれるため、モデル上で求まる最適解は真の目的関数
f
(x)
の最適解と必ずしも一致しません。そこで、N点のサンプルデータを用いて構築されたサロゲートモデル上で求めた最適解
x*
において、目的関数の真値
f
(x*)
を評価した後、これをN+1 点目のサンプルデータとして追加します。そして、ステップ2に戻ってサロゲートモデルを更新し、その上で再度ステップ3の最適解を求めるという一連の手順を繰り返していきます。新たなサンプルデータ点を追加する場所を決めるための指標を「獲得関数」と呼びます。
ここでは、獲得関数として「改善期待量(Expected Improvement: EI)」[4]を紹介します。EIは、先述のKrigingで構築された確率過程の平均および分散の正規分布として定義される、目的関数
f
(x)
の推定確率分布の下で、これまでに取得したサンプルデータよりも目的関数
f
(x)
が改善する量を期待値として算出したものです。ベイズ最適化では、形が未知(ブラックボックス)である目的関数
f
(x)
を最小化する代わりに、既知(ホワイトボックス)のサロゲートモデルから算出される獲得関数EIを最大化する最適解
x*
を探索し、そこに新たなサンプルデータを繰り返し追加していきます。これにより、サロゲートモデルの推定誤差を減らすこと(大域的探索を担う「探索(Exploration)」)と、サロゲートモデル上でより良い解を見つけ出すこと(局所的探索を担う「活用(Exploitation)」)を同時に成し遂げることができます。
2.多目的ベイズ最適化
複数の目的関数
f1(x), f
2(x)
, …を最小化する最適解を求める、多目的最適化問題を考えます。
単目的と多目的のベイズ最適化の違いは主に、ステップ3で使用する獲得関数の定義に現れます。先述の獲得関数EIは、各目的関数について個別に算出することで、多目的最適化問題にそのまま応用できます。しかし、EIに基づくベイズ最適化は、多目的最適化問題において無数に存在するPareto最適解[時間がかかる解析の効果を短時間で出すためのAI活用法
第一回:ものづくりと最適化]の探索に偏り(すなわち、目的関数のトレードオフ情報に欠損)が生じがちであるという欠点があります。
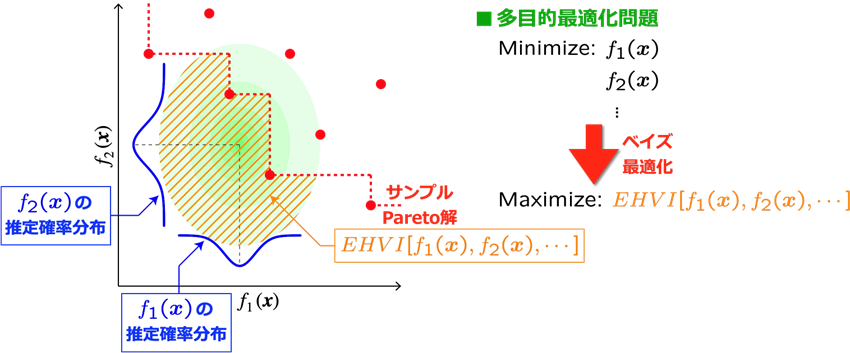
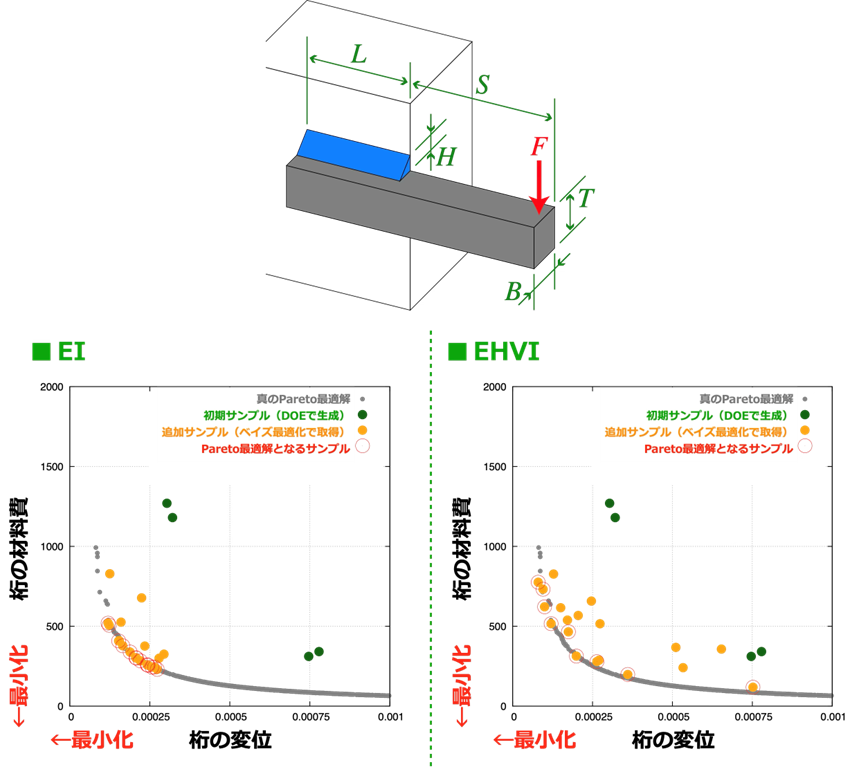
獲得関数「EHVI」
ここでは、多目的のベイズ最適化に特化した獲得関数として提案された「Expected Hypervolume Improvement: EHVI)」[5]を紹介します。EHVIは、これまでに取得したサンプルデータのうちPareto最適解となるものを基準として、改善期待量を複数の目的関数
f
1(x), f2(x)
, …の空間での超体積として算出したものです。
獲得関数「EPBII」
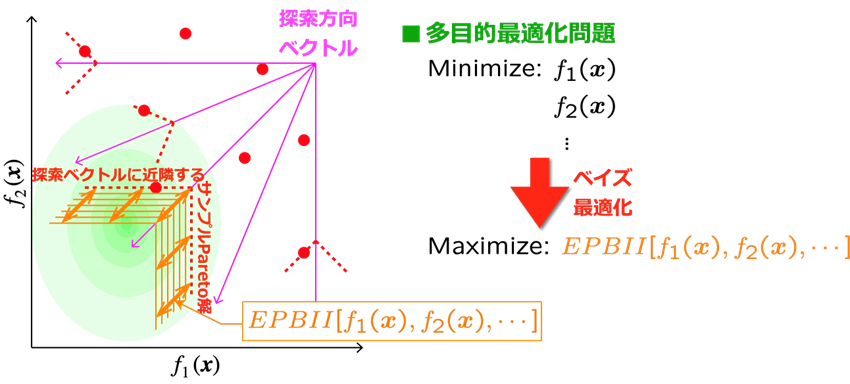
先述の獲得関数EHVIに比べて、Pareto最適解の探索の偏りを強制的に防ぐように、筆者らは独自の獲得関数「Expected Penalty-based Boundary Intersection Improvement: EPBII」[7]によるベイズ最適化手法を開発しました。EPBIIは、複数の目的関数
f
1(x), f2(x)
, …の空間内に探索方向ベクトルを複数かつ均等に配置し、各ベクトルに近隣するサンプルデータのうちPareto最適解となるものを基準として、改善期待量を各探索方向に沿う距離として算出したものです。目的関数空間を偏りなく覆う探索方向ベクトルの各々に沿ってPareto最適解の探索が促進されるため、実際の工学設計において有益な情報となる、目的関数のトレードオフの俯瞰的な理解が期待されます。
参考文献
最適化/機械学習による設計空間探索ソフトウエア pSeven Desktop
pSeven Desktopであらゆる設計リードタイムを短縮。煩わしい作業を削減し、CAD・CAE・データとプロセスを自動化します。pSeven Desktop独自のAIと強力な自動化エンジンによって、最適な設計条件を効率的に発見が可能です。
材料設計を加速させるAIプラットフォーム Citrine Platform
Citrine PlatformはAIを活用して製品開発を加速し、企業のR&D戦略を成功へと導くマテリアルズ・インフォマティクスソリューションです。AIモデルでの予測と実験を繰り返しながら最適解を目指すアプローチにより、少ない実験数で目標特性の達成を目指すことが可能です。