pSeven Desktop技術情報コラム第二回(ユーザー様向け)
構築・検証・探索 Part 2:モデルバリデーター

構築・検証・探索 Part 1では、pSeven Desktopのモデルビルダー機能を使用したモデルの作成方法について説明しました。スマートセレクションを用いたデフォルトのモデルビルダーでは自動で近似手法を選択しますが、パレート最適を決める複数の評価基準がある場合など、モデル品質のマニュアルでの検証が必要な場合もあります。どのモデルが最適かを分析し、選択するのはユーザーが判断することになります。
この記事では、モデル品質(予測性能など)や異なるモデル間の比較を行う対話型の分析ツールである、モデルバリデーターをご紹介します。この機能を使用することで、リファレンスデータに対するモデルの検証、エラープロットや統計データを使用して最も精度の高いモデルを見つけることができます。
1. モデル精度の可視化
モデルバリデーターではモデル精度を可視化手法として、”Plot”のプルダウンにて2種類のプロットが選択可能です。
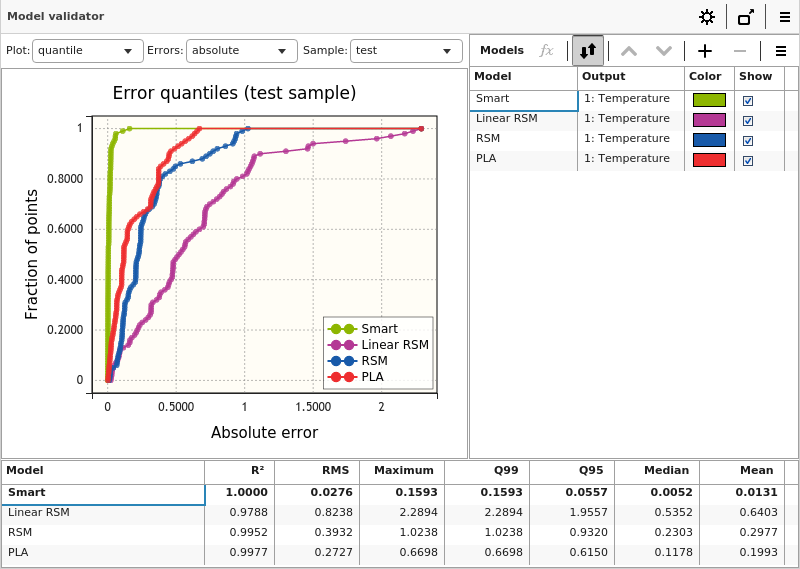
1つ目は分位数プロット(クォンタイルプロット)で、予測精度のエラー分布分析に使用できます。横軸の値よりもエラーが小さいサンプルの割合を、このプロットは示しています。直感的には、勾配が急であるほど(最高値付近で長く尻尾を引いているものほど)よいモデルである、と解釈できます。
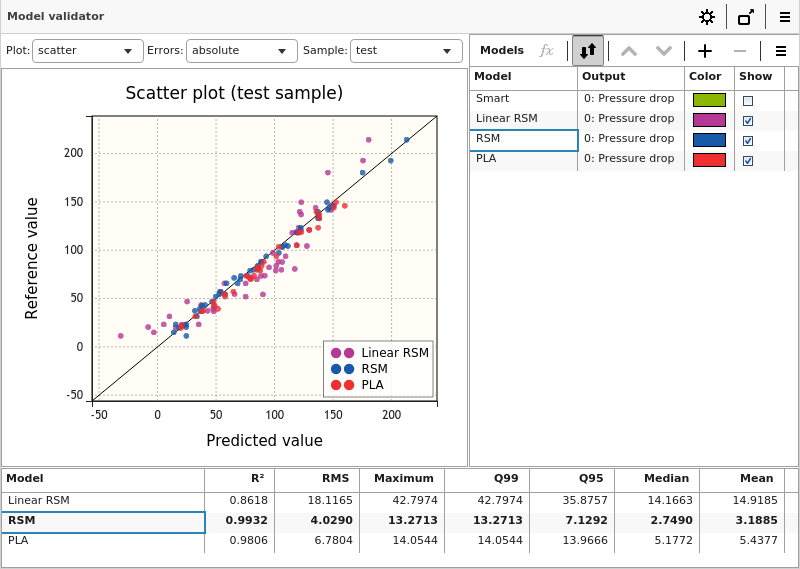
2つ目は散布図で、リファレンスサンプルとモデル予測の結果を直接比較します。特定のデータドメインにおけるエラーの程度や外れ値の確認に使用できます。
2. 絶対/標準予測誤差指標
デフォルトでは、分位数プロット(クォンタイルプロット)と誤差指標は絶対誤差の値で表示されますが、”Errors”で標準誤差(絶対誤差をリファレンスサンプル中の出力値の標準偏差で割ったもの)にも変更可能です。標準誤差は出力値の範囲の影響を無視した誤差の評価基準として使用可能です。
表示画面下部の表は予測誤差指標の一覧で、最も良いものは太字でハイライトされています。
- R2:決定係数、モデルが表現できる出力値の変化の比率
- RMS:平均二乗誤差
- Maximum:予測誤差の最大値
- Q99:下から99%の誤差の値、リファレンス中の99%のデータについて予測誤差はこの値以下になる
- Q95:下から95%の誤差の値、リファレンス中の95%のデータについて予測誤差はこの値以下になる
- Median:予測誤差の中央値
- Mean:予測誤差の算術平均値
R2(決定係数)が最も安定した指標で、1.0に近いほどよいモデルということになります。他の数値は小さいほど、よい予測であることを表します。
3. バリデーション用サンプルデータの選択
Sample”ではバリデーションに使用するリファレンスデータを変更可能です。
- “training”では、モデルのトレーニングサンプルを使用し、既知のデータに対する予測精度を評価します。
- “test”では、別に用意したテストサンプルを使用し、未知のデータに対する一般的な予測性能を評価します。
- “internal validation”では、クロスバリデーションによるモデル性能を評価します。
トレーニングサンプルによるバリデーションはモデルを過大評価する傾向があるため、可能であれば、テストサンプルを使用することを推奨します。トレーニングサンプルでのエラーが小さい場合(クオンタイルプロットで勾配が急な場合)、特に同じモデルのエラーが別のテストサンプルでは高いようであれば、過学習している危険性があります。テストデータが手に入らない場合には、インターナルバリデーションを選択することを推奨します。このデータはモデル構築中に行われるクロスバリデーションの結果と同じです。
構築・検証・探索 Part 3では、「モデルの中身」を見る方法を紹介し、対話型の可視化ツールであるモデルエクスプローラーによりモデルの挙動を探索していきます。
最適化/機械学習による設計空間探索ソフトウエア pSeven Desktop
pSeven Desktopであらゆる設計リードタイムを短縮。煩わしい作業を削減し、CAD・CAE・データとプロセスを自動化します。pSeven Desktop独自のAIと強力な自動化エンジンによって、最適な設計条件を効率的に発見が可能です。