No.5 Corticonの呼び出し方と処理速度について (大量データ処理インプロセス編) 【前編】
2016.09.14 Progress Corticon
本エントリーは株式会社アシスト様が寄稿したエントリー(https://www.ashisuto.co.jp/product/category/brms/progress_corticon/column/detail/brmstech05.html)を転載したものとなります。
|
|

|
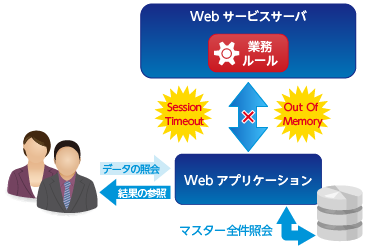
Corticonは、業務オペレーションを伴うオンライン処理はもちろん、バッチ処理による業務データの判定にも用いられる場合があります。しかし、大量なデータ処理を行うアプリケーションをWebサービス(SOAPもしくはREST)で実装した場合、Session Time OutやOut Of Memoryなどの致命的なエラーが発生する可能性があることは明らかです。今回は、そのような大量データの判定処理にエラーなく許容される時間内でCorticon Serverのデシジョンサービスを利用する方法について解説します。 |
|
大量データ処理の想定と検証
 |
|---|
例えば、「ある値が全データの上位10%の場合なんらかの処理を行う」というルールであれば、全データをルールに一括投入し上位10%に入っているかどうか判定する必要があります。そのデータがDBなどで管理されていれば、数十万件を超えることもあるでしょう。もちろんクライアントサイドでSQL文などを使用して対象データを絞り込んでおけば(上記の例ではあらかじめ上位10%のデータ)、対象データだけをルールに入力すれば良いので、そのような問題は回避できるでしょう。しかし、それでは本来BRMSで管理するはずだった「上位10%」といったルールが、クライアントサイドのSQLで実装されることになり、BRMSを利用するメリットが減少してしまいます。このような課題に対してCorticonではどのようなアプローチで解決するか、解決方法と処理速度を検証しました。
Corticonならではの手法
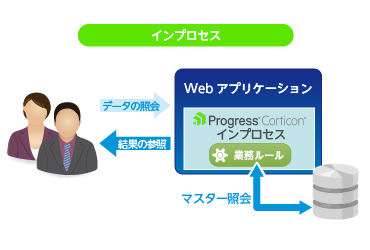
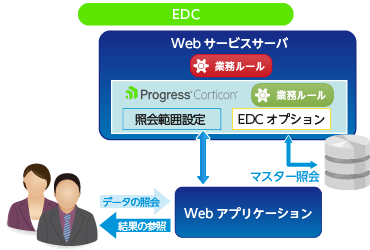
考えられる解決方法は、Webサービスを使用しない「インプロセス」という手法とさらにルールの中からデータベースを直接参照する「EDC」オプションを使用する方法があります。
 |
|---|
※ インプロセスについて
インプロセスとはCorticon Serverの利用方法の一種で、ユーザーが実装したJavaプログラムのプロセス内でCorticon Serverを実行する方法になります。Corticon Serverの最も一般的な利用方法はWebサービスでの利用ですが、インプロセスを利用すると、Webサービスで発生する様々なオーバヘッド(データの転送処理やパース処理)が無いため、高速に動作します。
|
※ EDCについて |
|
まずは、「インプロセス」という手法での処理速度を検証します。
検証環境
- CPU: 2.20 GHz * 2コア
- OS: Windows 7 Professional 64bit
- Corticon Server: 5.5.2.7
- Microsoft SQL Server 2012 Express
検証用のデータ
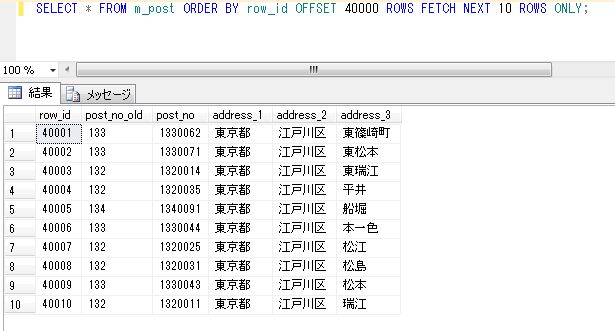
今回の検証では大量データのサンプルとして、日本郵便のサイトで配布されている郵便番号マスタ(約12万件)を使用します。このデータを、Microsoft SQL Server内のテーブル「m_post」に、インポートしました。つぎのイメージです。
(▼テーブル「m_post」のCREATE TABLE文)
CREATE TABLE [dbo].[m_post]( [row_id] [bigint] NOT NULL, [post_no_old] [varchar](255) NULL, [post_no] [varchar](255) NULL, [address_1] [varchar](255) NULL, [address_2] [varchar](255) NULL, [address_3] [varchar](255) NULL, CONSTRAINT [PK_m_post] PRIMARY KEY CLUSTERED ( [row_id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY]
(▼テーブル「m_post」の内容: 40001行-40010行を表示)
|
|
検証用の判定ルール
- ルールへの入力値は、郵便番号が含まれたユーザーデータと、日本全国の郵便番号情報12万件が入ったマスタデータ
- ユーザーデータの郵便番号とマスタデータの郵便番号を照会して、郵便番号として正しいかどうか、を判定する
- 郵便番号として正しかった場合、その住所が首都圏(千葉、東京、神奈川、埼玉)かどうか、を判定する
このルールで使用するシソーラス(階層語彙、データ構造体、Corticonにおける語彙)は、つぎのとおりです。
|
|
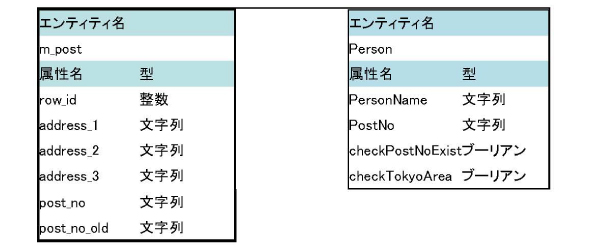
エンティティ「m_post」はSQL Server内のテーブル「m_post」と全く同じ構造で、テーブル「m_post」から取得したデータ12万件が入ります。
エンティティ「Person」にはユーザーデータが入り、「Person」内の属性「PostNo」に入っている郵便番号をルールで判定します。属性「checkPostNoExit」, 「checkTokyoArea」には判定結果が入ります。
検証用のシーソラス(語彙)とデシジョンテーブル(ルールシート)
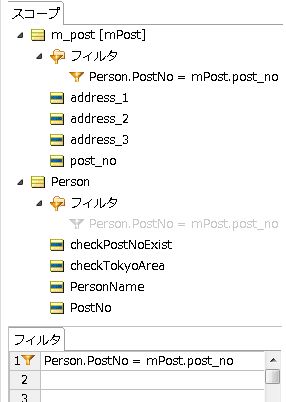
今回の検証で使用するルールはつぎのとおりです。
(▼スコープ)
|
|
(▼デシジョンテーブル)
|
|

(▼ルールステートメント)
|
|
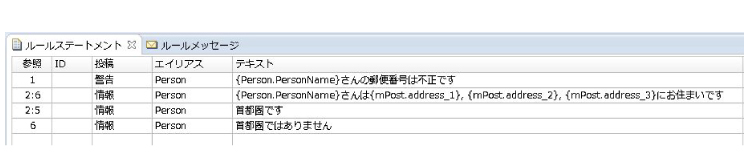
ルールのポイントは、スコープ画面のフィルタ部分です。Corticonでは、フィルタ機能を利用してデシジョンテーブルに入る前にデータ量を絞ると、処理速度が向上します。ここでは、「m_post」には郵便番号データ約12万件が格納されますが、フィルタで処理された結果、「Person」内の「PostNo」に一致した「m_post」のデータだけがデシジョンテーブルの処理に入ります。
インプロセスプログラムの作成
次にCorticon Serverを実行するJavaプログラムを作成します。
★メイン
package CorticonExecuteInProcess;
import java.util.ArrayList;
import com.corticon.eclipse.server.core.CcServerFactory;
import com.corticon.eclipse.server.core.ICcServer;
import com.corticon.service.ccserver.ICcRuleMessage;
import com.corticon.service.ccserver.ICcRuleMessages;
import java.sql.Connection;
import java.sql.Driver;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.Properties;
public class CorticonExecuteInProcess {
public static void main(String[] args) {
try {
// Corticon Server 開始
ICcServer iCcServer = CcServerFactory.getCcServer();
System.out.println(iCcServer.getDecisionServiceNames().toString());
// デシジョンサービスへのインプットデータ(Javaオブジェクト)
ArrayList<Object> colWorkObjs = getBusinessObjects();
// デシジョンサービス「Sample」を実行
long start = System.currentTimeMillis();
ICcRuleMessages Messages = iCcServer.execute("Sample", colWorkObjs);
long end = System.currentTimeMillis();
// 結果の表示
double millisec = end - start;
double sec = millisec / 1000;
System.out.println("処理時間: " + millisec + " millisecond, " + sec + " second");
for (int i = 0; i < 2; i++) {
Person p1 = (Person) colWorkObjs.get(i);
System.out.println("postNo: " + p1.getPostNo());
System.out.println("personName: " + p1.getPersonName());
System.out.println("checkPostNoExist: " + p1.getCheckPostNoExist());
System.out.println("checkTokyoArea: " + p1.getCheckTokyoArea());
System.out.println("");
}
for (int i = 0; i < Messages.getMessages().size(); i++) {
System.out.println(((ICcRuleMessage) Messages.getMessages().get(i)).getText());
}
}catch (Exception e) {
System.out.println(e.getMessage());
}
System.exit(0);
}
private static void insertPerson(ArrayList<Object>alBOs) {
Person p1 = new Person();
p1.setPostno("1020073");
p1.setPersonName("大塚辰男");
Person p2 = new Person();
p2.setPostno("1111111");
p2.setPersonName("ビルトッテン");
alBOs.add(p1);
alBOs.add(p2);
}
private static void insertPostMaster(ArrayList<Object>alBOs) {
try {
// SQL Server の「m_post」から全データを取得し、alBOsに格納
Driver d = (Driver) Class.forName("com.microsoft.sqlserver.jdbc.SQLServerDriver").newInstance();
String connUrl = "jdbc:sqlserver://localhost:1433;database=test;integratedSecurity=false;user=sa;password=Progress@win7";
Connection con = d.connect(connUrl, new Properties());
//String SQL = "SELECT * FROM m_post ORDER BY row_id OFFSET 0 ROWS FETCH NEXT 10 ROWS ONLY;";
String SQL = "SELECT * FROM m_post ORDER BY row_id;";
Statement stmt = con.createStatement();
ResultSet rs = stmt.executeQuery(SQL);
while (rs.next()) {
m_post oPost = new m_post();
oPost.setRow_Id(Integer.parseInt(rs.getString("row_id")));
oPost.setPost_No_Old(rs.getString("post_no_old"));
oPost.setPost_No(rs.getString("post_no"));
oPost.setAddress_1(rs.getString("address_1"));
oPost.setAddress_2(rs.getString("address_2"));
oPost.setAddress_3(rs.getString("address_3"));
alBOs.add(oPost);
}
rs.close();
stmt.close();
} catch (Exception e) {
e.printStackTrace();
}
}
private static ArrayList<Object> getBusinessObjects() {
try {
ArrayList<Object> alBOs = new ArrayList<Object>();
insertPerson(alBOs);
insertPostMaster(alBOs);
return alBOs;
} catch (Exception e) {
System.out.println(e.getMessage());
return null;
}
}
}
★語彙クラス
package CorticonExecuteInProcess;
public class m_post {
private Integer row_id = null;
private String post_no_old = null;
private String post_no = null;
private String address_1 = null;
private String address_2 = null;
private String address_3 = null;
public long getRow_Id() {
return row_id;
}
public void setRow_Id(Integer al_row_id) {
row_id = al_row_id;
}
public String getPost_No_Old() {
return post_no_old;
}
public void setPost_No_Old(String as_post_no_old) {
post_no_old = as_post_no_old;
}
public String getPost_No() {
return post_no;
}
public void setPost_No(String as_post_no) {
post_no = as_post_no;
}
public String getAddress_1() {
return address_1;
}
public void setAddress_1(String as_address_1) {
address_1 = as_address_1;
}
public String getAddress_2() {
return address_2;
}
public void setAddress_2(String as_address_2) {
address_2 = as_address_2;
}
public String getAddress_3() {
return address_3;
}
public void setAddress_3(String as_address_3) {
address_3 = as_address_3;
}
}
このプログラムは、Corticon ServerのコアライブラリとSQL ServerのJDBCドライバを参照設定しています。また、インプロセスのプログラムの場合、語彙クラスを自作する必要がある点に注意してください。メインプログラムの内容は、プログラム内のコメントでも簡単に記述していますが、全体の流れとしてはm_postオブジェクトにDB内の全件データを格納し、デシジョンサービスを実行しています。
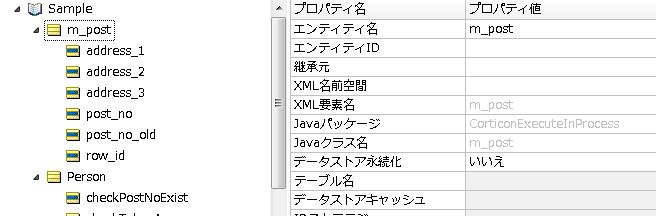
このプログラムをエクスポート(コンパイル)したJARファイルを作成します。次に、作成したJARファイル内の語彙クラスとルールの語彙ファイル(ecore)をマッピングする設定を行います。Corticon Studioの語彙編集画面で、メニューの「語彙」-「Javaオブジェクトメッセージング」-「Javaクラスメタデータのインポート」で、作成したJARを設定すると、自動的に作成した語彙クラスと各属性のget/setメソッドが語彙に設定されます。
(設定後の語彙編集画面)
|
|
|
|
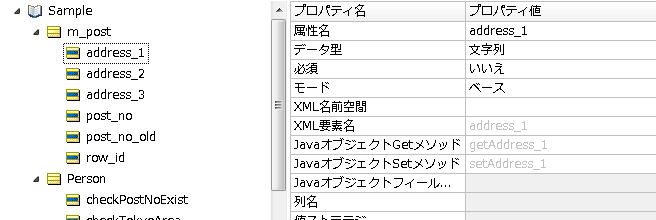
語彙のマッピング設定のあと、ルールフローのコンパイルとデプロイを行います。コンパイルにはCorticon Server付属の「Deployment Console」を使用しますが、「Deployment Console」実行時のCLASSPATHに、作成したJARファイルを追加してください。例えばコンパイルしたJARをSample.jarとしてデスクトップに保存しているときはつぎのようになります。
(<Deployment Consoleフォルダ>\bin\deployConsole.bat に以下を追加)
set CORTICON_CLASSPATH=%CORTICON_CLASSPATH%;C:\Users\progress\Desktop\Sample.jar
Deployment ConsoleでコンパイルしたEDSファイルを作成したら、Corticon Serverにデプロイします。デプロイ方法はWebサービス経由、CDDファイル、API経由など、いづれの方法でも問題ありません。
インプロセスプログラムの実行
ルールをデプロイ後、メインプログラムを実行します。実行時にデプロイしたルールを読み込むためにJavaの起動オプションとして「-DCORTICON_SETTING=SER -DCORTICON_WORK_DIR=<cortcon_work_path>」を指定します。
インプロセスプログラムの実行結果
実行結果はつぎのようになります。
Starting Progress Corticonサーバ : 5.5.2.7 -b7551 Progress Corticonサーバ CcServerSandbox location : C:/CcServerWork/SER/CcServerSandbox Loglevel : INFO Logpath : C:/CcServerWork/logs [Sample, test, test2] 処理時間: 4859.0 millisecond, 4.859 second postNo: 1020073 personName: 大塚辰男 checkPostNoExist: true checkTokyoArea: true postNo: 1111111 personName: ビルトッテン checkPostNoExist: false checkTokyoArea: false ビルトッテンさんの郵便番号は不正です 大塚辰男さんは東京都, 千代田区, 九段北にお住まいです 首都圏です
処理時間には誤差があるものの、おおよそ「5秒」前後です。
同様のプログラムをWebサービス(SOAP/REST)として作成し12万件のリクエストを実行してもSession Time Outして結果が返ってきません。それと比較すると、かなり高速に処理されていることがわかります。
さいごに
次回は、ルール内から直接外部のデータベースを参照することが可能な「EDC」オプションを検証します。
著者紹介
|
|
情報基盤事業部 製品統括部プログレス推進部 |

