PrometheusとSysdigを使用したAWS Lambdaのモニタリング
この投稿では、Sysdig Monitorを使用してAWS Lambdaを効果的に監視する方法を紹介しています。
サーバーレスコンピューティング、特にAWS Lambdaの重要性が増していることを背景に、Sysdigを介した監視の重要性を強調しています。
Prometheusと組み合わせることで、ユーザーはAWS CloudWatchからメトリクスを収集し、Sysdigで統合的に監視できるようになります。
具体的には、yet-another-cloudwatch-exporterを使用してCloudWatchメトリクスをPrometheus形式で取得し、これをSysdigに取り込む方法を詳細に説明しています。
IAMポリシーや認証情報の設定、エクスポーターのデプロイメント、必要なメトリクスの選択と設定方法が解説されています。
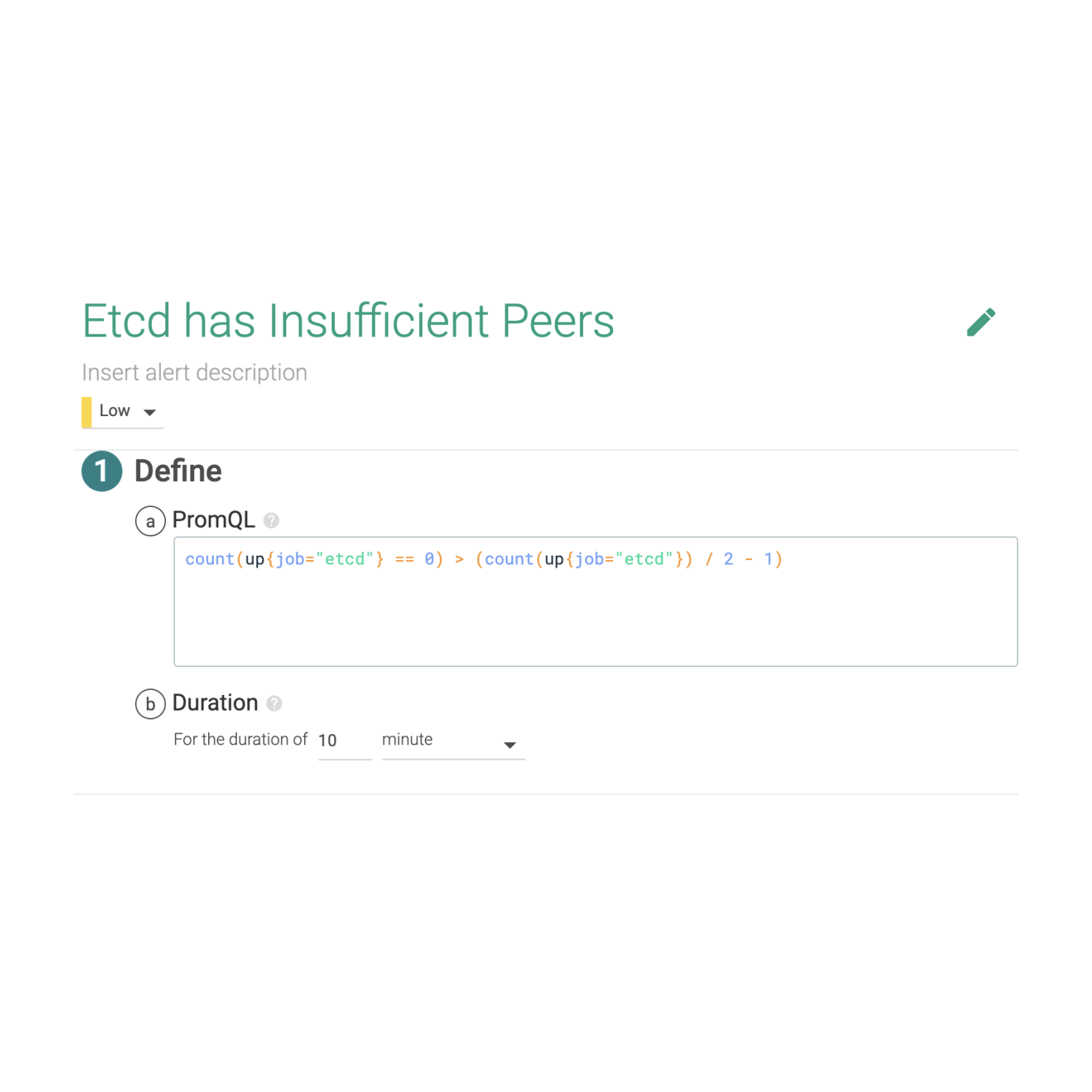
また、監視すべきAWS Lambdaの主要なメトリクスと、潜在的な問題を特定するためのアラート設定例も提供されています。
最終的に、このプロセスを通じてAWS Lambdaの監視を簡単かつ効果的に行う方法を示しています。