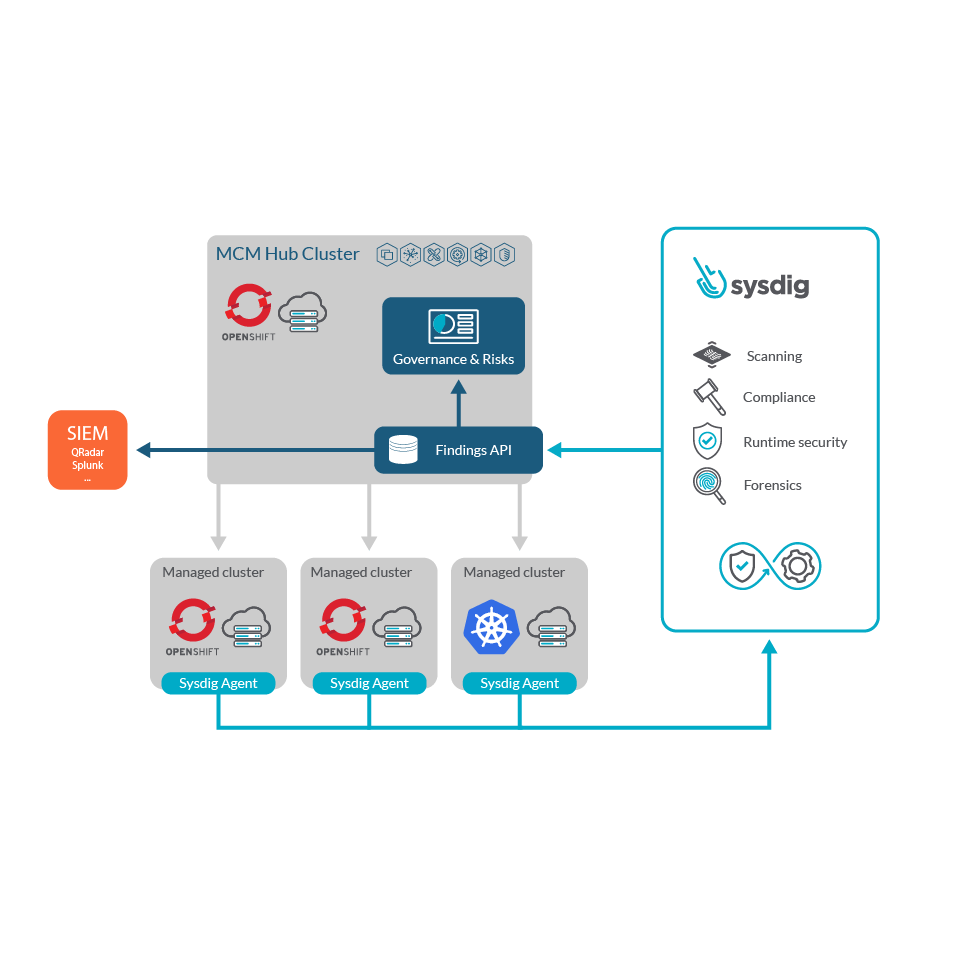
Kubernetes OOMおよびCPUスロットルのトラブルシューティング方法
KubernetesでのOutOfMemory(OOM)キルは、リソース管理の課題によって引き起こされる一般的な問題です。ポッドのメモリリミットを超えると、システムはOOMセーフガードを起動し、プロセスを強制終了します。Kubernetesのevictionポリシーは、ノードのメモリが少なくなるとポッドを停止させ、他のノードで再スケジュールします。また、コンテナが設定されたメモリリミットを超えると、コンテナは終了し、ポッドが再起動されます。
CPUリソースに関しては、コンテナがCPUリミットを超えて使用しようとすると、CPUスロットリングが発生しますが、コンテナが強制終了されることはありません。CPUリクエストはシェアシステムを使用して管理され、リミットはCPUクォータシステムで管理されます。リソースの使用量を適切にモニタリングし、リミットとリクエストを適切に設定することで、Kubernetes OOMキルやCPUスロットリングを回避し、クラスター内のアプリケーションのパフォーマンスを向上させることができます。
詳細はこちら