Kubernetes監視のベストプラクティスに注目することは、効率性、自動化、セグメンテーションの利点を最大限に活用する上で重要です。
Secure DevOps、またはDevSecOpsは、開発から本番までセキュリティと監視を統合し、高性能なアプリケーション提供を可能にします。
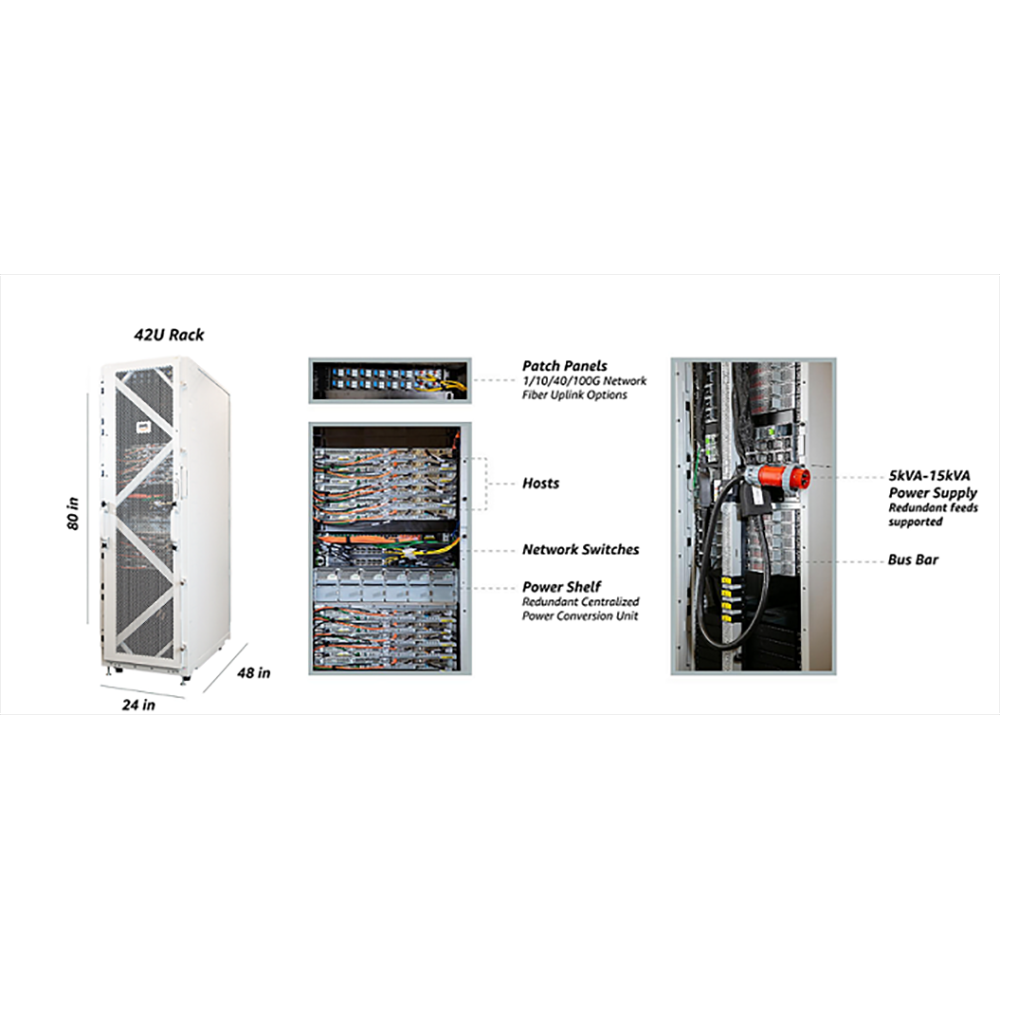
Kubernetesの監視は、コンテナの一時的な性質とブラックボックスの問題により、特に挑戦的です。
適切なツールとベストプラクティスに従えば、この課題を乗り越えることができます。
ベストプラクティスには、深いシステム可視性の追求、インストルメント戦略の評価、履歴データの取得、Kubernetesのコントロールプレーン検査、メトリクスとイベントの相関、ダッシュボードとアラートの利用、SaaSベースの監視ソリューションの選択が含まれます。
これらの実践は、可視性とセキュリティを強化し、トラブルシューティングとシステムの健全性の問題の解決を容易にします。