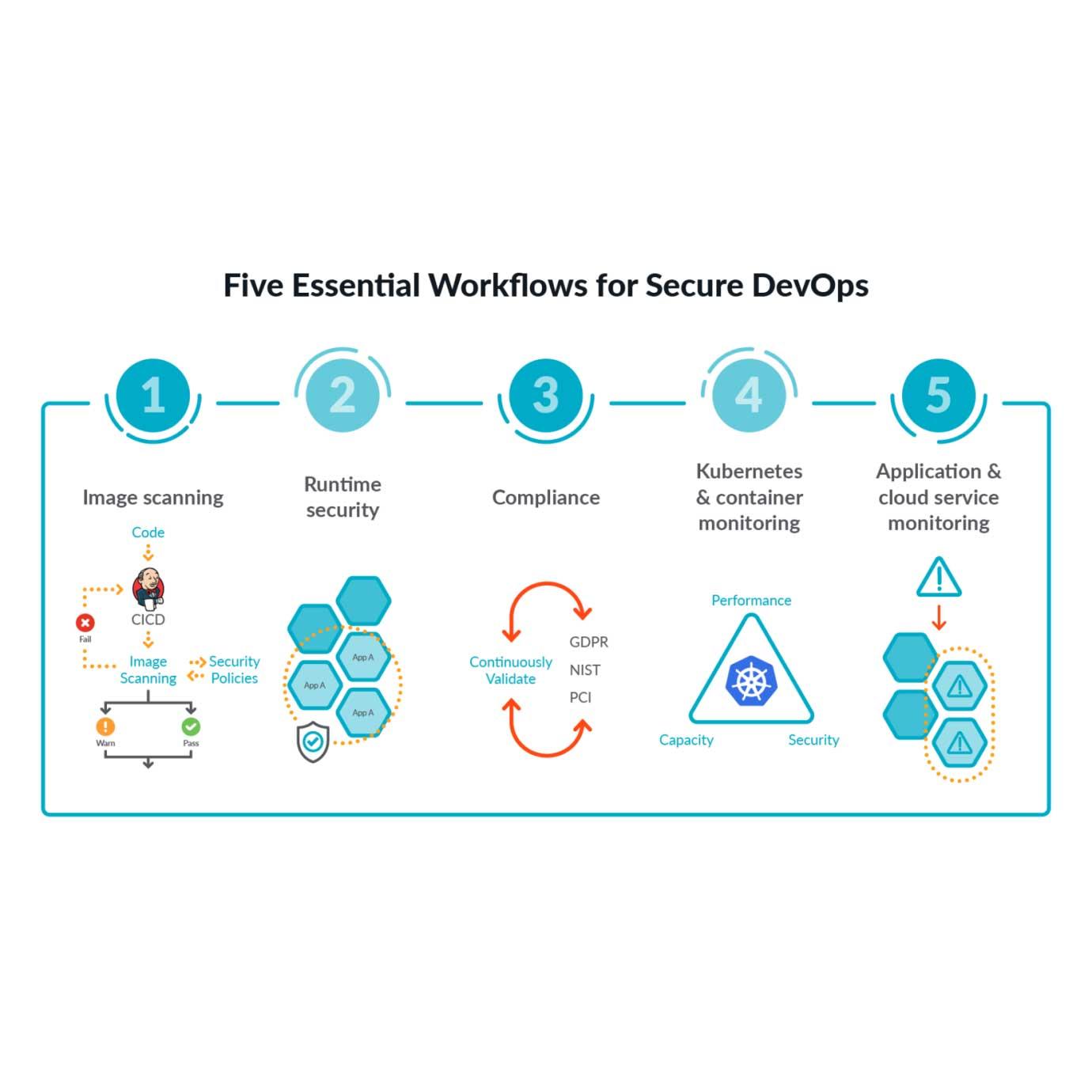
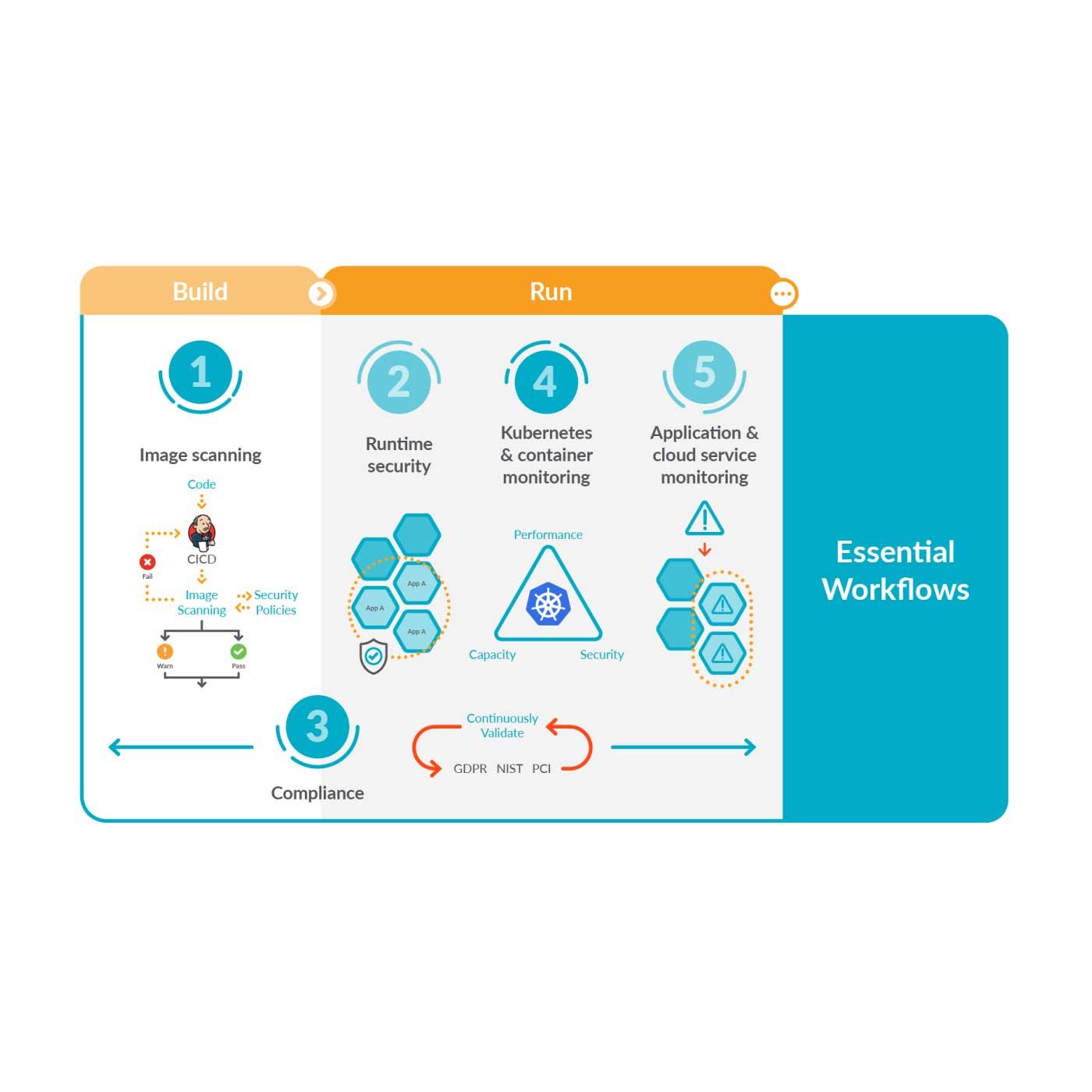
Prometheusを使ったインストルメンテーションアプリケーションの紹介
開発者がPrometheusを使用してアプリケーションのメトリクスをグラフ化する過程は初見では困難に思えるかもしれませんが、基本的なステップに分けて考えることで簡素化できます。
まず、アプリケーションがHTTP経由でPrometheusメトリクスを公開するよう設定します。
例えば、JavaアプリケーションではHTTPServerをインスタンス化してポート8000で実行するだけです。
その後、Prometheus設定ファイルに適当なスクレイプ設定を追加して、メトリクスを収集します。
このプロセスを通じて、デバッグに役立つJVMメトリクスなどの様々な基本メトリクスをリアルタイムで視覚化できるようになります。
さらに、自分の関心事を反映するカスタムメトリクスを簡単に追加でき、これらのメトリクスを利用してアプリケーションのパフォーマンスや挙動をより深く理解するためのグラフを作成できます。
このプロセスは、デスクトップでの小規模な実験から、組織全体での冗長性と可用性の高いモニタリングシステムの実装に至るまで、スケールアップ可能です。