PrometheusとSysdigを使用したAWS Fargateのモニタリング
この記事では、Sysdig Monitorを使用してAWS Fargateを監視する方法を紹介しています。
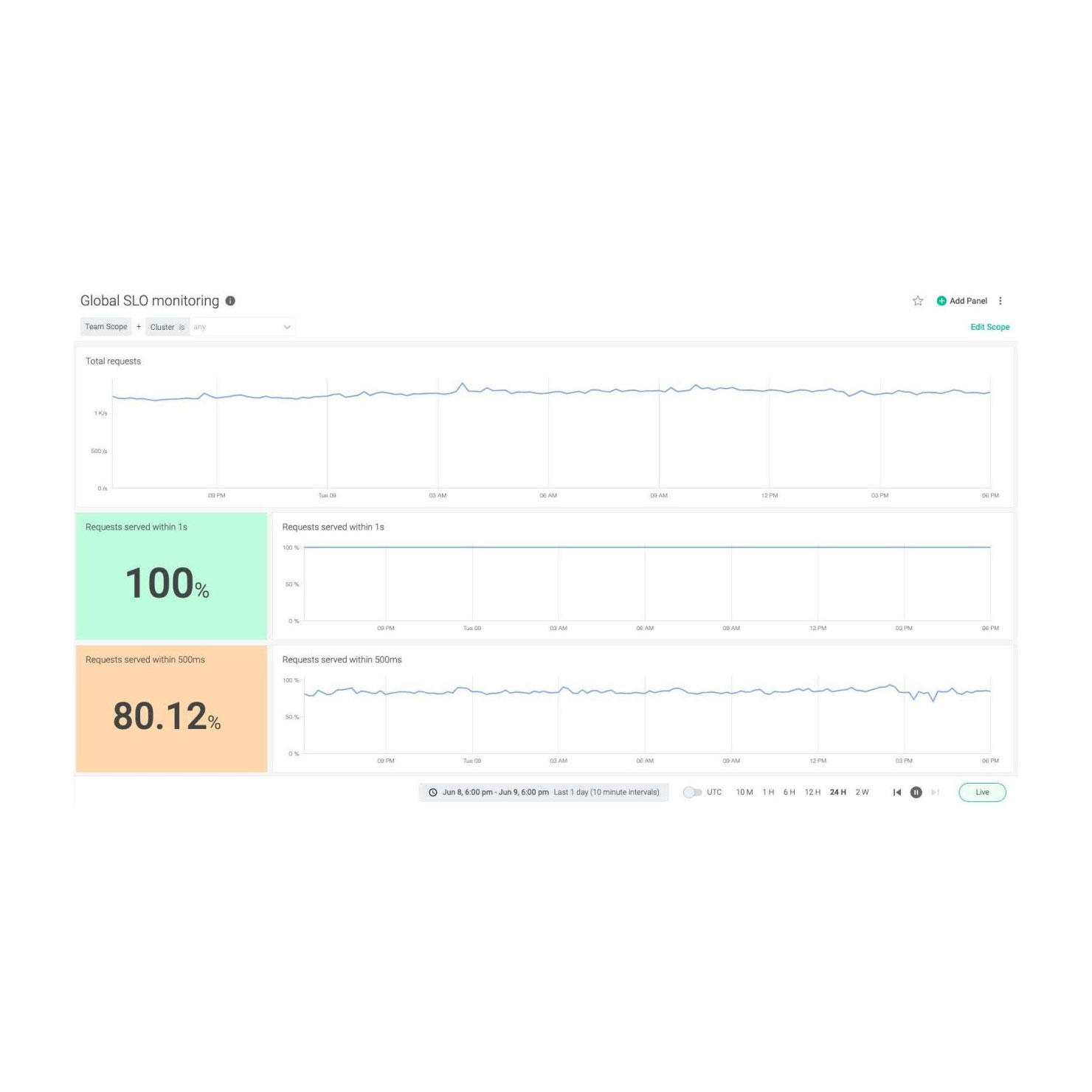
Sysdigは、Prometheusの取り込みを活用して、サーバーレスサービスを単一のペインオブグラスアプローチで監視できるようにします。
AWS Fargateは、開発者がコンテナインフラストラクチャーを管理する必要性を軽減するサーバーレスコンピューティングサービスです。
FargateのメトリクスはAWS CloudWatchによって提供され、Prometheusエクスポーターを使用して収集できます。
Sysdig Monitorでは、これらのメトリクスを取り込んで視覚化し、Fargateタスクの健全性とパフォーマンスを監視できます。
また、CloudWatchエクスポーターをKubernetesクラスターにデプロイして、Fargateクラスターのメトリクスを収集することも可能です。
Sysdig Monitorを使用すると、AWS Fargateの監視が簡単になり、本番環境でのサービスの実行に自信を持てるようになります。