Prometheus モニタリングガイド
Prometheusは、DockerおよびKubernetesの監視ツールとして人気が高まっています。
このツールは、DevOps文化とコンテナ化されたインフラストラクチャの台頭に伴い、監視フレームワークの新しい要求に応えるために開発されました。
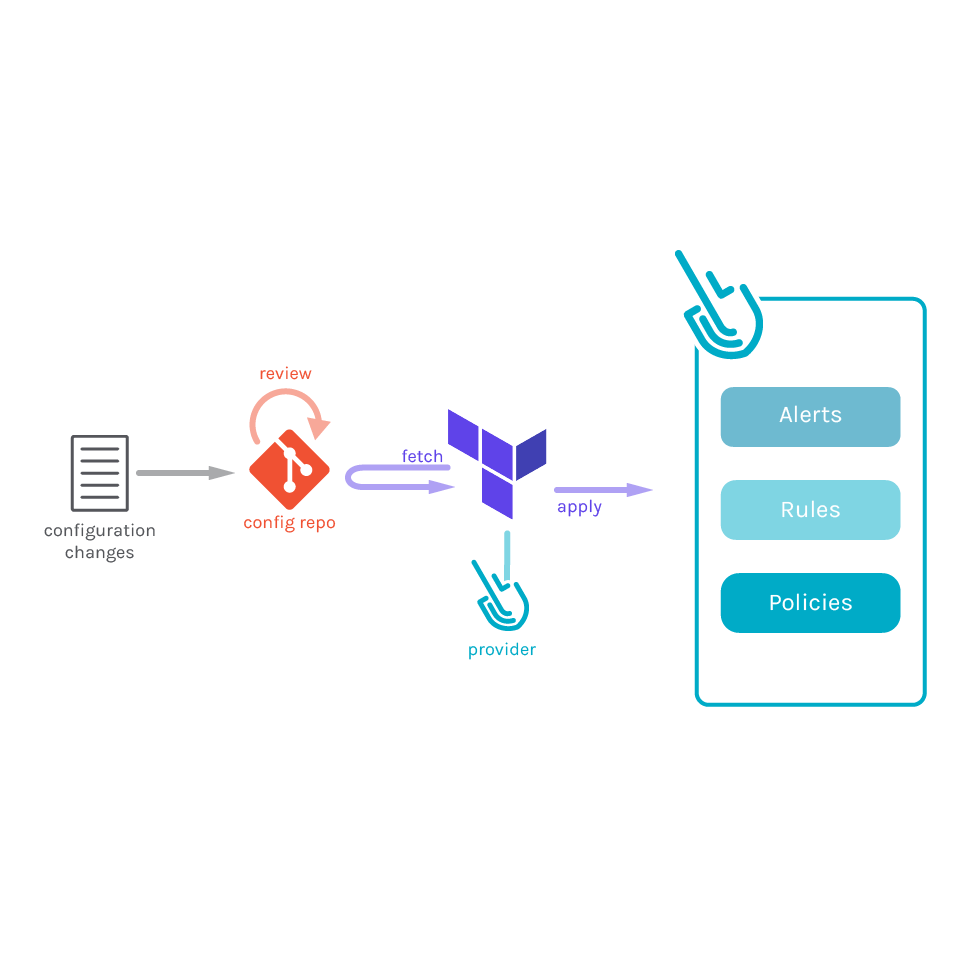
Prometheusの主な特徴には、多次元データモデル、アクセスしやすいフォーマットとプロトコル、サービスディスカバリーがあります。
これらの機能により、コンテナの可視性の向上、変化する揮発的なインフラの監視、新しいインフラストラクチャ層の管理が容易になります。
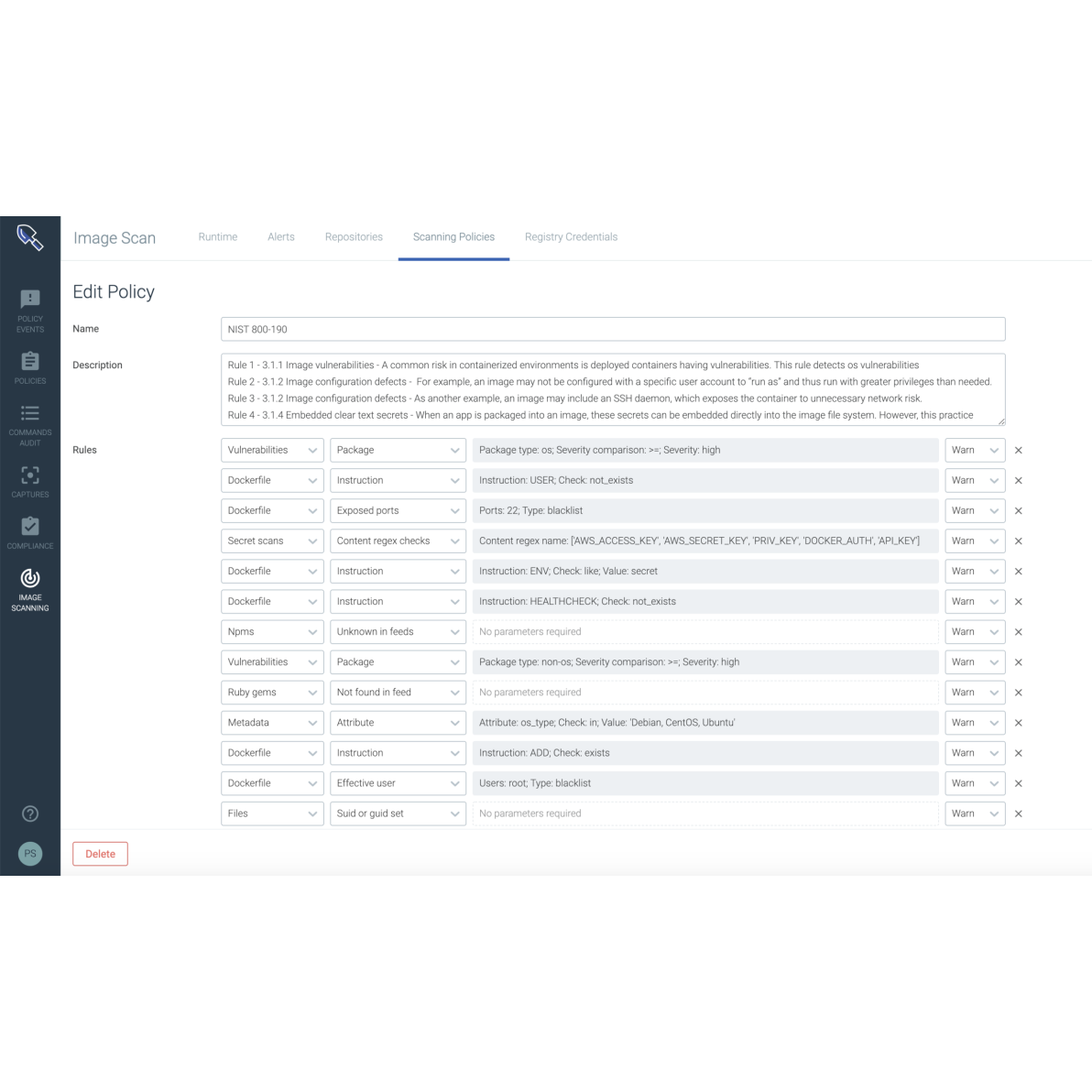
Prometheusを使用すると、Kubernetesサービス、クラスター、ノード、およびコンポーネントを効果的に監視できます。
また、kube-stateメトリクスや内部コンポーネントの監視も可能です。
Prometheusの導入により、Kubernetesの監視が容易になり、DevOpsチームはより迅速かつ効率的にインフラストラクチャを管理できるようになります。