ブログ
HOME Developer Square ブログ CrashLoopBackOffとは?Kubernetes CrashLoopBackOffイベントをアラート、デバッグ/トラブルシューティング、修復する方法
CrashLoopBackOffとは?Kubernetes CrashLoopBackOffイベントをアラート、デバッグ/トラブルシューティング、修復する方法
このブログでは、KubernetesのCrashLoopBackOffイベントの視覚化、アラート設定、デバッグ方法について解説します。
CrashLoopBackOffは、ポッドが繰り返し起動しクラッシュする現象で、多くのKubernetesユーザが遭遇します。
原因には、アプリケーションのクラッシュや設定ミスなどがあります。
kubectl get podsコマンドでCrashLoopBackOffの状態を確認し、kubectl describe podで詳細情報を取得できます。
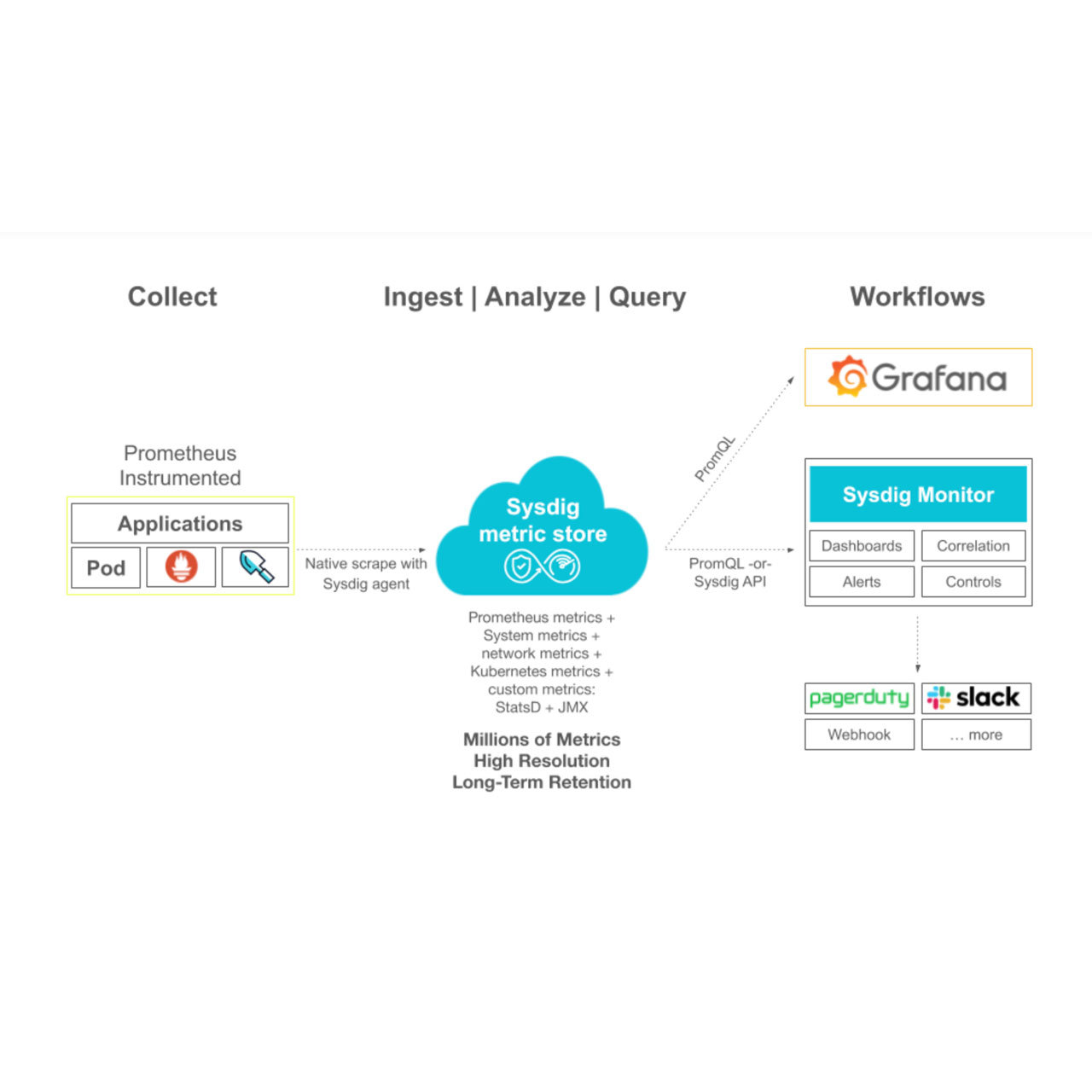
Sysdig Monitorを使用すると、Kubernetesのイベントを可視化し、アラートを設定してトラブルシューティングを助けることができます。
Sysdig Captureを活用すると、アラート発生時にシステムの詳細な情報をキャプチャし、Sysdig Inspectで分析することで、問題の原因を特定しやすくなります。