coreDNSの監視方法
coreDNSはKubernetesクラスターで頻繁に発生する問題の主な原因であり、その監視はクラスターの安定性を維持する上で極めて重要です。
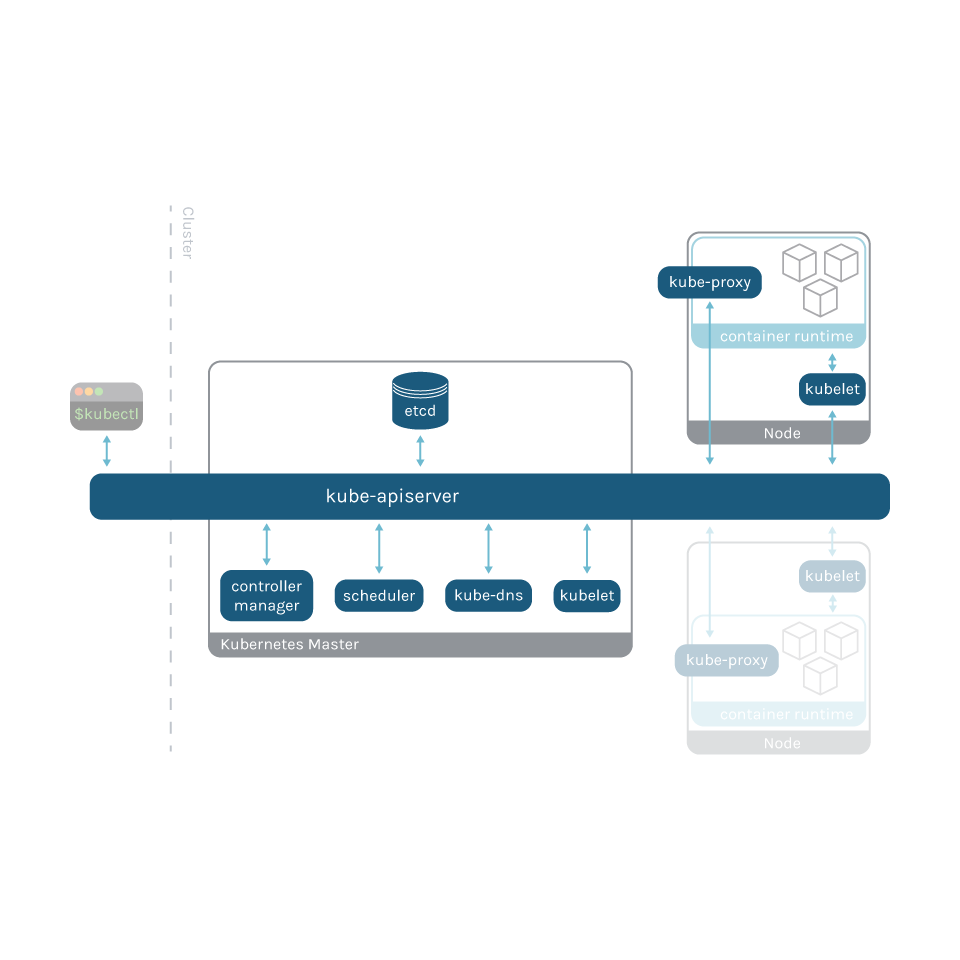
coreDNSはKubernetesのデフォルトDNSサーバーで、ポッドやサービスの名前解決を担当します。
問題が発生すると、アプリケーションの停止につながる可能性があります。
Prometheusを使用してcoreDNSのメトリクスを収集し、リクエストレイテンシーやエラーレートなどの重要な指標を監視することで、問題を迅速に特定して対処することが可能になります。
Sysdig Monitorでは、coreDNSを含むKubernetesの全体的な監視が容易になり、重要なアラートの設定も簡単です。
これにより、クラスターの問題を早期に発見し、迅速に対応することでダウンタイムを最小限に抑えることができます。