SysdigのPrometheusにおける舞台裏
数週間前、SysdigはPromCat.ioという新しいウェブサイトを発表しました。
これは、大規模な環境で使用できるPrometheusモニタリング、エクスポーター、ダッシュボード、アラートの互換性のあるリポジトリをホストするものです。
Sysdigの製品管理チームによると、PrometheusはKubernetesと並んで人気と採用が増加しています。
Prometheusの使いやすさがその成長の鍵ですが、本番環境への移行が始まると、スケールの問題が発生します。
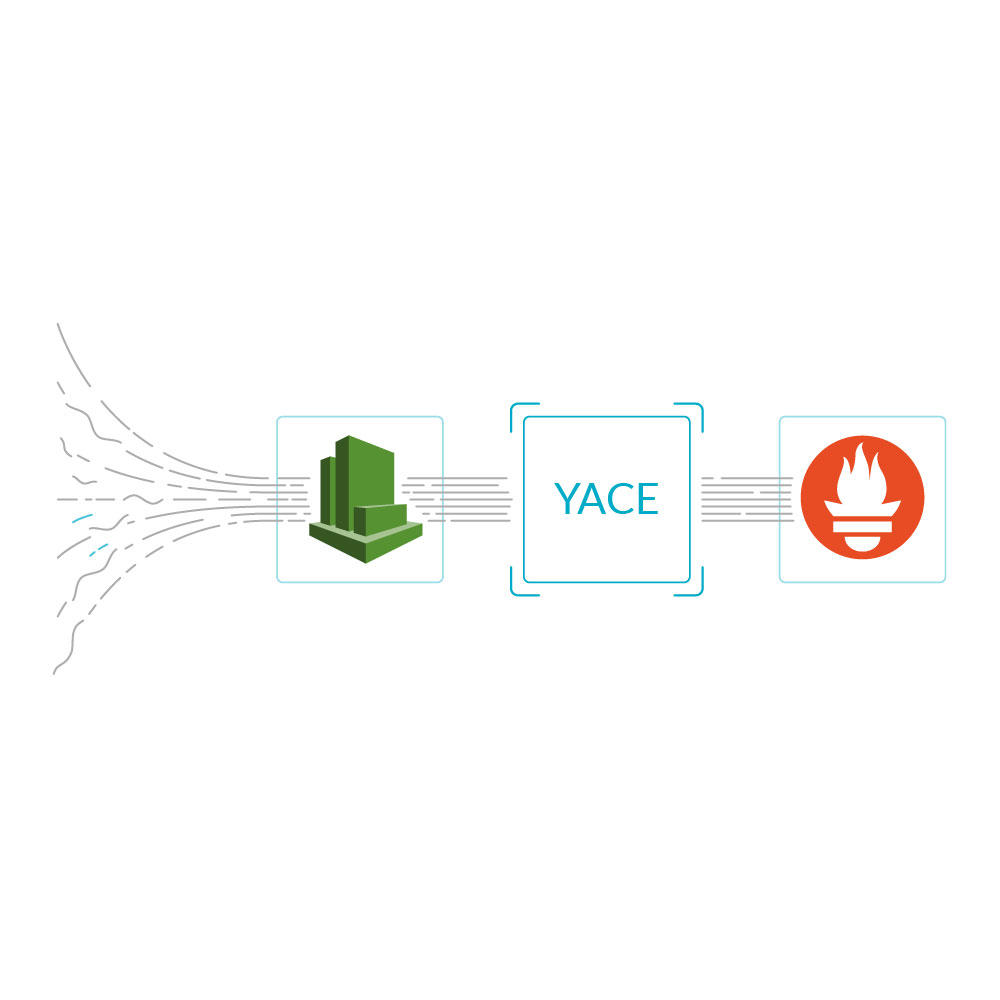
Prometheusはプルモデルを使用しているため、各クラスターにローカルにデプロイする必要があります。
これにより、クラウドネイティブメトリクスの爆発が引き起こされ、追跡する必要があるアセットの数が急増します。
SysdigはPrometheusとの完全な互換性を開発し、バックエンドを切り替えることでエンタープライズ向けの機能を自動的に提供することができます。
また、PromCat.ioを通じて、ユーザーはエクスポーター、ダッシュボード、アラートルールを簡単に取得し、統合を最新の状態に保つことができます。
これにより、ユーザーはPrometheus環境を維持する負担を軽減し、スケーラブルなモニタリングソリューションを実現できます。