全ての記事
全ての記事 トレンド
トレンド セキュリティ
セキュリティ 業務効率化
業務効率化 生産性向上
生産性向上 コスト削減
コスト削減今、注目のデータファブリック! DX/データドリブン経営をどう実現するのか
- DX
- データ活用
- データドリブン
- ../../../article/2023/06/denodo_motionboard.html

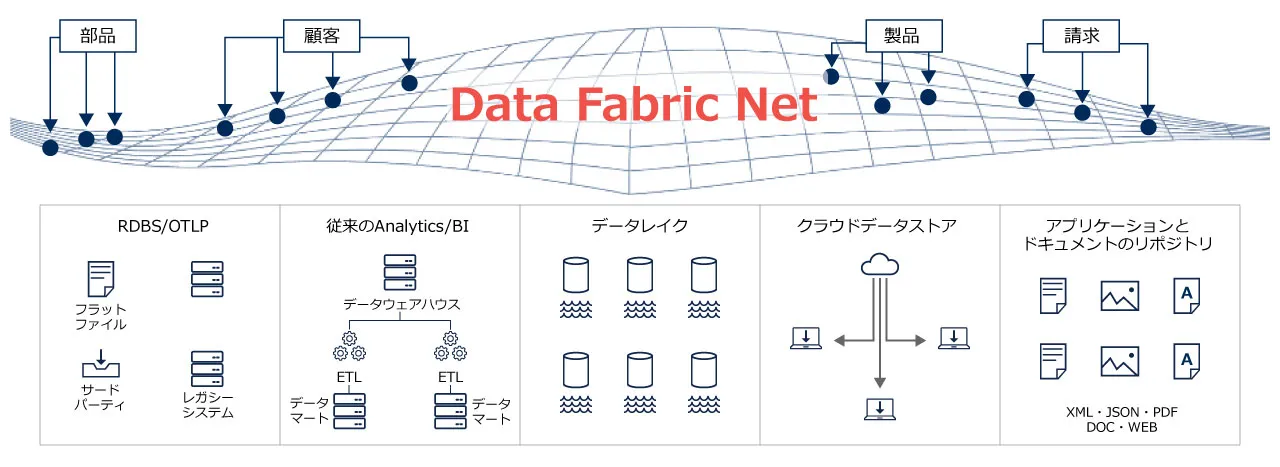
複数の場所に散在するさまざまなデータソースを、一つの仮想データレイヤーを提供してその中で統合し、実際に使える形でそろえて利用者に提供するアーキテクチャを指す。物理的なデータ統合よりもコストがかからず、欲しいデータを素早く見つけ出して利活用できるメリットがある。
データ仮想化(Data Virtualization)は、異なるデータソースや形式のデータを一つの仮想データレイヤーを提供してその中で統合し、データを連携して扱えるようにする技術です。物理的なデータの場所や形式に関わらず、仮想的に一つのデータソースとして扱うことを可能にします。
従来はさまざまな場所に散在していたデータが仮想データレイヤーを通じてまとめて提供されるため、ユーザーは複数のデータソースから簡単にデータを検索、アクセス、統合でき、分析等に活用することができます。
データ利活用を考える場合、近年は活用する「データ」が社内外に広がっており、フォーマットも異なるという課題があります。よって、従来の物理的なデータ統合はこの異なる形式のデータを「使える」状態にする必要があり、人的リソースや時間的・金銭的・ストレージ的なコストがかかります。
従来のデータ統合の問題点は以下のとおりです。
データ仮想化の主なメリットは以下のとおりです。
データ仮想化は、異なるデータソースからリアルタイムにデータを取得し統合します。これにより、常に最新の情報を利用できます。
異なるデータソースや形式のデータを、一つの統一的なビューで提供します。これにより、データの形式を統一する手間がかからず、データの検索や分析がよりスムーズに行えます。
データ仮想化は、データの物理的な移動や変換を必要としないため、大規模なデータ集約システムを構築・運用するコストと時間を節約できます。
一方で、データ仮想化には課題も存在します。大量のデータソースをリアルタイムに統合するため、パフォーマンスの問題が生じる可能性があります。また、データソースが増えるほど、データの品質や整合性の管理が難しくなることもあります。
データ仮想化のメリットを最大限に発揮できる導入・運用を行うには、実績ある外部ベンダーへの依頼も検討事項といえるでしょう。
【データ仮想化の一例(イメージ)】