Verticaの特長
大量データを高速処理できる上、機械学習、地理空間分析、パターンマッチングなどにも対応する
次世代型のビッグデータ解析プラットフォームです。
次世代のビッグデータ解析プラットフォーム
データベースの第一人者、マイケル・ストーンブレーカーが考案したVertica (バーティカ)は、ビッグデータ解析を念頭にスクラッチで設計された列指向型データベースです。Vertica は、スピード、スケーラビリティ、簡易性そしてオープン性をその中核として設計されています。分散型圧縮列指向アーキテクチャで解析のワークロードを処理するように設計しています。Vertica は、従来のデータウェアハウスのソリューションと比較すると低コストで驚異的なスピード(クエリを50~1000倍 高速化)、ペタバイトの規模(サーバーあたり10~30倍のデータを格納)、オープン性そして簡易性(BIツール、ETLツール、Hadoopなどとの円滑な連携)を提供します。
クラウド、オンプレミス、Hadoopどこでもインストール可能
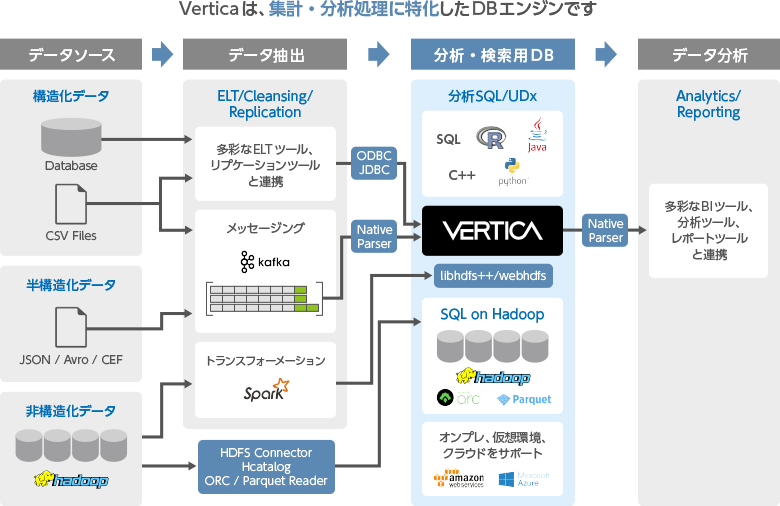
多くの企業や政府機関においてデータが増え続けています。Verticaは、莫大な量のデータを処理し、驚異的なスピードでデータ解析を提供するための次世代のビッグデータ解析プラットフォームです。このプラットフォームは、オン プレミス、仮想環境、Hadoop、そして クラウド(Amazon AWS、Microsoft Azureなど)広範囲な環境でご利用いただけます。

特長を支える仕組み
Verticaの中核は、今日の解析のワークロードを処理することを念頭において構築された列指向のRDBMSです。小規模なデータをサポートするために何十年も前に設計された商用およびオープンソースの行指向データベースとは異なり、Verticaはお客様に以下を提供します。
- ●
- 完全かつ高度なSQLベースの解析機能で強力なSQL解析を提供
- ●
- クラスタ化されたアプローチでビッグデータを格納し、クエリと解析で優れたパフォーマンスを提供
- ●
- 圧縮に優れ、同等のデータ解析ソリューションに比べると必要となるハードウェアやストレージが少ない
- ●
- ワークロードが増加した際にも柔軟性とスケーラビリティを容易に強化
- ●
- クエリでの負荷のスループットと同時実行を改善
- ●
- PythonとRubyを用いたビルトインの予測解析
- ●
- パフォーマンスチューニングのためのデータベース管理者(DBA)の介入を軽減
ネイティブな列指向
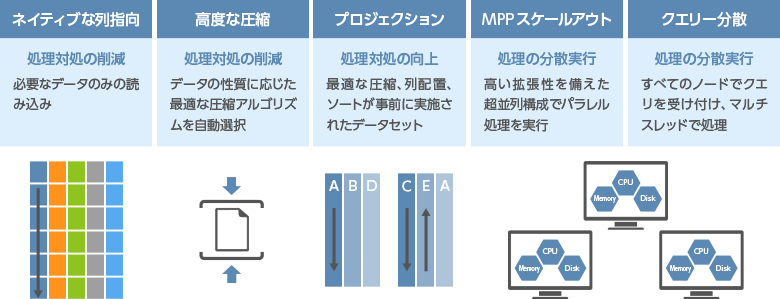
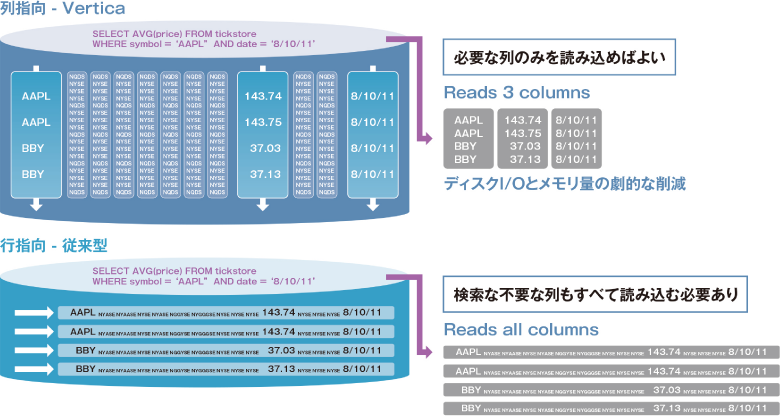
従来型のデータベースはOLTP向けに設計されており、行指向データベースのアーキテクチャーが使用されていました。行指向データベースの場合、クエリを処理するためには、テーブルの大きさや実際に必要な列数に関係なく、クエリに指定されている全テーブルのすべての列を読み取る必要があります。分析クエリでは多くの場合、数百の列が含まれているテーブルの一部の列にしかアクセスしないため、不要なデータを大量に取り出すことになります。 その一方、列指向データベース(カラム型データベース)は、検索時に必要な列のみを読み込むため、従来のリレーショナルデータベースのように大量ディスクI/Oを必要とせず、検索を50~1,000倍高速化できます。従来の方式の行型データベースが、何時間もかけて行ったクエリ処理を何秒で実行できます。
高度な圧縮・エンコーディング
データの属性に応じた最適な圧縮アルゴリズムでストレージ容量を最大90%削減できます。データ圧縮によって検索時のディスクI/O量が減り、高速な検索処理を実現することができます。
- ●
- データの属性に応じた最適な圧縮アルゴリズムで大幅なデータ圧縮
- ●
- データ検索時のI/O量が減り、より高速な処理を実現
- ●
- 物理ストレージの容量削減
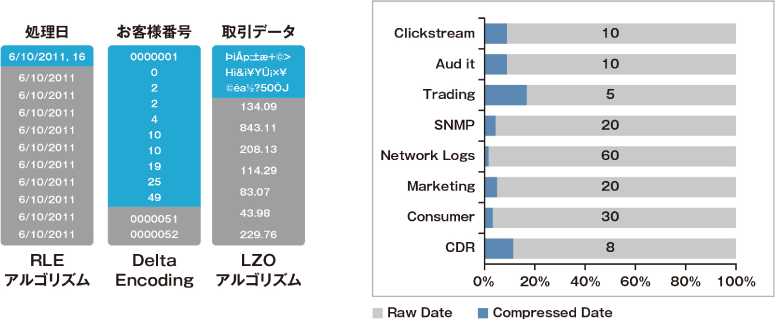
MPPスケールアウト&クエリー分散
データ増加や複雑な処理により、最大規模のスーパーコンピューターでも単体では処理できないレベルに達しています。リニアなスケーラビリティとネイティブな高可用性が必要とされています。 Verticaは、MPP(Massively Parallel Processing)アーキテクチャにより、業界標準のx86サーバをクラスターに追加するだけで、ボトルネックを回避しながら簡単にスケールアウトを実現できます。
- ●
- シェアードナッシング方式によりリニアに性能向上
- ●
- すべてのノードが同じ役割を実行可能
- ●
- マスターノードが無い、真のMPPアーキテクチャ
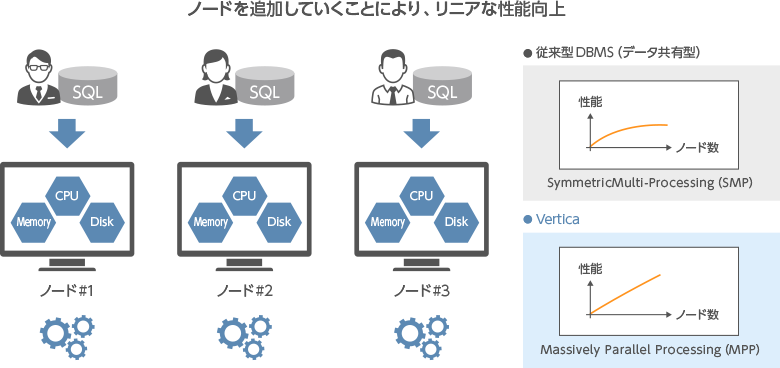
プロジェクション
Verticaのテーブルは論理スキーマを採用し、実データは独自テクノロジーのプロジェクションに格納します。プロジェクションに格納されたデータは、自動で最適な形でソート、圧縮エンコードされパフォーマンスを最大化します。
また、特定のクエリに対し、最適化したプロジェクションを定義することも可能です。対話形式型のツール(Database Designer)を利用することで、検索に最適なデータ配置を短時間で自動チューニングします。インデックス管理による複雑なクエリチューニングは不要です。Verticaのオプティマイザが最適なプロジェクションを自動的に選択し処理を実行するため、利用者はプロジェクションを意識することなく高速処理することが可能です。
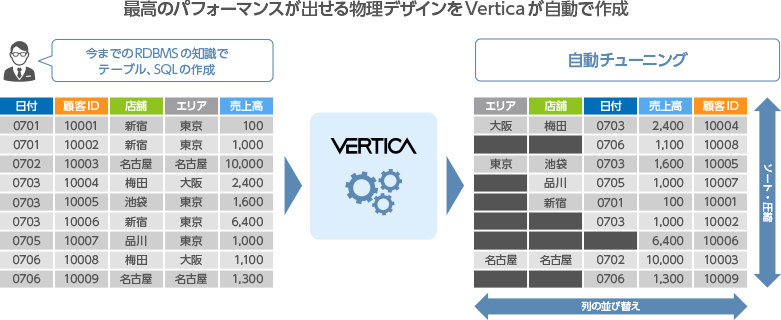
バックアップ・リストア
Verticaは、標準機能としてバックアップユーティリティ(vbr.py)を提供します。データベースを稼働した状態で、完全バックアップ、増分差分バックアップ、別クラスターへのコピー、オンラインリストアを実施することが可能です。データベース全体、スキーマ単位、テーブル単位でのバックアップ・リストアなどオブジェクト単位での詳細な運用を実現可能です。
- ●
- バックアップは、全分・差分の指定と複数世代の保持が可能
- ●
- リストアは、取得したバックアップから、世代を指定した復元が可能
データ分析の豊富な機能
ANSI SQL-99準拠、JDBC/ODBC/ADO.netドライバ対応し、標準的なBIツール/ETLツールをそのままご利用頂けます。更に、R言語やPythonで書かれた高度な統計アルゴリズムを高速に実行することが可能です。
インデータベース分析機能に最適な環境を提供すると同時に、Verticaが備えている広範な分析機能(SQL-99準拠の標準SQL、Vertica独自の分析用SQL、カスタムロジックを使用した高度な分析機能、ユーザー定義拡張機能など)を提供します。
- ●
- センチメント分析・・・時系列分析、セッション化、イベント系列パターンマッチング拡張機能
- ●
- イベント分析・・・イベント系列パターンマッチング、時系列分析、最終反復ソーシャルコンバージョン、セッション化
- ●
- パターンおよびパス分析・・・パターン認識、予測モデリング
- ●
- 時系列分析・・・タイムシリーズ、ギャップフィリングおよび補間
- ●
- 予測モデリングおよび統計分析・・・線形回帰、ロジスティック回帰、ランダムフォレスト、ナイーブベイズ
- ●
- 顧客セグメンテーション・・・K平均法
- ●
- 地理空間分析 ・・・ジオスペーシャル関数

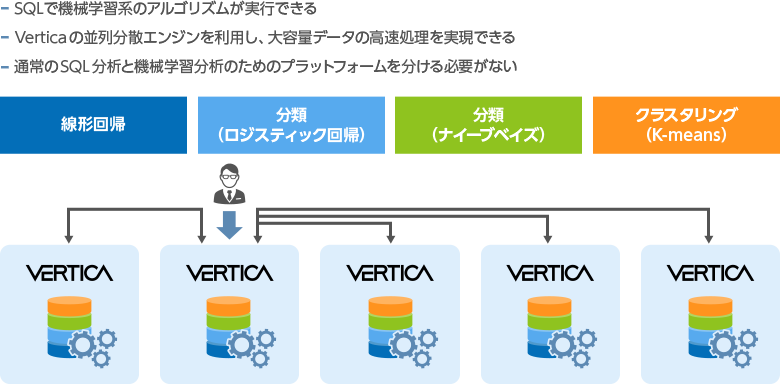
機械学習 In-DB Machine Learning
ANSI SQL-99準拠、JDBC/ODBC/ADO.netドライバ対応し、標準的なBIツール/ETLツールをそのままご利用頂けます。更に、R言語やPythonで書かれた高度な統計アルゴリズムを高速に実行することが可能です。
インデータベース分析機能に最適な環境を提供すると同時に、Verticaが備えている広範な分析機能(SQL-99準拠の標準SQL、Vertica独自の分析用SQL、カスタムロジックを使用した高度な分析機能、ユーザー定義拡張機能など)を提供します。
代表的な機能
- ●
- K-means
- ●
- ロジスティック回帰
- ●
- 線形回帰
- ●
- ナイーブベイズ
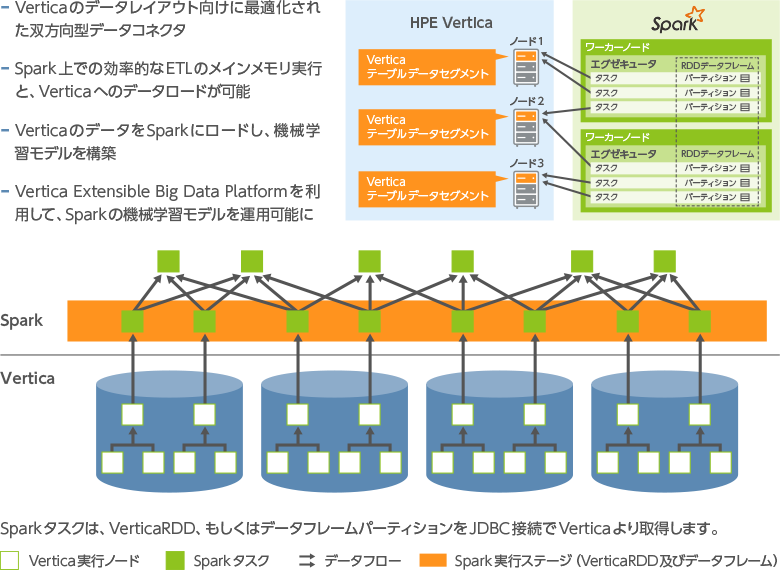
Apache Sparkとの統合
Verticaは、Apache Sparkに並列接続し、統合することが可能です。Verticaは、RDD(Resilient Distributed Datasets)をベースとしたフレームワークに読み書きすることができ、処理したデータを2つのコンポーネント間でやり取りすることが可能です。Sparkの優れた機能や資産を使用することでアウトプットを最大化できます。インメモリクエリにSparkを利用し、大容量データに対する実行時間の長い分析にはVerticaを利用するという形でインフラを構築することが可能です。
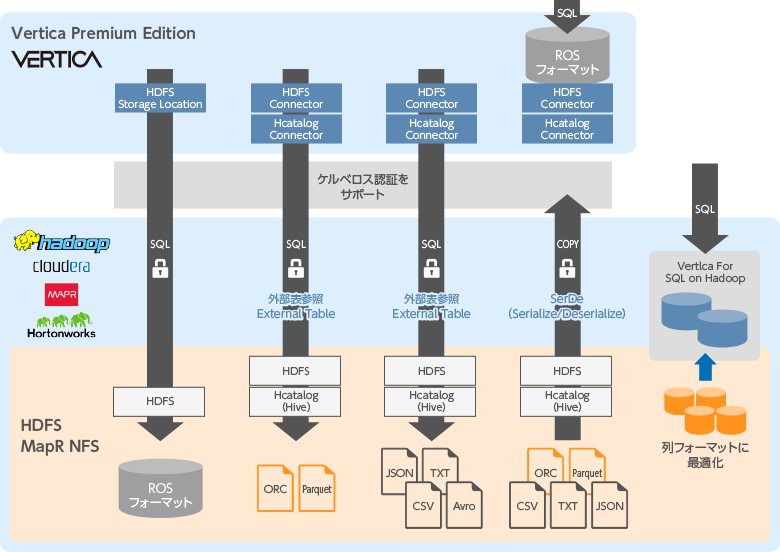
Hadoopとの連携
Vertica SQL on Hadoopは、Hadoopデータに対するSQLクエリを実行するための最速か つ最も企業向けの方法を提供します。ビッグデータ解析に長年携わってきた当社の経験を生かし、 Hadoopクラスタのフルパワーを用いたプラットフォームを設計しました。ユーザーは、使用される データの形式やHadoopディストリビューションに関わらず、解析を実行することができます。HDFS上のORC、Parquet形式のカラム型に対応したパーサーもサポートし、Hadoop上のデータを高速に処理できます。
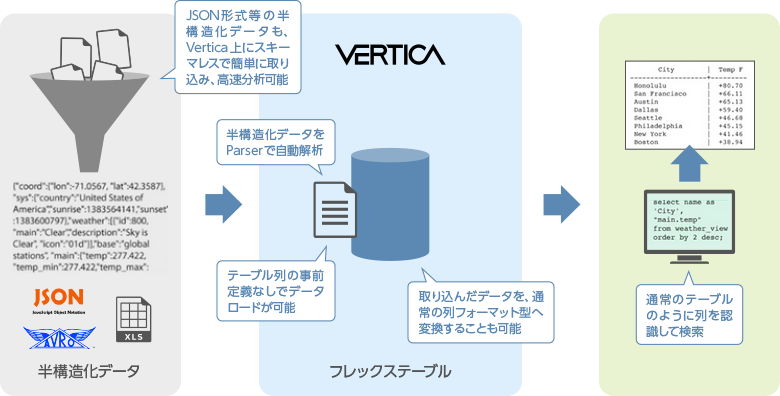
半構造化データ(JSON, Avro形式等)の分析
Flex Table(フレックス テーブル)のテクノロジーにより、Verticaは企業内に存在する非構造化データやダークデータをスキーマを定義・適用することなくロードし、クエリ処理を実行することができます。Verticaは、ソーシャルメディア、 センサー、ログファイルやマシンデータなどの半構造化データを迅速かつ容易に読み込み、探索し、分析する能力を提供します。 Flex Tableを用いると、御社のIT組織に負担をかけたり、データの抽出、構造化や読み込みを待つ必要なく、JSONや区切られたデータなどの情報を探索・ 視覚化することができます。Flex Tableは高パフォーマンスのデータ解析に必要なデータ探索スキーマを生成し、変化し続けるデータ構造に対応することをさらに容易にします。
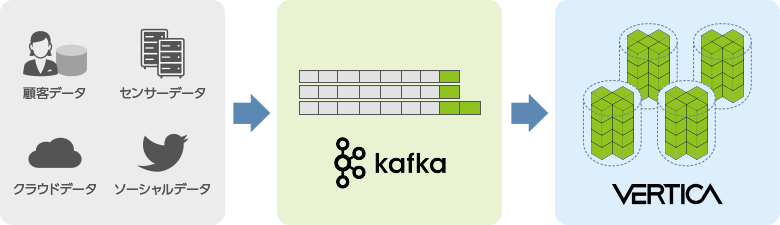
Apache Kafkaと連携
Verticaは標準でApache Kafkaと連携する機能を利用します。業界標準のメッセージングバスを活用することでニアリアルタイムの高度なストリーミングシステムを実現します。ログ集約、メトリクス収集、クリックストリームなど大規模データの処理にも対応します。