HOMEデベロッパー向け ブログ・コミュニティ SCSK技術者ブログ 図解で学ぶOpenShift構成 Vol.1:基礎編
図解で学ぶOpenShift構成 Vol.1:基礎編
みなさん、こんにちは。Red Hat OpenShift(以下OpenShift)のプリセールス、構築を担当している古野です。
はじめに
本連載では、OpenShift 環境の導入・運用・設計に携わるエンジニアに向けて、目的別・レベル別に構成図を描くための考え方と実践例を紹介します。
案件の企画段階でも、ある程度の価格感を見積もるために、大まかな構成を理解しておくことが重要となりますので、参考までに読んでいただけますと幸いです。
今回含めて構成図に関するブログを3部構成で投稿予定です。
| Vol. | テーマ | 詳細 |
| Vol.1 | 基礎編 | クラスタの基本要素とサーバ間の関係 |
| Vol.2 | VersionUP 編 | バージョンアップクラスタの構成設計 |
| Vol.3 | DR 編 | 災害対策環境の構成設計 |
今回は、インフラ層に何を選択するか、についてはボリュームの関係で触れませんが、ベアメタル、ハイパーバイザー(vSphere, Nutanixなど)、パブリッククラウド(AWS(ROSA)、Azure(ARO)、GCPなど)、プライベートクラウド、Edgeなど様々な選択肢があります。
バージョンアップするごとに選択肢が増えて行っているので、用途に合わせて選定していただくのが良いと思います。
OpenShift クラスタ構成図(基礎編)
以下の図は、標準的なOpenShift クラスタ構成(Control Plane Node x3台、Infra Node x2台以上、Compute Node x2台以上)を表しています。
また、例として、クラスタ外で利用されるサーバについても挙げております。
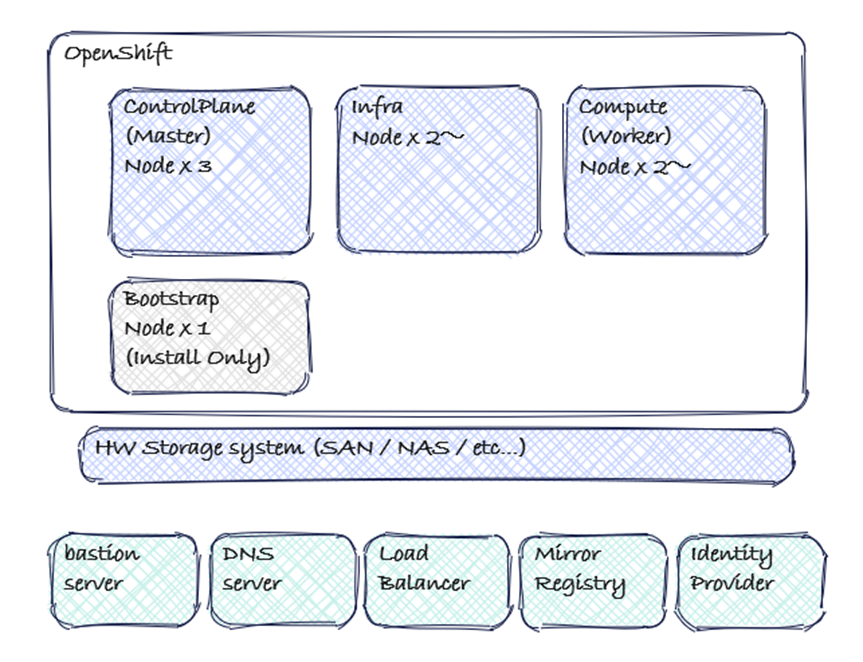
各サーバの役割
各サーバの役割を説明します。
| サーバ | 役割 |
| Bastion Server |
運用者がクラスタにアクセスする踏み台サーバ。 Ansible InstallerやSSH、API操作を実行。 |
| Load Balancer | IngressとAPIトラフィックを制御。api.<cluster_name>.<base_domain>、api-int.<cluster_name>.<base_domain>、*.apps.<cluster_name>.<base_domain>を分散。 既存のNW環境を利用するケースではすでに用意があるケースが多い。 |
| DNS Server |
クラスタのエンドポイント(api, *.apps)の名前解決と、クラスタから外部リソースへの名前解決を担当。 OpenShiftインストール時には、api.<cluster_name>.<base_domain>と*.apps.<cluster_name>.<base_domain>のレコード登録が必須。既存のNW環境を利用するケースではすでに用意があるケースも多いが、Bastion Serverにdnsmasqなどをインストールして構築するケースもある。 |
| Mirror Registry | 非接続環境(インターネットアクセスを行わない環境)で、OpenShiftのインストール、アップグレード、およびアプリケーション実行に必要なコンテナイメージを保管・提供する。 |
| Identity Provider (IdP) |
WebコンソールやCLIへのログイン認証を管理する。Active Directoryなどの既存の認証基盤と連携し、シングルサインオン(SSO)を実現する。 Active Directory, LDAP, Keycloak, oktaなどが利用される。Control Planeノードから通信が発生する。 |
| Control Plane Nodes |
etcd / kube-apiserver / Controller Manager 等クラスタ制御を担当。 Masterノード。 |
| Infra Nodes |
Router、内部Registry、Logging、MonitoringなどのシステムPodを実行。 Infra ノードは、OpenShift のサブスクリプション体系上、特定の非機能要件用Operatorのみが稼働するノードであればサブスクリプションの課金対象外となるため、コスト最適化の検討ポイントにもなる。環境規模によってはCompute ノードと兼用することも可能だが、モニタリングやIngressなどの基盤機能を安定稼働させたい場合には、専用Infra ノードとして分離設計することが望ましい。台数は、ログサイズ・監視頻度・レジストリ利用状況などに応じて柔軟に決定し、保守計画(定期再起動・アップグレード時の余裕台数)に反映させることが推奨される。 |
| Compute Nodes |
アプリケーションPodを実行。 Workerノード。 |
| Bootstrap Node |
初期構築時のみ使用し、完了後に削除可能。 インストール方式によっては不要なケースもある。 |
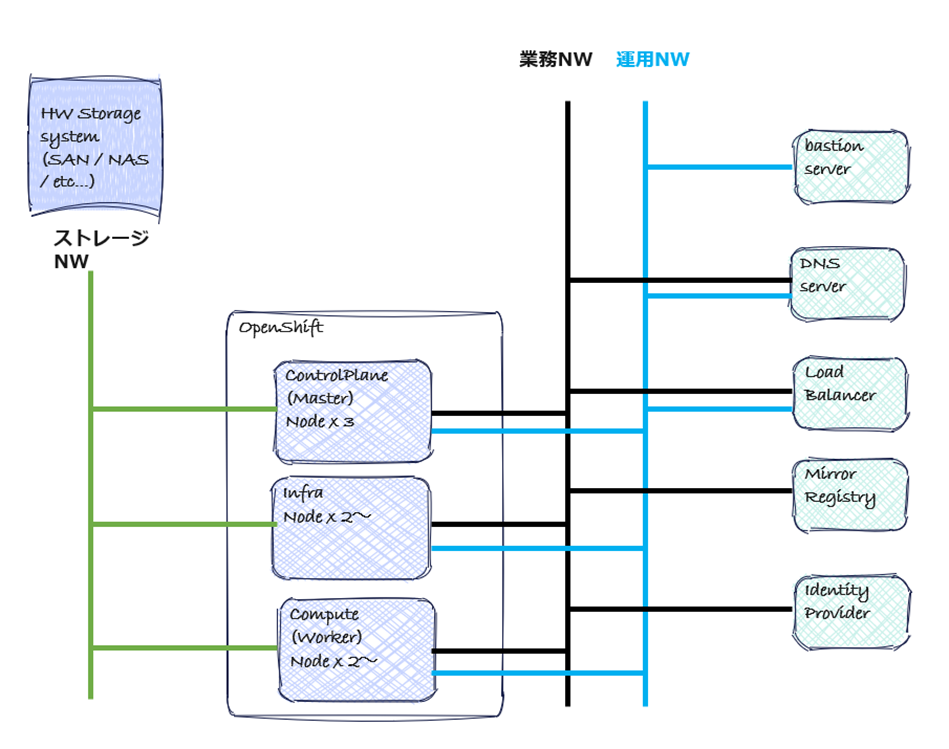
ネットワーク構成の概要
- 運用時のアクセス
運用者がocコマンドを使ったり、Webコンソールにログインしたりするための、クラスタの管理用アクセス経路。
経路:運用者/CI/CD → DNS → LB → API VIP (api.<cluster_name>.<base_domain>) → Master Node → API Server - クラスタ外からのアクセス
WebサイトやAPIなど、ユーザーが利用するアプリケーションへのアクセス経路。
経路:エンドユーザー → DNS → LB → Ingress VIP (*.apps.<cluster_name>.<base_domain>) → Compute Node → Router Pod → アプリケーションPod - クラスタ内部のアクセス(Control Plane ⇔ Infra ⇔ Compute)
Kubernetes Pod、Service、etcd の通信経路。
Kubernetesクラスタ内で稼働するPod同士の通信。OVN-KubernetesなどのCNIプラグインが提供するオーバーレイネットワーク上で実現される。アプリケーションPodからデータベースPodへの接続などがこれにあたる。my-service.my-project.svc.cluster.local のような内部DNS名(Service名)でPod間の通信が行われる。 経路:Pod ⇔ Service ⇔ Pod - クラスタ内からクラスタ外へのアクセス
クラスタ内のPodが、外部のコンポーネント(DNS、ミラーレジストリ、IdP、外部DBなど)にアクセスするための外向きの通信。 経路:Pod → Worker/Master Node → デフォルトゲートウェイ → 外部リソース
例として簡易的なネットワーク構成図を作成してみました。
図では、1)の通信を行うためのネットワークを運用NW、2)~4)の通信を行うためのネットワークを業務NWとしています。4)の通信のうち、ストレージ機器や外部ストレージとの通信を行うNWはパフォーマンスやセキュリティの観点から分けるケースがありますので明示的にストレージNWとして分けて表現しています。
クラスタ構成パターン別の特徴
OpenShift は要件に応じてさまざまな構成パターンを選択できます。 以下に代表的な3 パターンを挙げ、それぞれのメリット・デメリットを整理します。 可用性、拡張性を考慮すると、1. Standard Cluster(Control Plane 3 台 +Compute 2 台以上)がおすすめですが、コストがかかるので、クラスタの利用用途に合わせて構成を選択してくのがポイントです。
- Standard Cluster(Control Plane 3 台 +Compute 2 台以上) ★推奨構成
本番運用を前提とした標準構成。制御系と実行系を完全分離。
エンタープライズ本番環境/中~大規模クラスタ構成で利用。
Control Plane 専用3 台 + Compute (Worker) 2 台以上 + Infra ノード オプション。
<メリット>
・制御系と実行系が独立し安定。
・スケールアウト容易。
・ノード障害やメンテナンス時にも影響を最小化。
・DR 設計・アップグレード設計に適す。
<デメリット>
・初期構築コストとリソース要件が高い。
・ノード数が多く運用設計がやや複雑。 - Single Node OpenShift(SNO)
最小限の1 台構成のクラスタ。エッジ環境や小規模検証環境で利用。
Control Plane + Compute + Infra 要素を1 台に統合。
<メリット>
・導入・構築が非常に容易。
・リソース消費が最小限。
・検証・開発・PoC用途に最適。
<デメリット>
・可用性がなく、ノード障害時に停止。
・スケールアウト不可。
・etcd ・ API ・ アプリが同一ノード上で競合しやすい。 - 3 Node Cluster
Control Plane × 3(兼 Compute)による高可用クラスタ。比較的小規模の環境で利用。
3 台すべてが Control Plane + Compute 兼任。etcd のクォーラムを3 台で確保。
<メリット>
・最小限の台数で高可用構成(etcd 冗長化可)。
・小規模でも本番運用可能。
・ノード障害時もサービス継続。
<デメリット>
・ワーカー兼任のためリソース競合が発生。
・Compute リソース拡張に制約。
・ロード時に負荷上昇の恐れ。
ノード数と最小リソース要件(参考値)
- Standard Cluster(Control Plane 3 台 +Compute 2 台以上)
Red Hat社がドキュメントで提示している各ノードの最小リソース要件をのせておきます。バージョンやクラスタの構成により変動しますので、参考値として、v4.20の任意のプラットフォームへのインストール時の最小リソース要件を載せておきます。
https://docs.redhat.com/ja/documentation/openshift_container_platform/4.20/html/installing_on_any_platform/installation-requirements-user-infra_installing-platform-agnostic#installation-minimum-resource-requirements_installing-platform-agnostic
マシン vCPU 仮想RAM ストレージ 1秒当たりの入出力(IOPS) Bootstrap 4 16GB 100GB 300 Control Plane 4 16GB 100GB 300 Compute 2 8GB 100GB 300 表2:Standard Cluster(Control Plane 3 台 +Compute 2 台以上)の最小リソース要件
Computeノードでは最小リソース要件に加えて、ノード上で稼働するアプリケーションのリソース要件を反映してサイジングしていきます。そのため、ある程度コンテナで動かすアプリケーションの規模を想定しておくと整理しやすいです。
ノードのスペックが足りなくなった場合はComputeノードを追加することができますので、初期でどのくらいのスペックを見込んでおくかが決められれば、将来的には拡張して運用していくことが可能です。
また、ノード障害で1ノード機能しなくなった場合には、特別な設定をしていない限り正常に稼働しているノードにPODが割り振られることになりますので、その分を見込んだサイジングも必要となります。 - 3.Single Node OpenShift(SNO)/ 3 Node Cluster
シングルノード構成と3ノード構成の場合の最小要件はこちらです。
3ノード構成の情報は、Red HatドキュメントではAgent-Baseインストールをベアメタルノードにインストールする場合の最小リソース要件が記載されておりましたので、そちらを参照しております。
参照ドキュメント:単一ノードにOpenShiftをインストールするための要件
https://docs.redhat.com/ja/documentation/openshift_container_platform/4.20/html/installing_on_a_single_node/install-sno-requirements-for-installing-on-a-single-node_install-sno-preparing
マシン vCPU 仮想RAM ストレージ Control Plane / Compute 8 16GB 120GB 表3:Single Node OpenShift / 3Node Clusterの最小リソース要件
まとめ
ここまで、構成を検討するにあたって考えるポイントとなる基礎的な部分を説明しました。汎用的なお話になるので、要件に合わせて詳細を詰めていく必要もありますが、基本的な考え方としては参考にしていただけると思います。
これ以外にも、バージョンアップの考え方や、災害対策環境の構成についても今後触れていきたいと考えております。
次回、VersionUP編では、VersionUPの対応方法や対応方法ごとの想定されるクラスタ構成について触れる予定です。
考えることが多くてめげてしまいそうですが、導入することによるメリットも大きいので根気強く頑張っていきましょう!
