

 全ての記事
全ての記事 トレンド
トレンド セキュリティ
セキュリティ 業務効率化
業務効率化 生産性向上
生産性向上 コスト削減
コスト削減
日産自動車が電動パワートレインの開発で大幅な工数・コスト削減を実現!その理由とは?
- 解析シミュレーション
- インタビュー
- CAE
- ../../../article/2021/08/advc.html

どうも!ITPNAVI編集部の加藤です!今回は私が参加した、製造業におけるGPU活用に関するセミナーについて、内容をまとめてご紹介します!
製造業の製品開発プロセスにおいて、実際に製品を作る前にデジタルで製品性能をシミュレーションする、いわゆるCAEソフトウェアは、試作レスやコスト削減などの観点から今や欠かせないツールとなっています。近年ではその計算リソースに、従来のCPUに加えてGPUを活用することで、シミュレーションの性能と速度をさらに向上させることが期待されています。
そんなGPUによる開発プロセスの改善をテーマに、2022年7月に開催されたウェブセミナー「GPUで進化する!CAEの最新情報」(SCSK主催、SB C&S株式会社、アンシス・ジャパン株式会社、エヌビディア合同会社共催)をレポートします。
| <講演者> | |
|---|---|
 |
アンシス・ジャパン株式会社 技術部 桑山 智一 氏 |
Ansysはシミュレーション主導の製品開発を支援するCAEソフトウェアのリーディングカンパニーです。電磁界シミュレーション、衝突試験シミュレーションの他、様々な物理現象を対象としたCAEソフトウェアを扱っており、製品開発における収益成長とコスト節約に寄与しています。
今回は、シミュレーション速度の向上を目的に力を入れているGPUソルバーの開発動向と、実際の高速化事例についてご紹介します。
AnsysではGPUリソースの適用範囲に応じて、2パターンのGPUソルバーを開発しています。
シミュレーションにおいて計算負荷が最もかかる部分のみをGPUで計算し、それ以外の部分は従来通りCPUで計算する手法です。ここでは「Ansys Fluent」による解析事例をご紹介します。
Ansys FluentとはAnsysが提供する汎用熱流体CAEソフトウェアです。豊富な物理モデルにより、低速流からマッハを超える高速流まで幅広くシミュレーションできるほか、CPUやGPUのコア数を増やすことで計算速度を高める並列化効率が優れているソフトウェアです。
このAnsys Fluentで飛行機のタイヤ周りの気流をシミュレーションしてみましょう。
32coreのCPUによる計算速度と、合計は同じ32coreですが、28coreのCPUに加え4coreのGPUによって特に計算負荷の高い部分を解いた場合の計算速度を比較します。CPUのみの計算速度と比較すると、GPUを併用することで約4倍のスピードアップができました。
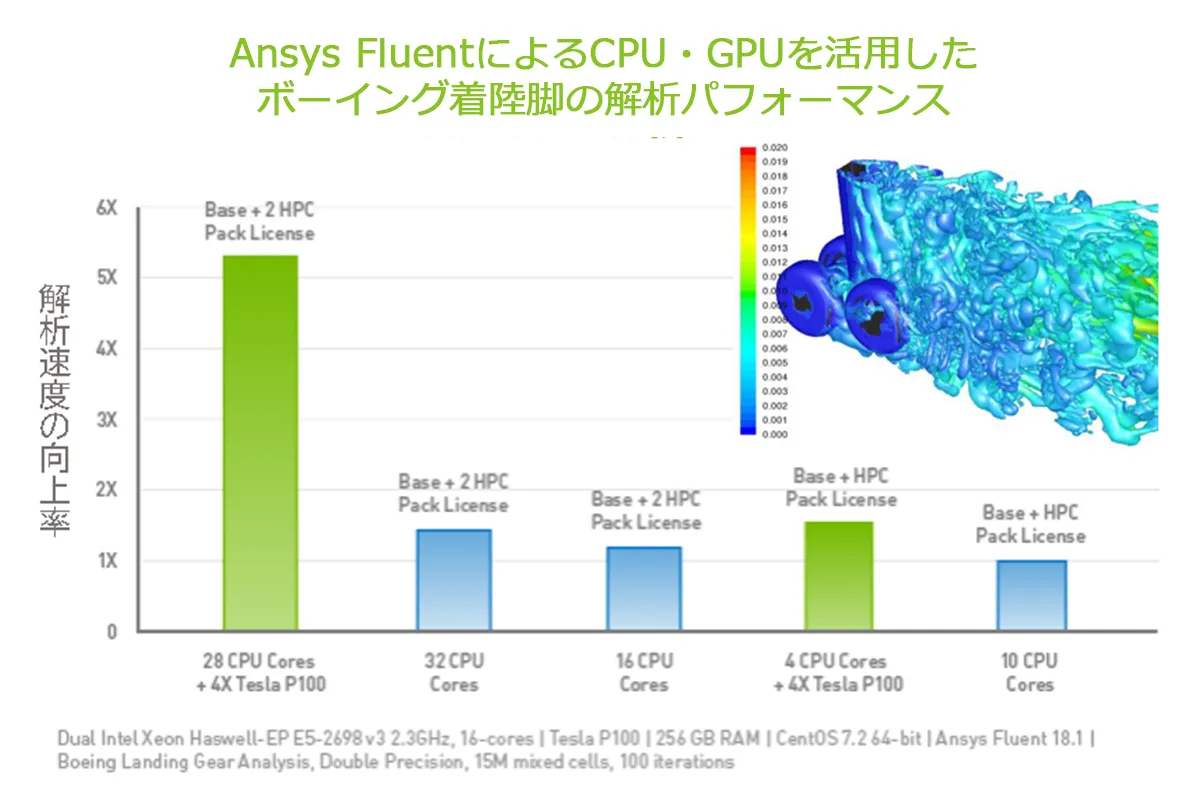
さらにAnsys Fluent 2022 R1バージョンでは、開発途中のβ版ではあるものの、計算リソースにGPUを複数枚使うマルチGPU対応によってますます並列化効率を高めることができます。
続いて紹介するパターン2では、メッシング・解析計算・ポスト処理といったシミュレーション領域を、CPUを使わず全てGPUで計算します。この技術を活用しているのが「Ansys Discovery」です。
Ansys Discoveryは3Dモデルの作成から編集、シミュレーションを1つのGUIで実行できるソフトウェアであり、CAD感覚で簡単に3Dモデルの形状を変更し、それを瞬時に反映して解析を実行します。そのためCAE専任者に解析を依頼することなく、設計者自らがAnsys Discoveryを使って素早く初期検討を行うことで設計工数を短縮できます。Ansys Discoveryでは、シミュレーション領域を全てGPUが処理することで計算速度を高め、さらなる設計工数の短縮を実現しています。
このようにAnsysでは、GPUを積極的に活用したソフトウェアを提供することで、CAEにおける計算時間の高速化、ひいてはモノづくりのフロントローディングを支援しています。
| <講演者> | |
|---|---|
 |
エヌビディア合同会社 ソリューションアーキテクト 丹 愛彦 氏 |
製品開発工数の短縮が叫ばれる近年、CAEへの期待も高まると同時にその解析モデルに変化が起こっています。1つは、より実物に近い現象を再現するべく、解析モデルの緻密化・大規模化が進んでいます。また1つは、AIを活用して最適解を探索するべく、単体の計算負荷はさほど高くない解析モデルを、変数を使って膨大なパターンで計算した結果、全体として大規模な計算リソースが必要になるというケースです。
今回は、このような大規模な計算ニーズに応えるNVIDIAの最新GPUをご紹介します。
「NVIDIA A100 80GB(以降NVIDIA A100)」は現在NVIDIAが提供している最新のGPUです。ここでは、新機能の一つである「Multi-Instance GPU(MIG)」と、解析時間に影響するメモリバンド幅の改良という2点を踏まえてその性能を解説します。
MIGとは、一枚のGPUを複数の小さなGPUとして分割して使う機能です。GPUの性能は単体でも非常に高いため、解析内容によっては1回の計算でそのGPUリソースを全て使いきれない場合があります。しかしMIGを使えば、余ったリソースを他の計算に割り当てることで有効に活用できます。分割したリソースを使って複数人がいくつかの計算を同時に実行するといったように、同じ時間でより多くの処理が可能になるのです。
続いて、CAEの計算時間に大きく影響すると言われているメモリバンド幅について説明します。メモリバンド幅とは、単位時間にどれだけのデータをメモリから読み出せるかを示す値で、通常は1秒を基準に算出されます。メモリバンド幅が小さいとその分データを読み込む時間もかかるため、計算時間がかかってしまうのです。一世代前の「NVIDIA V100」ではこのメモリバンド幅が900GB/sだったのに対し、NVIDIA A100では2039GB/sと飛躍的に向上しました。
NVIDIA V100の性能を1とした場合のNVIDIA A100の解析性能を以下の図に示しています。様々なCAEソフトウェアにおいて、約1.5~2倍のスピードアップを実現しています。
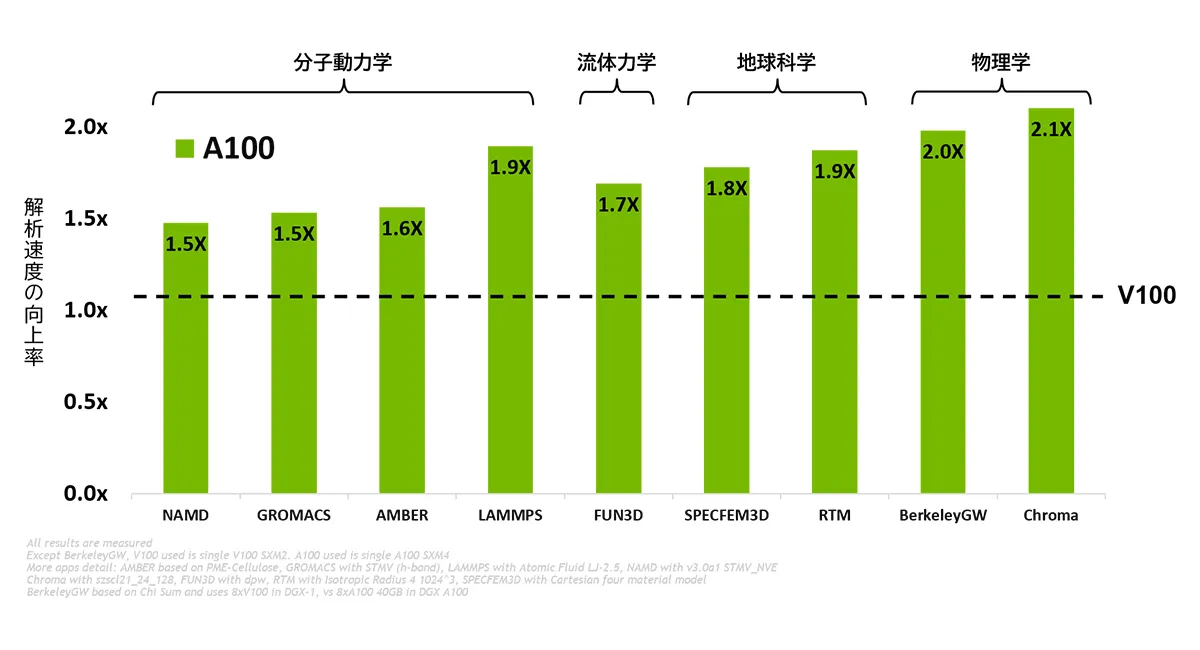
NVIDIA A100は、サーバータイプの「DGX A100」や、ワークステーションタイプの「DGX Station A100」に搭載されており、利用者のニーズに応じて活用いただけます。
また2022年中には、「NVIDIA H100」のリリースも予定しています。各演算コアの性能向上やメモリバンド幅の高速化により、今後ますますGPU基盤がCAE解析加速に貢献します。
※NVIDIA製品サイト:https://www.scsk.jp/sp/nvidia/index.html
| <講演者> | |
|---|---|
 |
SCSK株式会社 ITソリューション技術部 柴﨑 勝憲 氏 |
ここでは、これまでのGPUから話を広げ、CAE加速に寄与するHPCクラスタをテーマにお話しします。HPCクラスタとは、複数台のPCやPCサーバーを高速なネットワークと様々なシステムで繋ぐことにより、1つのハイスペックな計算機として用いる技術です。大規模な計算リソースが必要とされるCAE領域では欠かせない仕組みとなっています。
HPCクラスタを構築するためのシステムとしては、例えば並列化ミドルウェア、共有ファイルシステム、認証システム、時間同期システムなどがあります。加えて、利用効率を上げるために、ジョブスケジューラ、リソース管理、GUIジョブ投入ツールなども用いられます。
このようにHPCクラスタは非常に多くのシステムが必要なため、全てを自前で用意するオンプレミスではなく、外部で構築されたシステムをサービスとして利用できるパブリッククラウドを活用する流れが高まっています。ここでは、CAE計算にHPCクラスタを利用するにあたってのパブリッククラウドのメリットを整理し、快適なCAE環境を実現するためのポイントをお伝えします。
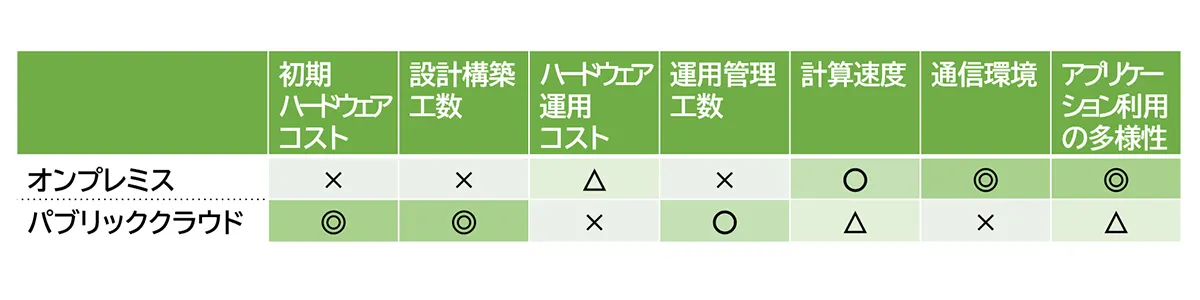
一般的なパブリッククラウドのメリットとしては大きく2点、ハードウェア利用効率の高さとシステム構成の柔軟性が挙げられます。
しかし残念ながら、CAE計算にとってハードウェア利用効率の高さは期待できません。パブリッククラウドでは仮想化技術を用いることで、通常余りがちなCPUリソースを仮想的に分割して複数の計算にあて、利用効率を高めています。一方CAE計算においては、初めから100%に近いCPUリソースを使うため、仮想的に分割したところで十分な空き容量がありません。そこへ別の計算があてがわれてしまうと、リソースが不足する分だけ計算時間が余分にかかってしまいます。そのため、物理的なリソースをそのまま用いるオンプレミスの方が利用効率に優れることが多いのです。
しかし、システム構成の柔軟性という点ではCAE環境構築にもパブリッククラウドのメリットが発揮されます。具体的には、ハードウェアやOSを自ら用意する必要がないため初期コストが抑えられたり、様々な計算環境を簡単に構築できるため設計工数が短縮できたりといった、オンプレミスには無い様々なメリットが挙げられます。
このようにオンプレミスとパブリッククラウドは一長一短です。例えば開発の繁忙期で一時的に追加の計算リソースが必要な際、オンプレミスでは足りない分をパブリッククラウドで補うといったように、両者を併用することも可能です。オンプレミスとパブリッククラウドのそれぞれの特徴を踏まえることで、最適なCAE環境を構築でき、シミュレーションの高速化を実現できるのです。
製品についての
詳しい情報はこちら
資料ダウンロードはこちら
資料ダウンロード Ansys製品のGPUソルバーによる高速化事例
Ansys製品のGPUソルバーによる高速化事例
 CAE演算のためのHPCクラスタシステム
CAE演算のためのHPCクラスタシステム
本セミナーの講演資料はこちらから。
アフターレポートでは書ききれなかった情報が盛りだくさん!
■Ansys製品のGPUソルバーによる高速化事例
・Ansysのご紹介
・GPUソルバーの開発動向
・Ansys製品のGPUソルバーによる高速化事例
■CAE演算のためのHPCクラスタシステム
・HPCのうつりかわり
・HPCクラスタに必要な要素
・パブリッククラウドをHPC/CAE演算で利用する
ご質問やご相談は
お気軽にご連絡ください
最新情報などをメールでお届けします。
メールマガジン登録
このページをシェアする



