測地的畳込み形状最適化:複雑な形状を高速に最適化
企業は製品を迅速に最適化する方法を探求しています。試行錯誤による改良はコストが高く、時間がかかります。Industry 4.0の柱の一つである予測分析は、ハードウェアとソフトウェアへの大規模な投資を必要とし、現在も限られた企業のみが利用可能です。例えば、CFD(計算流体力学)をプロジェクトに導入するには、専門的なトレーニングが必須です。CFDエンジニアは、回答を導き出すまでに数時間から数日かかる場合があります。したがって、CFDを含む予測分析技術は、実践的な製品設計(CAD)と100%密接に連携しているとは言えません。
私たちは、Industry 4.0やデジタルツインのような過度に野心的で汎用的な目標や用語から距離を置くことにします。これらの概念は、実行可能すぎるほど広範なため、実行が困難な場合があるからです。技術マーケティングの用語では、デジタルツインから実行可能なデジタルツインへのシフトが最近見られます。これは、以前はその実行が困難だったことを意味するのでしょうか?
AI(人工知能)は、産業の革命、エネルギー効率と持続可能性の向上、および人間の能力の全般的な向上に、莫大な可能性を秘めています。
私たちは、製品設計プロセスを改善するためのAIの一般的な応用例を示します。AIは、上記で述べた3つの約束を果たしており、その可能性が既に実行可能なソリューション(例えば、科学的研究とソフトウェアコーディングで支援されるNeural Concept Studio(NCS))として現れています:
• 産業の革命 → AIは以前よりもはるかに多くの潜在的なデザインを探索できるため、革新的なアイデアと製品の品質における競争が促進されます
• エネルギー効率の向上 → AIは、設計プロセスに排出量や効率に関する制約や目標を組み込むことができます
• 人間の能力を強化 → AIは、例えば予測分析ツールでエンジニア全体を支援したり、オフラインの遠隔技術を会議に導入して会議体験を向上させたりできます
私たちは、幾何学的な畳込みネットワーク最適化アルゴリズムを活用し、既存のデータに基づくベンチマークと数学的基盤を交えて、複雑な産業形状の最適化を高速化する実行可能な方法を示します。
また、提案する形状最適化パイプラインにおいて、コンピュータビジョンにインスパイアされたアプローチがCADモデリングのパラメータ化ボトルネックを克服可能であることを示します。例は主に航空宇宙、海洋スポーツ、産業用自動車の形状最適化ケースから取り上げます。
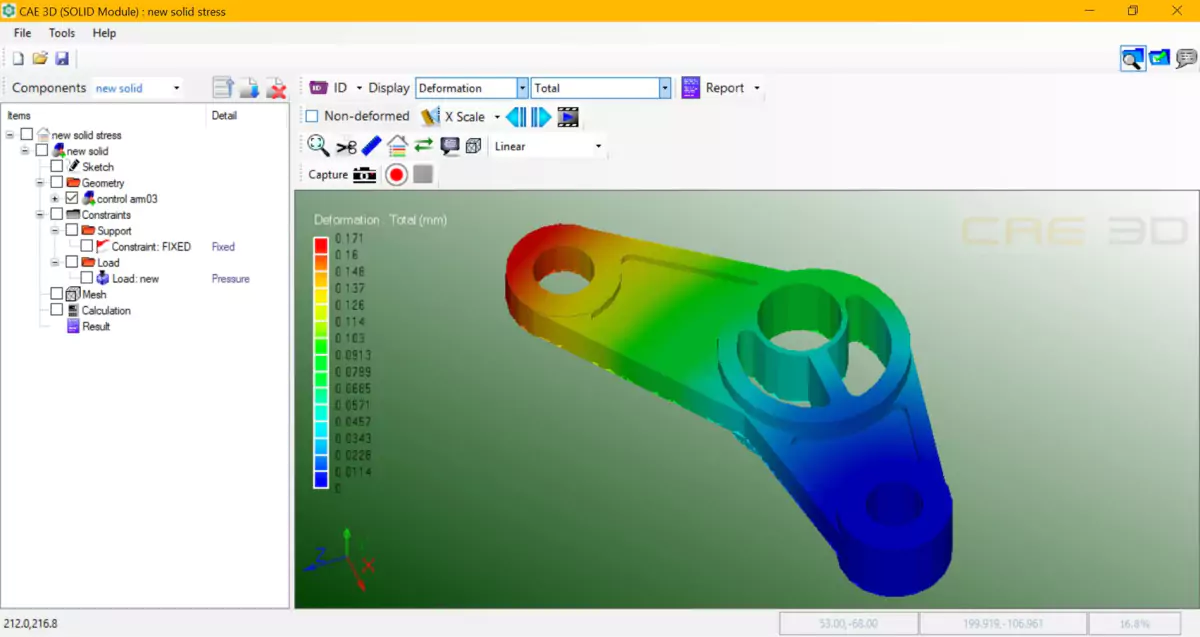
畳込みニューラルネットワーク(CNN)は、画像分析に特に有効な深層学習アルゴリズムです。コンピュータビジョンタスク(物体認識、画像分類、顔認識など)で広く活用されています。
ビジネスコンテキストでは、CNNは自動車、航空宇宙、電子機器、船舶建造など、効率向上やプロセスの自動化に活用できます。特に自動車業界におけるCNNの応用例は豊富です。
CNNは、部品の工学的な挙動に関するより広範な洞察を提供し、従来は専門知識や追加作業を要するタスクを多くのエンジニアに利用可能にすることで、企業に大きな価値をもたらします。設計事務所における代表的な追加作業の例として、産業用オブジェクトの設計時の形状パラメータのモデリングが挙げられます。提案されたアプローチは、形状パラメータを必ずしも必要とせずに形状最適化を実行できるため、既存の方法に比べて設計を加速します。「より広範な洞察」とは何を意味するのでしょうか?最適化アルゴリズムをCNNと組み合わせて使用することで、数少ない設計案を分析するのではなく、より広範な設計空間を探索し、新しい形状を設計できます。特徴認識機能と組み合わせたこのアプローチは、測地的畳込み形状最適化と呼ばれます。
測地的畳込み形状最適化により、企業は手動テストや事前に決定された少数のオプションに依存する代わりに、測地的CNNアルゴリズムを使用して、より多くの潜在的な設計を自動的にテストし評価できます。測地的畳込み形状最適化は、競争的な条件下での製品設計の改善や、排出量や持続可能性に関する新たな規制への対応を目指す企業にとって特に価値があります。
測地的畳込み形状最適化の初期例
形状の最適化とは何を意味するのでしょうか?以下の図は、空力最適化のシンプルな例です。測地的畳込み形状最適化とは、特定の形状を明示的にプログラムされていないアルゴリズムを使用して形状を変更することを意味します。むしろ、ディープラーニング技術を使用し、アルゴリズムは与えられた目標(例:空気抵抗の最小化)と変更した形状を比較し、外部ソフトウェアからではなく、実験データや CFDデータに基づく学習結果から得たシミュレーションで検証します。形状は単純ですが、この例は、既存の計算流体力学データセットのトレーニングデータとテストデータが、人間の介入なしに球面から理想的な流線形形状を生成するプロセスを完全に示しています。
EPFL(スイス・ローザンヌ)とNeural Conceptの研究者は、メッシュで記述された測地曲面上での畳込みを効率的に計算できる新しいタイプの深層畳込みニューラルネットワークを提案しました。
EPFL(スイス・ローザンヌ)のコンピュータビジョン研究所とNeural Conceptは、測地的畳込み形状最適化の応用分野において、初期段階から活発に研究を進めてきました。その代表的な成果として、2018年7月10日から15日にストックホルムで開催された第35回国際機械学習会議での発表が挙げられます。
これは、深層学習を空力形状最適化に応用した非常に早期の事例です。一般のエンジニアには2012年までほとんど知られておらず、最初の応用は2次元画像認識やテキスト・音声認識などの比較的単純な「ユークリッド」応用に限られていました。
彼らは、関心のある空力性能指標(例:CX、ドラッグ、リフト)を予測するために、測地的畳込みニューラルネットワーク(GCNN)を訓練しました。その後、このGCNN予測モデルを、形状設計を目的関数にマッピングする微分可能なブラックボックス代理モデルとして使用しました。コンピュータビジョン技術を活用し、この代理モデルに入力された形状を勾配ベースの手法で最適化することで、パラメータ非依存型で追加の形状制約を柔軟に考慮できる新たな最適化手法を提案しました。
2Dと3Dの空力形状最適化問題における実験的検証により、従来の方法が失敗した大規模なパラメータ空間において最適化が可能であることが示されました。

幾何学的な深層学習の単純な例は、より複雑な形状に拡張可能であり、これにより自動車の空力形状の最適化が実現可能となります。トレーニングデータと検証データは、方法論、CAE、研究開発(R&D)などの部門から取得可能です。これらの部門では、自動車や航空宇宙業界の組織において、年間数百件から数千件のケースが蓄積されています。これにより、ターボマシン向けの事前学習済みモデルが開発され、ユーザー(またはアルゴリズム)が複数の予測ポイントにアクセスできるようになりました。
伝統的な製品設計サイクルとAIベースの製品設計サイクルの比較
まず、伝統的な製品設計サイクルにおける典型的な実践方法を紹介します。その後、コンピュータビジョン技術を用いた形状最適化を行う提案されたワークフローと、これらの実践方法を比較します。
伝統的な製品設計サイクル
伝統的な製品設計サイクルは、概念から最終製品まで製品を開発するための反復プロセスです。このプロセスには、初期設計(1)、エンジニアリングの観点から形状の挙動を検証し機能要件を満たすかどうかを確認するシミュレーション(2)、そして機能要件が満たされるまで再設計を繰り返す(3)の3つの段階が含まれます。以下、3つの段階を詳細に説明します。
ステージ1:形状の設計
これは製品設計サイクルの初期段階であり、製品デザイナーが製品の概念設計を作成します。スケッチ、コンピュータ支援設計(CAD)ソフトウェア、3Dモデリングツールなど、さまざまなツールを使用して製品を視覚的に表現します。また、コンピュータビジョンに類似した手法であるCAS(コンピュータ支援スタイリングまたはコンピュータ支援産業デザイン)は、コンセプトフェーズの初期段階で活用されます。

初期デザインが作成されると、デザイナーはコンピュータシミュレーションを使用して製品の性能をシミュレートします。これには、有限要素解析(FEA)と計算流体力学(CFD)を用いて、製品の応力・ひずみ、熱的・流体的な挙動を分析することが含まれます。このステップは、デザイン上の潜在的な問題を特定し、必要な調整を行うのに役立ちます。
ステージ3:形状の再設計
シミュレーション結果に基づき、デザイナーは設計の変更が必要になる場合があります。これには、製品の性能を向上させるため、形状、材料、その他の要素の修正が含まれます。再設計プロセスは、製品がすべての要件と仕様を満たすまで繰り返されます。
目的関数と深層学習に基づく設計サイクル:形状最適化パイプライン
目的関数と深層学習に基づく設計サイクルは、高度な最適化技術と機械学習 アルゴリズムを活用する製品設計の新たなアプローチです。最適化パイプラインは、伝統的な設計手法と最先端技術を組み合わせるプロセスであり、高度に最適化され機能的な製品を創出します。パイプラインの最初のステップは、目的関数(OF)を定義することです。
目的関数(OF)
OFは、製品の設計目標を数学的に表現した式です。一般的には、1つまたは複数の変数「x」の最大値または最小値を達成することを目的とします。また、変数xの値を特定のレベルXに保つことは、xとXの差を最小化することを意味します。例えば、自動車設計のOFには、重量を最小化しつつ燃費効率を最大化することが含まれる場合があります。
目的関数は設計プロセスの基盤であり、最適化プロセスを導きます。OFが定義されると、次のステップはディープラーニングアルゴリズムを使用して製品の形状を最適化することです。
ディープラーニングのパイプラインへの導入
ディープラーニングアルゴリズム(例:畳込みニューラルネットワークや監督学習)は、コンピュータビジョン手法から採用されています。これらのアルゴリズムは、OFに基づいて製品の形状を分析し最適化します。これらのアルゴリズムは、数百万の異なる設計オプションを迅速に評価し、製品の最適な形状を特定できます。
シミュレーションをパイプラインに組み込む
最適化パイプラインには、最適化された形状をシミュレーションしてその性能を評価するステップも含まれます。このステップは、製品がすべての設計要件と仕様を満たすことを確認するために不可欠です。シミュレーションステップは、潜在的な設計問題を特定し、必要な調整を行うのにも役立ちます。

設計が行われている場所:形状空間(デザインスペース)
この記事で説明されたすべてのオペレーションが実施される場はどこでしょうか?これは製造と配送の上流に位置する産業プロセスにおいて非常に重要な領域です。まず、AIや畳込みニューラルネットワークなどの高度な技術が登場する前のシナリオを説明します。
Industry 4.0の約束は、物理的な対象物(製品やそれを製造する機械)に対して、デジタルで表現された物理的ツインを持つことでした。製品や機械が要件(目標と制約)を満たすことをどう保証するか?例えば、効率的、強力、耐久性があり、持続可能であることなど。製造メーカーの製品設計部門は、CAD(形状モデリング用)やCAE(形状の挙動確認用)などのデジタルツールを用いて、最適な、または相対的に最良の解決策を見出します。与えられた目標と制約から生成される設計のバリエーションを探索するため、設計者は「デザインスペース」内で移動します。
デザインスペースは、特定の設計パラメーターセットから生成可能なすべての設計の集合を指す数学的概念です。
例えば、空力学における翼形状最適化では、デザインスペースは翼幅、翼弦長、翼型形状などの設計パラメーターから生成可能なすべての翼形状の集合として定義されます。エンジニアは計算流体力学(CFD)シミュレーションを用いて形状空間を探索し、与えられた制約条件(例えば揚力対抗力比、失速角、最大揚力係数など)に対して最適な性能を提供する翼形状を特定します。
自動車の形状最適化では、サイドミラー用の形状空間とスポイラー用の形状空間がそれぞれ存在し、それぞれに非常に具体的な制約と目標が設定されています。例えば、スポイラーの形状空間はサイドミラーに比べてエアロアコースティクスに関する制約が緩やかです。一方、ミラーはダウンフォースに関する制約が緩やかです。
エンジニアは最適化アルゴリズムなどの数学的技術を用いてデザイン空間を検索し、最適な設計を見つけることができます。
方法論と定義 - 新しいディープラーニングアプローチとは?形状パラメータなしで最適化
ここでは、基本的な概念から始まり、ディープラーニングが計算を高速化し、計算負荷が極めて高い方法の準リアルタイム代替手段を提供する仕組みを解説します。
監督学習 - 基本的な説明
AIの専門家として、子供の学校に呼ばれて「お母さんやお父さんが何をしているのか」を説明すると仮定しましょう。素朴な説明は次のように進むかもしれません:
「監督学習は、コンピュータが多くの例を示されることで学習する方法です。これは、先生があなたに多くの数学の問題を解かせ、その後答えを確認して正しいかどうかをチェックするのと似ています。この方法により、あなたは類似した問題を独自に解く方法を学ぶことができます。監督付き深層学習は同様ですが、数学の問題の代わりに、コンピュータに多くの例(例えば猫や犬の写真を)示します。その後、 これらの例を用いて、新しい動物の写真を認識する方法を学習します。同じことは、車、トラック、バン、自転車などの他の物体に対しても可能です。
要するに、コンピュータにはラベル付けされた例(入力データと期待される出力)が与えられ、そのデータを用いて入力から出力をマッピングする関数を学習します。その後、コンピュータはこの学習した関数を用いて、新しい未見の入力データに対して予測を行うことができます。したがって、監督付きディープラーニングは、ラベル付けされたデータを活用して例から学習し、新しい未見のデータに対して予測を行うコンピュータの学習方法です。
監督付き深層学習 - より詳細な説明
単純な説明をした後、数学的な言語でその本質を見ていきましょう。

前のセクションで、データセットを使用して入力と出力を対応付ける深層神経ネットワークを訓練する方法を実装する点について理解しました。
したがって、ディープラーニングアルゴリズムに、入力xと出力fを結びつける関数f=f_θ(x)を見つけることを目指します。訓練プロセスでは、入力xに対して与えられた真の出力yと、ネットワークの予測出力f=f_θ(x)の差を測定する損失関数L(y,f_θ(x))を最小化します。
形式的には
• xを入力とする
• y を対応する真の出力とする
• θでパラメータ化されたニューラルネットワークの予測出力f_θ(x)を定義します。
損失関数 L(y,f_θ(x)) は、予測出力と真の出力の差を測定するために定義されます。トレーニングの目的は、トレーニングデータセット全体における損失関数の期待値を最小化するニューラルネットワークのパラメータ θ を求めることです。すなわち:
θ^ = argmin_θ (1/n) * Σ_{i=1}^n L(y_i,f_θ(x_i))
ここで、n は訓練データセットのサンプル数です。
ニューラルネットワークが訓練され、そのパラメータ θ が最適化されると、テストされます。テスト後、新しい未見の入力データに対して予測を行うことができます。予測は、入力データを訓練されたニューラルネットワークに通すことで行われ、学習されたマッピングに基づいて出力を生成します。これが「予測モデル」です。
モデルの予測精度を評価するには、テストフェーズで与えられた入力に対する真の出力と比較します。監督学習では、トレーニングセットとテストセットを使用してモデルの性能を評価します。
• トレーニングセットは、データセットのアクセス可能な部分に関するすべての知識を使用して予測モデルを訓練します。
• テストセットは、人間のみがアクセス可能な未見のデータに対して訓練済みモデルの性能を評価します。
トレーニングセットとテストセットに割り当てるデータの割合は、データセットのサイズや具体的なアプリケーションによって異なります。ただし、各セットに割り当てるデータの割合に関する一般的なガイドラインは存在します。
• 一般的な手法として、データの80%をトレーニングセットに、20%をテストセットに割り当てる方法があります。これは多くのアプリケーションにおいて良い出発点となります。なぜなら、モデルがデータ内の基本的なパターンを学習するのに十分なサイズのトレーニングセットを提供しつつ、モデルの性能を評価するのに十分なサイズのテストセットを確保できるからです。
• 別のアプローチとして、70%をトレーニングセット、30%をテストセットに割り当てるよりバランスの取れた分割方法があります。これは、データセットが小さく、モデルがトレーニングセットのサイズに敏感になると予想される場合に有用です。
トレーニング中は、過学習を避けることが重要です。ニューラルネットワークのトレーニングにおける過学習は、モデルがトレーニングデータで過度に良好な性能を示し、新しい未見のデータに汎化できない状態を指します。過学習が発生する一因は、モデルが小さなデータセットでトレーニングされ、データのノイズに過剰に適応し、根本的なパターンを捉えられない場合です。過学習を回避するための技術は複数存在します。L1やL2などの正則化技術が例です。
• L1(ラッソ正規化)は、重みの絶対値に比例する項を含みます。これにより、一部の重みがゼロに近づき、モデルから除去されます。これは特徴量選択に有用で、モデルの予測に最も重要な特徴量を特定するのに役立ちます。
• L2(リッジ正規化)は、重みの二乗に比例する項を含みます。これにより、すべての重みが縮小されますが、必ずしもゼロに近づくわけではありません。これにより、モデルの安定性が向上し、過学習が軽減されます。
その他の手法には、早期停止、ドロップアウト、そしてもちろん、より多くのデータを使用することがあります。
方法論と定義 - 畳込みニューラルネットワークとは?
「Convolutional」は「畳込み」を意味し、CNNは「畳込みニューラルネットワーク」の略です。畳込みニューラルネットワークは、画像認識や自然言語処理など、画像のようなデータ処理に広く用いられるアルゴリズムです。畳込み操作は、入力データから特徴を抽出するために使用されます。画像の場合、畳込みはエッジ、テクスチャ、形状などのパターンや特徴を識別するために用いられます。
畳込みニューラルネットワークでは、入力データが複数の畳込みフィルターの層を通過します。各フィルターはデータに対して畳込み演算を実行します。これらのフィルターは、入力データ内の特定の特性を認識するように訓練されています。データがフィルターの層を通過するにつれ、より複雑な特性が抽出されます。このプロセスは特徴抽出と呼ばれます。
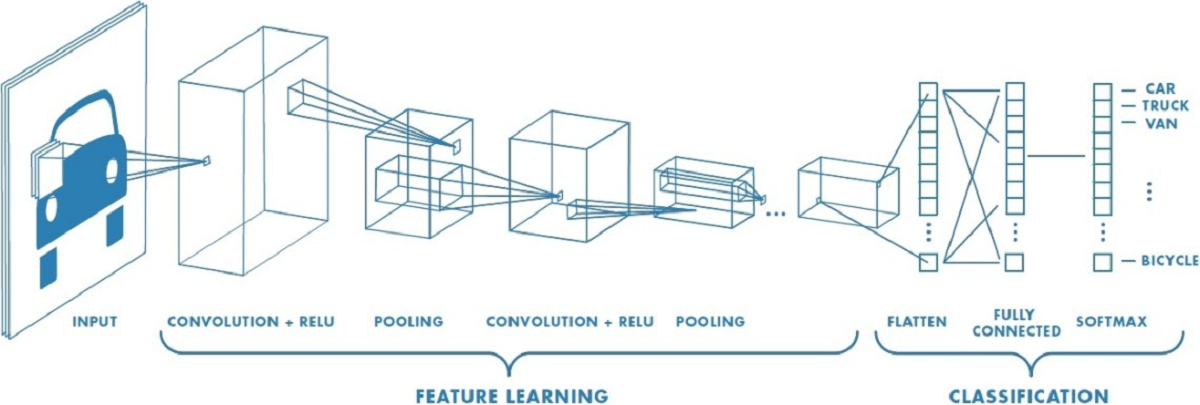
抽出された特徴量は、人工神経細胞の複数の層(完全接続層とも呼ばれる)を通過し、入力データを分類します。最後のニューロン層は、モデルの最終出力を生成するために使用されます。下の図に示すように、アトロウス・ジオ・コンボブロックは、ディープラーニングモデルで用いられる特定のビルディングブロックで、「アトロウス畳込み」と「測地的畳込み」の技術を組み合わせたものです。アトロウス畳込みは、畳込みニューラルネットワークにおいて、パラメータの数を増やすことなくフィルターの受容野を拡大する技術です。
これらの技術は、入力データから幾何学的変換に不変な特徴を学習し、入力データの多スケール情報を捕捉します。
方法論と定義 - 測地的 畳込みニューラルネットワークとは?
通常のCNNは、画像やテキストなどのユークリッド空間で定義されたデータ処理を目的として設計されています。しかし、3D形状などの一部のデータは、非ユークリッド多様体上で定義されています。Geodesic Convolutional Neural Networksは、入力データの幾何学的情報をネットワークに組み込むことで、このようなデータを処理できるように設計されています。入力データの幾何情報は、入力データの多様体上の測地線に沿って畳込み演算を行うことで、ニューラルネットワークに組み込まれます。これにより、畳込みニューラルネットワークはデータの固有の幾何構造を考慮できるようになり、非ユークリッド多様体上で定義されたデータの処理に適した構造となります。
• 通常の畳込みニューラルネットワークでは、畳込み操作は入力データ上にフィルターをスライドさせることで実行されます。
• 測地的畳込みニューラルネットワークでは、畳込み操作は入力データのマンフォルド上の測地的経路に沿ってフィルターを滑らせることで実行されます。これにより、ネットワークはデータの固有の幾何学的構造を考慮できます。
測地的CNNは、3D形状分類、表面パラメトリゼーション、3D物体検出など、さまざまなタスクに用いられています。測地的畳込みニューラルネットワークは、入力データが非ユークリッド多様体上に定義される医療画像処理、コンピュータビジョン、ロボティクスなどの応用分野でも活用されています。
CCNが人工神経ネットワークよりも優れている理由
完全接続型人工神経ネットワーク(FC-ANN)と畳込み神経ネットワーク(CNN)は、異なるアーキテクチャと異なる機能を持つネットワークです。
• FC-ANNは、各層のニューロンが次の層のすべてのニューロンと接続されたフィードフォワード型ニューラルネットワークです。FC-ANNは分類や回帰などのタスクに広く用いられ、入力データ内のパターンを認識するように訓練可能です。
• 一方、CNNは画像認識タスクに特化して設計されています。画像内を移動するフィルターからなる畳込み層を使用し、異なる空間位置で特徴を抽出します。フィルターは画像内のエッジ、テクスチャ、形状などの特定の特徴を認識するように訓練されます。CNNはまた、入力の空間次元を削減し、ネットワークのパラメーター数を減らすプール層を使用します。この記事の結論部分で、計算性能に関する詳細を で説明します。
CFDやFEAの結果の代理をCADに結びつけることは、一種の画像認識プロセスであるため、CNNがFC-ANNではなく業界標準のソリューションである理由が明確になります。
形状はどのように変更されるのでしょうか?
RBFは、データポイントのセットから関数を補間または近似する技術です。データポイントの集合 (x₁, y₁), (x₂, y₂), ...,(xₙ, yₙ) と制御ポイントの集合 (c₁, c₂), ...,(cₘ, cₙ) が与えられた場合、RBF は以下の最適化問題 (OF) を最小化することで、データポイントに適合する関数 f(x) を近似します:
f(x) = Σᵢ wᵢ * φ(||x-cᵢ||)
ここで、Σᵢは1からNまでの和、wᵢは重み、cᵢは制御点、φ(||x-cᵢ||)はラジアル基底関数(RBF)、||x-cᵢ||はxとcᵢの間のユークリッド距離です。
幾何学変形では、制御点は幾何学の形状を定義するために使用され、RBFは制御点の間で形状を補間します。重みは、異なる形状間の滑らかな移行を作成するために最適化され、幾何学の滑らかで連続的な変化を実現します。
AIアルゴリズムのベンチマーク - Kriging法
Krigingは、鉱山業や石油・ガス探査事業において有用な手法です。この手法は、1917年から2013年まで(ディープラーニング時代の幕開け直後)に活躍した南アフリカの鉱山エンジニア兼統計学者、ダニエ・クリゲにちなんで名付けられました。クリゲの代表的な著作は「A statistical approach to some basic mine valuation problems on the Witwatersrand」( の全文は付録に収録)です。Krigingは、近傍の地点で測定された値に基づいて、ある地点における変数の値を推定する手法です。Krigingは、近傍の地点における変数の値を基に、ある点における変数の値を予測するために統計モデルを使用します。
Krigingの用途
Krigingは、推定値の平均二乗誤差を最小化する線形補間手法です。これは、空間と時間における変数の振る舞いを記述する確率過程(数学的モデル)に基づいています。Krigingの主要な仮定は、対象変数が「バリアグラム」と呼ばれる関数で特徴付けられる定常確率過程の実現値であることです。バリアグラムは共分散です。実践的には、フィールド内の2つの地点間の空間的依存度の程度を記述します。以下のセクションで数学的な詳細に深く掘り下げていきます。KrigingがCNNとどのように異なるかを理解したい場合は、次のセクションをスキップして「KrigingがCNNのように機能しない4つの基本的な理由」に進んでください。
Krigingの数学
Krigingによる未観測地点 z₀ における変数 z の推定値は、次式で与えられます:
z₀ = Σᵢ(wᵢ * zᵢ)
Σᵢ は i の和であり、重み wi は方程式系の解によって決定される(j は j の和を表す);
Σⱼ (wᵢ * C(zᵢ, zⱼ)) = C(z₀, zⱼ)
• C(zᵢ,zⱼ) は、位置 i と j における観測値 zᵢ と zj の共分散を表します。
• C(z₀,zⱼ) は、サンプリングされていない位置 z₀ と j 番目の観測値 zⱼ 間の共分散を表します。
KrigingがCNNのように機能しない4つの理由
Krigingは、鉱山開発や石油・ガス探査などの多くの実践的な応用において優れた性能を発揮しますが、自動車、航空宇宙、電子機器、機械、船舶建造、医療機器などの産業における製品設計においては、(geodesic) convolutional neural networks (GCNNs) と比較していくつかの欠点があります。
1. より複雑:Krigingは、変異関数を推定し、重みを決定し、予測を行うために、多大な計算リソースを必要とします。一方、CCNは、ニューラルネットワークベースのモデルであり、はるかに少ない計算リソースで訓練し、予測に利用可能です。
2. 柔軟性の欠如:Krigingは、基盤となるプロセスが定常的(かつ等方性)であるという仮定に基づいています - これは必ずしも成立しない場合があります!一方、CCNは基盤となるプロセスに関する仮定を必要とせず、多くの問題やデータタイプに適用可能です。したがって、CNNはより汎用性が高いと言えます。
3. 非線形性の処理能力が低い:Krigingは線形補間手法であり、データ内の非線形関係を処理するのに適していません。一方、CNNはニューラルネットワークであるため、非線形関係をモデル化できます。これはCNNがKrigingに対して持つ主要な利点です。
4. 大規模データセットへの対応能力が低い:Krigingは、計算複雑さと方法の制限のため、大規模データセットへの対応が比較的困難です。一方、GCNNは、大規模データセットへの対応に最適であり、高次元データでのトレーニングが可能です。
Krigingは自動車の空力学にどのように実装されるか?
公平性を確保するため、Krigingを用いた空力問題の解決アプローチを説明します。前節で示したように、Krigingは非線形性と高次元データに関する制限があり、車の空力モデルを に再現する最良の方法ではない可能性があります!したがって、非線形性や高次元データに対応できる他の手法、例えばCCNや機械学習モデルを検討することが重要です。自動車の空力学にKrigingを実装するには、以下のステップが必要です:
1. データ収集:最初のステップは、車の表面のさまざまな位置で、空気抵抗やドラッグ係数などの関心変数のデータを収集することです。このデータは、風洞試験や計算流体力学(CFD)シミュレーションを通じて収集できます。
2. バリアグラムの推定:前のステップで収集したデータに基づき、次にバリアグラムを推定します。バリアグラムは、関心のある変数の空間相関構造を記述します。これには、セミバリアグラムやKrigingバリアグラムなどの実験的バリアグラム手法が使用できます。
3. データ補間:前項で推定したバリアグラムを使用し、Krigingは車の表面の未測定位置で対象変数を補間します。各サンプルの重みは、推定されたバリアグラムと方程式系を解くことで計算されます。
4. 予測:補間されたデータを用いて、Krigingは車の表面上の任意の地点で対象変数を予測できます。これらの予測は、車の空力特性を最適化し、空気抵抗やドラッグを低減するのに役立ちます。
最後に、Krigingによる予測を測定データと比較して検証することが重要です。これは、同じ位置での風洞実験やCFD結果との比較により行うことができます。
形状最適化アルゴリズムのベンチマーク
最適化において実装され、現在も人気の高い3つの方法をレビューし比較します。これにより、最適化アルゴリズムのベンチマークが可能です。
遺伝的アルゴリズム(GA)
GAは、形状最適化に遺伝的アルゴリズム(自然選択にインスパイアされた最適化技術)を用いる、広範で比較的実装しやすいアプローチです。GAは候補解の集団を作成し、適応度関数に基づいてその適応度を評価します。その後、遺伝的操作(例えば「交配」や「突然変異」)を反復的に適用します。これにより、集団はより良い解 towards より良い解へと進化していきます。
GAは、大規模で複雑な探索空間におけるグローバル解の探索に優れています。しかし、GAは計算コストが高くなる傾向があり、特に高次元問題では顕著です。さらに、GAは初期個体群の選択や遺伝的演算子の選択に敏感であり、これらが最終解の品質に影響を与える可能性があります。
接合微分
随伴微分は、最適化関数(OF)の勾配を効率的に計算する技術です。勾配は設計変数に対して計算されます。随伴法は、元の正方向方程式に関連する随伴方程式を解くというアイデアに基づいています。随伴微分は大規模最適化問題において非常に効率的です。線形問題と非線形問題の両方を扱うことができます。
ただし、接合微分は接合方程式を解く能力を必要とします。これは計算コストが高く、制約条件や非微分可能な関数に対処する際に困難を伴う場合があります。
接合法は数値解析において偏微分方程式(PDE)を解くために使用されます。これは、元の正方向方程式に関連する接合方程式を導入するアイデアに基づいています。接合方程式は、元の式を転置し、時間または空間の方向を逆転させることで導かれるPDEです。
随伴法の例として、固体物体内の熱分布を記述する熱方程式が挙げられます。熱方程式の「前方」(物理空間)方程式は次のように表されます:∂u/∂t = α∇ ²u、ここで:uは空間と時間における温度分布、t は時間、αは固体物体の熱拡散率です。演算子は次のように定義されます:∂/∂tは時間微分、∇ は空間微分(勾配)記号、∇ ²はラプラス演算子です。
熱伝達に詳しくない人にとって、この式は直感的に理解しやすいです。例えば、拡散係数 α の大きい物体は、拡散係数 α の小さい物体よりも早く加熱されます(∂u/∂t が大きい)。(注:他の条件はすべて同じです!)次に、逆方程式を導出するために、前方方程式の転置を取り、時間の方向を逆転させます:∂u*/∂t* = -α∇ ²u*、ここで:u* は逆変数、t* は逆時間です。
代理モデルを用いたベイジアン最適化
ベイジアン最適化は、確率モデルを用いて候補解の性能を予測し、設計空間内の有望な領域への探索を導く技術です。代理モデルは目的関数を近似し、最適解に収束するために必要な関数評価の回数を削減します。このアプローチは、目的関数の評価がコストが高い場合に特に有用です。ただし、高次元の問題では計算コストが高くなる可能性があります。また、サロゲートモデルの選択に敏感であるため、最終的な解の品質に影響を与える可能性があります。
確率論に不慣れな方向けの補足説明:「ベイジアン」は「ベイジアン最適化」において、最適化プロセスにベイジアン確率論を用いることを指します。ベイジアン確率論では、確率は単一の値ではなく確率分布で表されます。これにより、事前知識や不確実性を分析に組み込むことが可能です。ベイジアン最適化では、最適化対象の目的関数は確率分布を持つランダム変数として扱われます。この分布は新しいデータが取得されるたびに更新され、最適化アルゴリズムはこの情報を活用して最適な解への探索を導きます。
事例:NACAプロファイルとその最適化
航空工学に馴染みのない方のために、NACAプロファイルについて説明します。
NACAプロファイルは、1930年代にアメリカ合衆国の航空諮問委員会(NACA)によって開発された翼型です。シンプルな形状と低速域での優れた性能で知られています。
NACA翼型は、翼型の形状を表す4桁の数字コードで定義されます。
• 最初の数字はキャンバー(翼型の表面の曲率)を表します。
• 2番目の数字は最大曲率の位置を表します。
• 3番目と4番目の数字は翼型の厚さ分布を表します。
深層学習の観点から興味深い点として、NACAプロファイルのCFD計算データセットが存在します。これらのデータセットには、異なる迎え角、レイノルズ数、マッハ数におけるNACA翼周りの流れのシミュレーション結果が含まれています。リフト係数、ドラッグ係数、圧力分布、流れ速度などのデータが含まれる場合があります。
一部のデータセットは公開されています。例えば、NASAはNACA翼型のCFD計算データセットを構築しており、異なる迎角とレイノルズ数におけるNACA翼型周囲の流体流れのシミュレーション結果が含まれています。

大規模メッシュにおける形状変更
形状を表現する頂点の数が多い場合、従来の方法は計算負荷が高くなる可能性があります。そのため、形状の潜在パラメータの表現が求められます。
NACAプロファイルの場合、標準的な産業パラメータ化が存在します。以下の図に示す例では、下図の左から右へ移動するにつれ揚力係数Clを増加させつつ、上図の上から下へ移動するにつれピッチングモーメントCmを増加させることを目指しています。
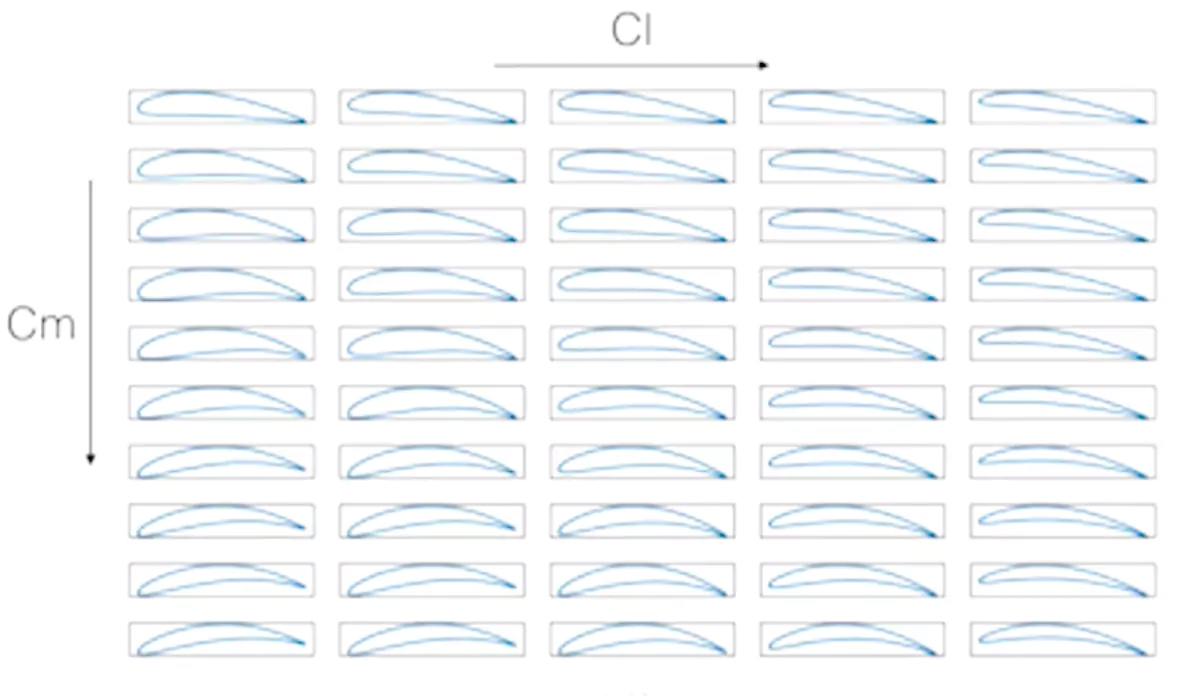
上記の実験の要点は、確立された知識体系が存在しない形状、つまり産業コンテキストにおける変数目標と制約を持つ形状の設計に、R&DやCAE部門で生成されたトレーニングデータを活用して移行できる点にあります。
オンライン圧力とドラッグ予測におけるGCNNの応用。
さらに、詳細なホワイトペーパーを基にしたUAV設計最適化など、複数の事例があります。
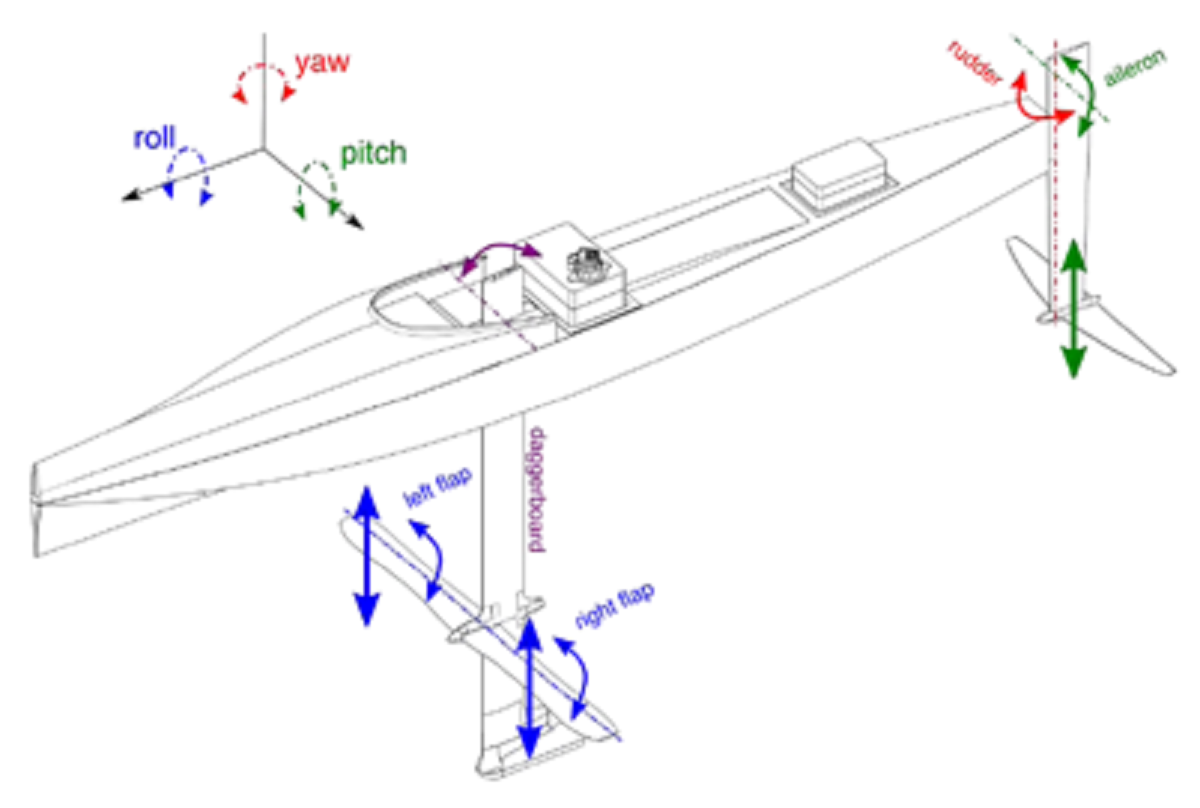
事例:ハイドロフォイルとその最適化
ハイドロフォイルは、船の船体に翼状の構造物を取り付け、船の船体を水面から浮上させるように設計された構造物です。これは高速時において重要です。

ハイドロプレーンレースでは、ハイドロフォイルは船体の底部に装着され、高速時に船体を水面から浮上させ、船が水面の上を「飛行」するようにします。これにより、抵抗が減少して速度が向上し、船は水面下に船体がある状態よりも速く移動できます。
カタマランレースでは、ハイドロフォイルは船体の両側に取り付けられ、高速で船体を水面から浮かせます。これにより、抵抗が減少して速度が向上し、船体は水面下にある船体だけで航行する場合よりも速く移動できます。
アメリカのマリンチーム「BMW Oracle Racing」は、2010年にスイスのチーム「Alinghi」を破り、第33回アメリカズカップで優勝しました。アメリカズカップは、最も古い国際スポーツトロフィーの一つであり、セーリングレースの優勝者に授与されます。最終的に両チームは、90フィートの翼帆を備えた巨大トリマランヨットでレースを行うことに合意しました。BMW Oracle Racingのトリマランは、伝統的なアメリカズカップヨットで使用される帆の2倍以上の大きさの rigid 翼帆を採用した独自のデザインが特徴でした。この独自のデザインは、BMW Oracle Racingにアリンギチームに対して大きな性能上の優位性を与えました。最終レースは2010年2月14日にバレンシアで開催されました。BMWオラクル・レーシングのトリマラン(USA 17)は、アリンギ5を2分22秒差で破り勝利を収めました。この勝利は、アメリカズカップの歴史上初めてマルチハル船がトロフィーを獲得した瞬間でした。
水翼の流体力学特性を最適化することは、その形状設計の鍵となっています。しかし、実際の計算流体力学(CFD)技術はナヴィエ・ストークス方程式の解きに依存しており、これはあらゆる異なる形状に対して行わなければならないため、計算負荷が高く、制約も多い課題です。実際、古典的なCFD技術では、幾何形状の変更は限定的で、最終形状に到達する前にテストできる設計はごくわずかです。これらの制限が、本プロジェクトの主な理由と動機となりました。本研究では、複数の自由度を同時に変更できるため、より複雑な幾何形状をテスト可能となり、各幾何パラメーターを微調整できることが示されます。
本研究では、EPFLのHydrocontestレースボートにおける水翼形状の数値最適化手法を適用しました。Geodesic Convolutional Neural Network技術(Baqué et al., ICML 2018)に基づく数値最適化手法が、従来の手動最適化形状よりも水翼の設計を改善することを示しました。著者らはまず、XFoil CFDソルバーを使用して、より単純な2次元ハイドロフォイルプロファイルの最適化においてこのアプローチの潜在性を示しました。その後、高度な非次元化揚力面解析コードであるMachUpProを使用して、この方法を3次元形状の最適化に拡張しました。
閉めの質問:ディープラーニングは計算を高速化するか?そしてどのように?
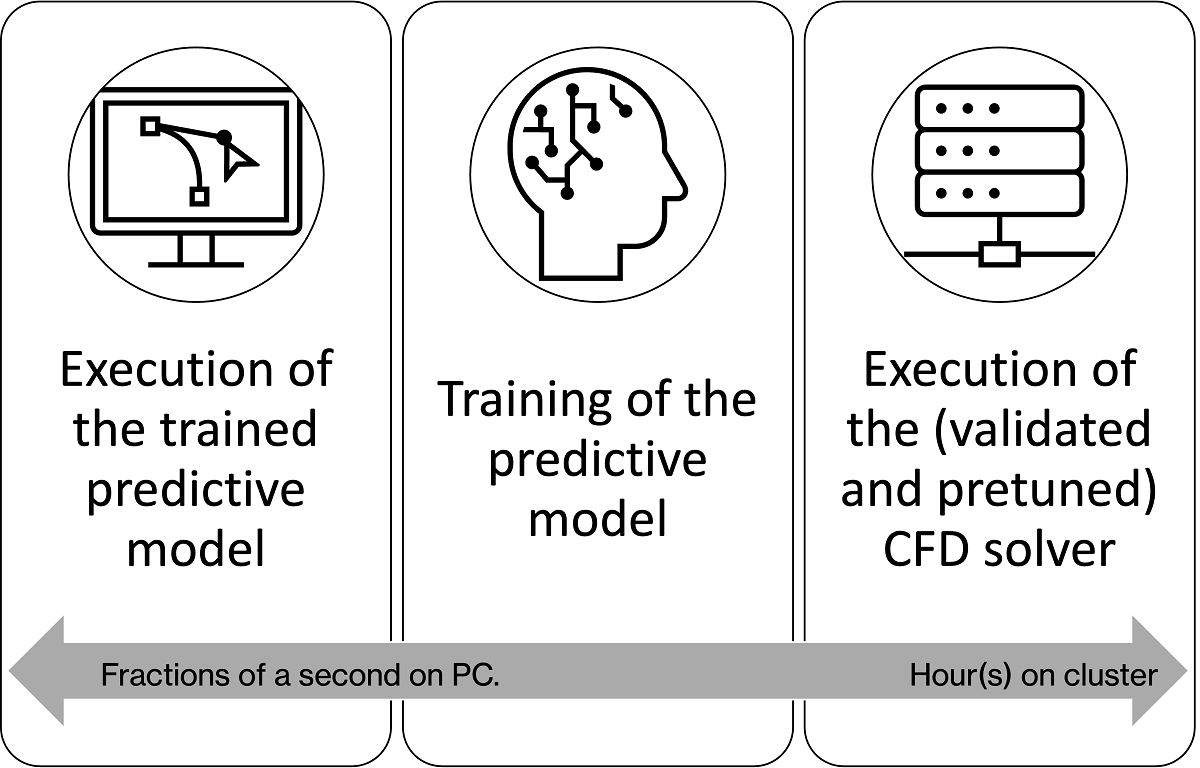
私たちは、ニューラルネットワークが空力問題の解を近似するように訓練できることを確認しました。また、測地的CNNを基盤としたNC Shapeのようなソリューションを使用すれば、CAD読み込みからCAE出力までの全体プロセスを完全に代替する可能性もあります。
ニューラルネットワークのトレーニングフェーズは計算コストが高くなる場合がありますが、一度トレーニングが完了すると、ニューラルネットワークは比較的迅速に予測を行うことができます。トレーニングが完了すると、伝統的なCFDシミュレーションよりもはるかに高速に解決策(圧力、速度、その他のフィールド)を予測できます。例えば、32個のCPUコアで3時間かかるシミュレーションを、単一のコアで0.3秒まで加速できます。ネットワークのトレーニングに必要な投資は、専用GPU上で約6~8時間程度となる可能性があります。
「Big O」表記(注:以下の内容は著者の推測であり、深い研究に基づくものではありません):
• 計算流体力学(CFD)シミュレーションの時間複雑度は、一般にビッグオー表記でO(n³)またはそれ以上とされています。ここでnはシミュレーションで使用される格子点またはセルの数です。これは、CFDシミュレーションが通常、格子上で偏微分方程式(PDE)を解くため、計算負荷が高いからです。
• ニューラルネットワークのトレーニングの時間複雑度は、ネットワークをトレーニングするために必要な反復回数(エポック)と、各反復に要する時間で測定されます。各反復の計算量は、ネットワークのパラメーター数に依存し、これは層の数や各層のニューロン数などの要因と関連しています。深層学習モデルのトレーニングの計算量は、ネットワークのパラメーター数nに比例するO(n)であることが多くあります。
• CNNは、フィルターとプールリングにより、伝統的な神経ネットワークに比べて速度向上を実現します。
• フィルターは、入力画像から特徴を抽出する技術です。フィルターは通常、画像上を移動する小さな行列であり、各位置で局所的な画像パッチと行列のドット積を実行します。ドット積の結果はネットワークのパラメーター数を削減します。また、入力の空間次元を削減することもでき、これによりネットワークの時間複雑度を低減する可能性があります。
• プールは、CNNで入力の空間次元を削減する技術です。通常、畳込み層の後に適用され、入力画像をダウンサンプリングし、小さなピクセルのウィンドウの最大値または平均値を抽出します。このプロセスはネットワークのパラメーター数を削減し、入力の空間次元を削減することで、再びネットワークの時間複雑度を低減します。
• 訓練済みのニューラルネットワークの実行時間複雑度は(つまり訓練後)、 ネットワークのパラメーター数nに対してO(
要約
コンピュータビジョンにインスパイアされたアプローチが、ドラッグと圧力予測を強化することで製品設計部門の効率を向上させ、最適化を進める方法を示しました。また、Krigingのような伝統的な手法と、畳込みニューラルネットワークが提供する追加価値についても確認しました。より具体的に、測地的畳込みネットワークの動作と、2Dおよび3Dケースにおける畳込み形状最適化を支援する方法を示しました。訓練されたニューラルネットワークの実行速度を推定し、勾配ベースの手法(ニューラルネットワークの訓練と形状最適化の両方)を活用し、微分可能性の性質を活かした高速最適化ループの実現可能性を示しました。データ駆動型である神経情報処理システムは、初期形状から出発し、これまでに見たことのない形状を含む広範な形状空間内で実行可能な形状を見つけることができます。この新しい代理モデル手法はCAEの代理モデルであり、勾配ベースの手法と組み合わせることで、任意の複雑な形状を管理する可能性を有する完全な閉ループソリューションを提供します。
今後の展望
これまで示した内容に関する「進化」として、少なくとも4つの方向性を強調したいと考えています。
1. 統合:CAD形式(ネイティブファイルなど)とのより緊密な統合
2. 事前訓練済みモデル:データセットの構築が十分成熟していない組織や、事前投資を避けつつCFD CAE技術を活用したい組織向けに、特定アプリケーション向けの事前訓練済みモデルの提供
3. データ融合:産業用グレード、高精度R&Dグレード、実験データなど、複数のレベルのCFD、固体力学、電磁気データの一元化
4. 不確実性推定:形状を変更する際、予測モデルが形状空間の未踏領域に入る可能性があります。予測を継続する代わりに、予測の信頼性を推定し、必要に応じて ground truth を参照して追加の予測を取得し、新しい設計空間の領域で予測モデルを校正することが有用です。
上記のポイントはNeural Conceptの計画ではありません。すべて既に実装可能であり、その実装はユーザーのビジネスケースに依存します。
例:
1. CAD-PLM統合は、製品エンジニアリング部門にとって特に興味深いテーマです。
2. 事前トレーニング済みモデルは、トレーニングデータセットのサイズを最適化する必要がある企業にとって興味深いケースとなる可能性があります。
3. データ融合は、複数のデータソースを持つ企業にとって非常に魅力的です。例えば、風洞実験施設を管理するマネージャーが、風洞実験の40年間のデータとCFDの20年間のデータを両方活用したい場合などが該当します。
4. 不確実性推定は、最適化プロセスにおける信頼性の高い予測を実現し、検証済みの最終的な工業形状を得るために重要です。
付録
XFoil CFD ソルバー
XFoilは、翼やブレードの断面形状であるエアロフォイルの解析に特化した計算流体力学(CFD)ソルバーです。XFoilは2次元パネル法ソルバーであり、エアロフォイルの表面を小さな平らなパネルに分割し、各パネルで流れ方程式を解くことで、エアロフォイル周囲の流れを解析します。XFoilは、翼型周囲の流体をモデル化するナヴィエ・ストークス方程式を使用しています。この方程式は、流体の流れの挙動を記述する一連の方程式です。ナヴィエ・ストークス方程式は、パネル法(流れを平らなパネルの系列としてモデル化する方法)や渦格子法(流れを渦の系列としてモデル化する方法)など、さまざまな方法で解かれます。XFoilは、亜音速および超音速流れ、異なる迎え角、異なるレイノルズ数など、幅広い条件下で翼型の空力性能(揚力、抗力、失速特性など)を正確に予測する能力で知られています。XFoilは既存の翼型の性能を分析し、特定の性能特性を有する新しい翼型を設計することも可能です。
参考文献 - gCCNと最適化に関する基本文献
以下の論文は画期的なものです。この論文の発表以来、Neural ConceptはNCSユーザー向けに多くの新たな技術と実用的な機能を導入してきました!
「Geodesic Convolutional Shape Optimization」Pierre Baqué, Edoardo Remelli, François Fleuret, Pascal Fua (ref. arXiv:1802.04016)
要約:空力形状最適化は多くの産業応用を有します。しかし、既存の手法は計算負荷が非常に高いため、一般的な工学実践では、手動設計した形状の限定的な試行か、数少ない自由度でパラメータ化可能な形状に限定される傾向があります。本研究では、複雑な形状を迅速かつ正確に最適化する新たな手法を提案します。この目的のため、著者らは流体力学シミュレーターを模倣する測地的畳込みニューラルネットワークを訓練します。このアプローチの実用性を実現する鍵は、元の形状をポリキューブマップで再メッシュ化することです。これにより、計算をCPUではなくGPU上で実行可能になります。ニューラルネットワークは で構成され、形状パラメータに対して微分可能な目的関数を定式化します。この目的関数は勾配ベースの手法で最適化され、標準問題において最先端手法を5~20%上回る性能を示します。さらに重要な点は、このアプローチが従来の方法では対応できなかったケースにも適用可能であることです。
参考文献 - Krigingに関する基本文献
以下の論文はKrigingの基礎となるものです:「鉱山評価の基礎問題に対する統計的アプローチ:Witwatersrand鉱山を例に」、Danie G. Krige、南アフリカ化学・金属・鉱山学会誌 52 (6): 119–139 (1951年12月)
本記事は、Neural Concept社の下記ウェブサイトに公開されている記事「Geodesic Convolutional Shape Optimization: Optimize Complex Shapes Fast | Neural Concept 」を日本語訳したものです。
Neural Conceptについて
Neural Conceptは、エンジニアリングを強化するためのAIディープラーニングアルゴリズムを開発しています。研究開発サイクルの高速化、製品性能の増強、次世代におけるエンジニアリング課題の解決により、これまでに80社以上の顧客の製品設計方法を革新してきました。同社は2018年、スイスのEPFLにある一流のAI研究室で設立されました。私たちは30人以上のメンバーで構成され、インテリジェンスで産業エンジニアリングの未来を変革するというビジョンに向かい全力を尽くしています。詳しくはこちら
- ※記載されている製品/サービス名称、社名、ロゴマークなどは該当する各社の商標または登録商標です。
深層学習AI による解析結果予測ソリューション Neural Concept Studio
Neural Concept Studioは、深層学習AI技術をベースとした、SaaS型解析結果予測ソリューションです。3D形状や解析結果からAIモデルを構築、AIによる形状評価は最短数ミリ秒で完了します。形状パラメータが異なる部品や過渡現象にも適用でき、転移学習にも対応します。