HOME技術コラムDataSpiderで実装するデータクレンジング ~データウェアハウスやBIへの連携~
データウェアハウスとは、企業が持つさまざまなデータを一元管理するシステムのことです。大量のデータの中から条件に該当するものを抽出したり、分析しやすい形にデータを整理・保管したりと、データ管理や活用の問題を解決することが可能です。
また、長期的なデータ保管にも適しており、一定期間のデータを蓄積し、変化の傾向を把握するのに役立ちます。
◎主な特徴
BI(ビジネスインテリジェンス)とは、企業の情報システムなどで蓄積される様々なデータを、利用者が自らの必要に応じて分析・加工を行うという、データに基づいた意思決定が行えるようにデータ活用を支援する取り組みのことです。蓄積したデータを分析することで、顧客の傾向などを把握することができ、効果的なマーケティングに活用できます。
◎BIのプロセス
データクレンジングとは、データの誤登録や表記の不統一など、データの不備や重複を修正する作業のことです。例えばデータウェアハウスやBIツールにデータを格納する前には、データクレンジングを利用し、収集したデータを抽出しデータを利用しやすい形に変換する必要があります。
データクレンジングを行うことで、下記のような様々なメリットがあります。
| メリット | ・データ分析精度の向上 |
|---|---|
| ・業務の効率化・生産性の向上 | |
| ・データ維持コストの削減 | |
| ・データ統合の促進 | |
| ・コストの削減 |
データクレンジングはDataSpiderのマッピングでも行うことができます。
今回はDataSpiderを使用して、マッピング内でデータクレンジングを行う手順を説明します。
処理フローと処理内容は以下の通りです。
| 読み取り |
|
|---|---|
| クレンジング |
|
| 書き込み |
|
今回連携先となる会員テーブルの、ファイル連携前の中身は以下の通りです。
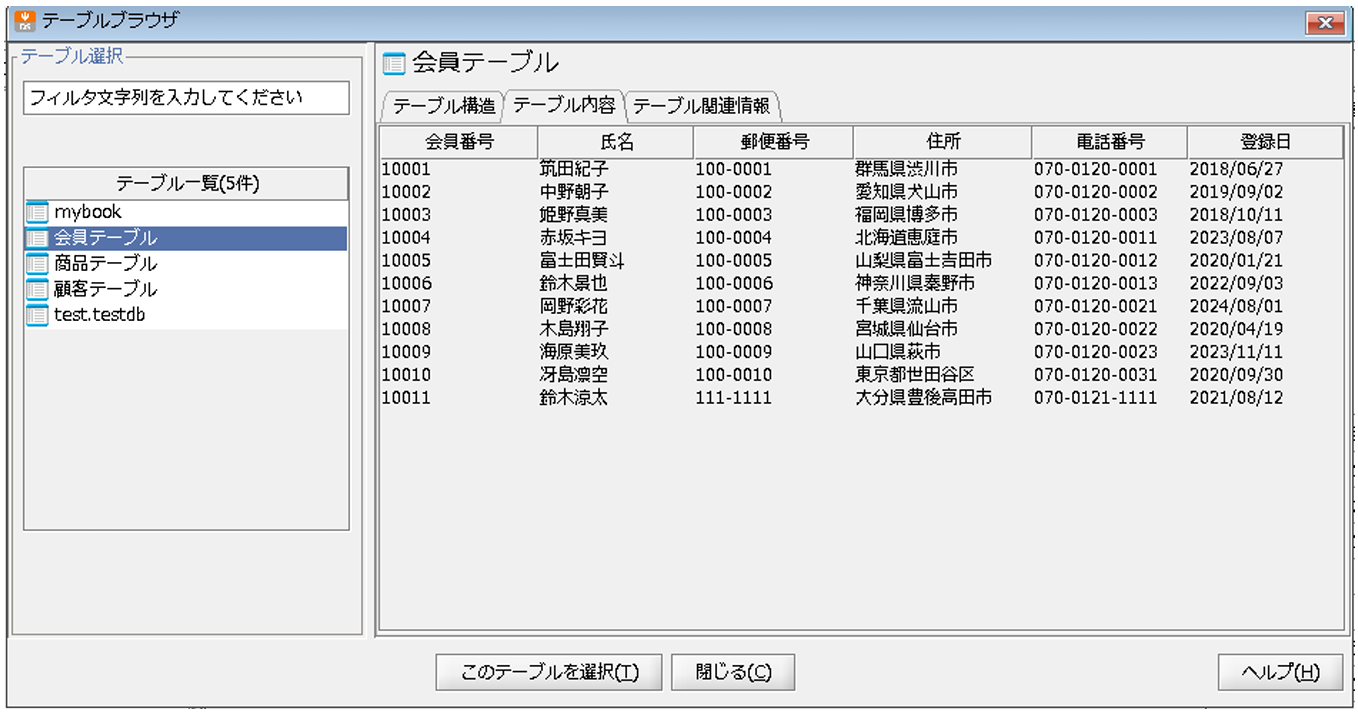
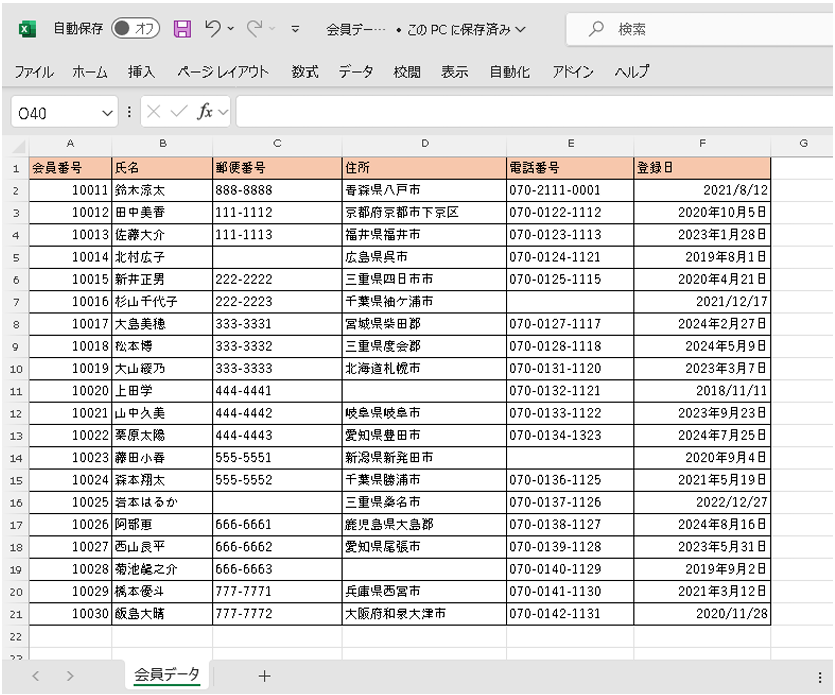
また、今回連携するCSVファイル「/data/work/test/会員データ.csv」の内容は以下の通りです。
連携元データは、下記の特徴があります。
※会員番号、氏名、登録日は入力必須項目とします。
[プロジェクト名]:任意のプロジェクト名
[スクリプト名]:任意のスクリプト名 
入力元データとなるCSVファイルの読み取り設定を行います。
ツールパレットから[ファイル]-[CSV]-[CSVファイル読み取り]を、スクリプトキャンバスにドラッグ&ドロップします。 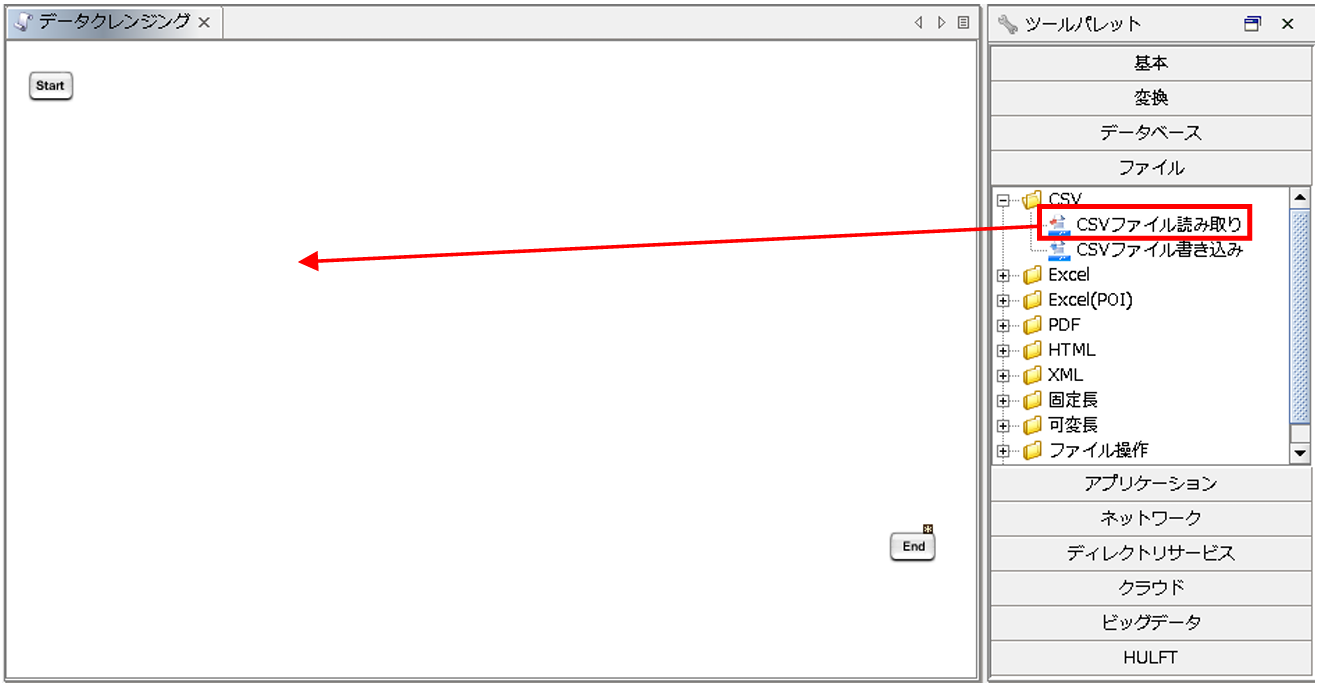
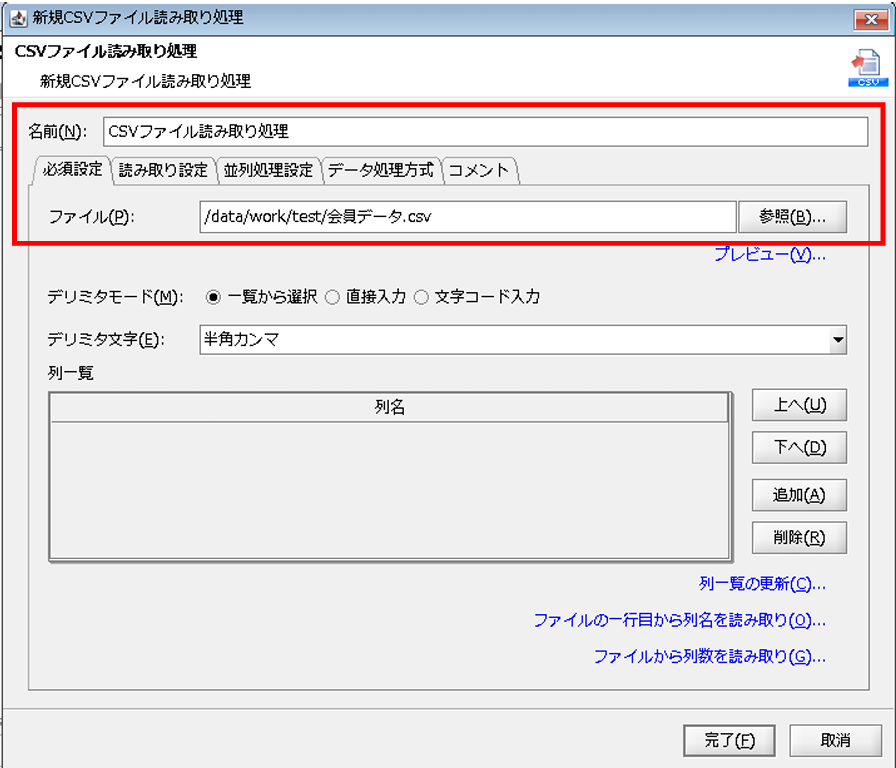
「CSVファイル読み取り処理」プロパティ設定ダイアログで、以下の通り設定を行います。
◎必須設定
[名前]:コンポーネント名
[ファイル]:読み取り対象ファイルの格納先フォルダ/ファイル
◎読み取り設定
[エンコード]:読み取り対象ファイルのエンコード
[最初の行は値として取得しない]:ファイルの読み取り開始行をデータとして扱うか選択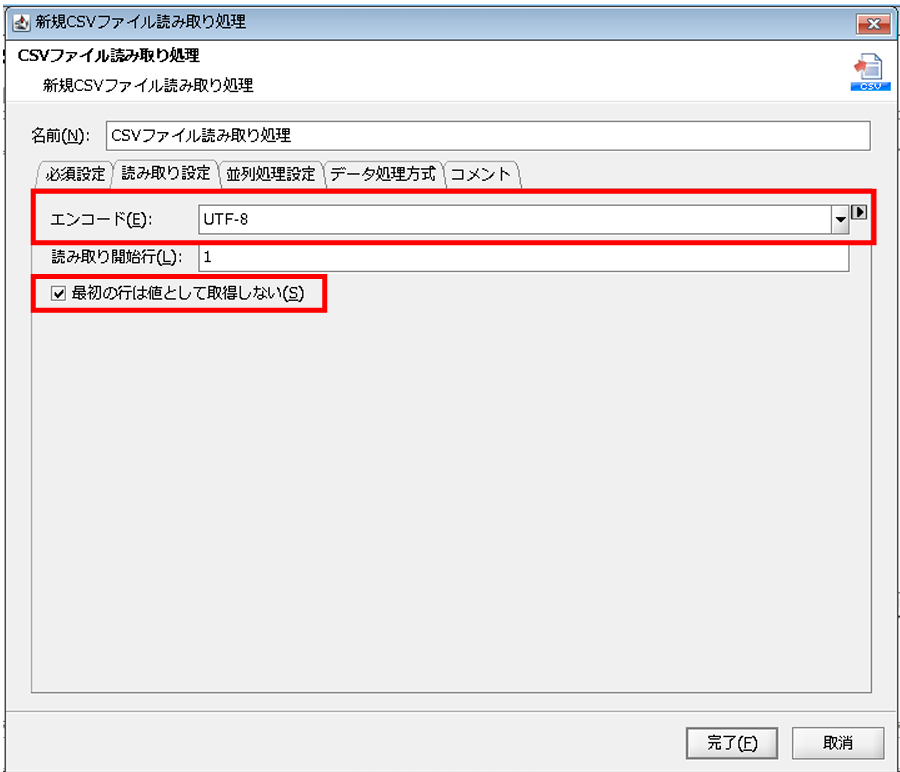
[ファイルの一行目から列名を読み取り]をクリックします。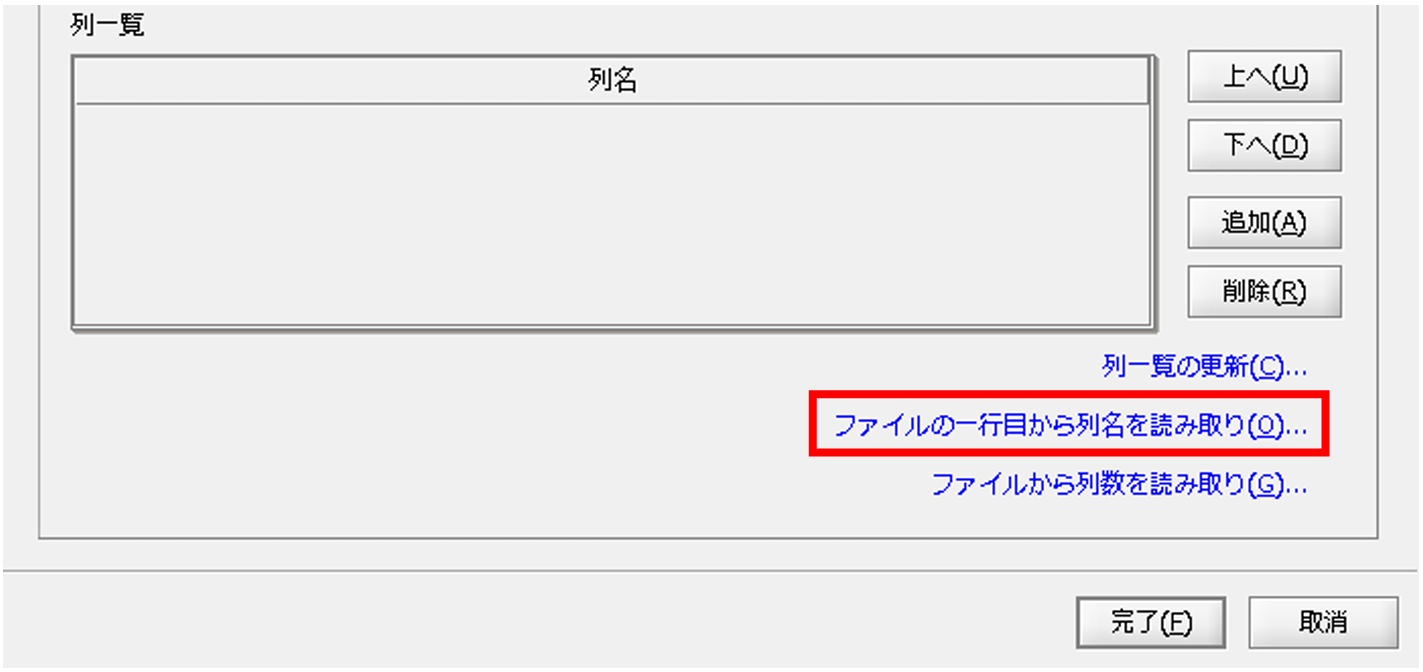
ファイルの選択画面が表示されるため、今回のデータ入力元CSVファイルである「/data/work/test/会員データ.csv」を選択し、[表示キャラセット]をUTF-8に変更します。
ファイルの中身が正常なことを確認し、[開く]を押下します。 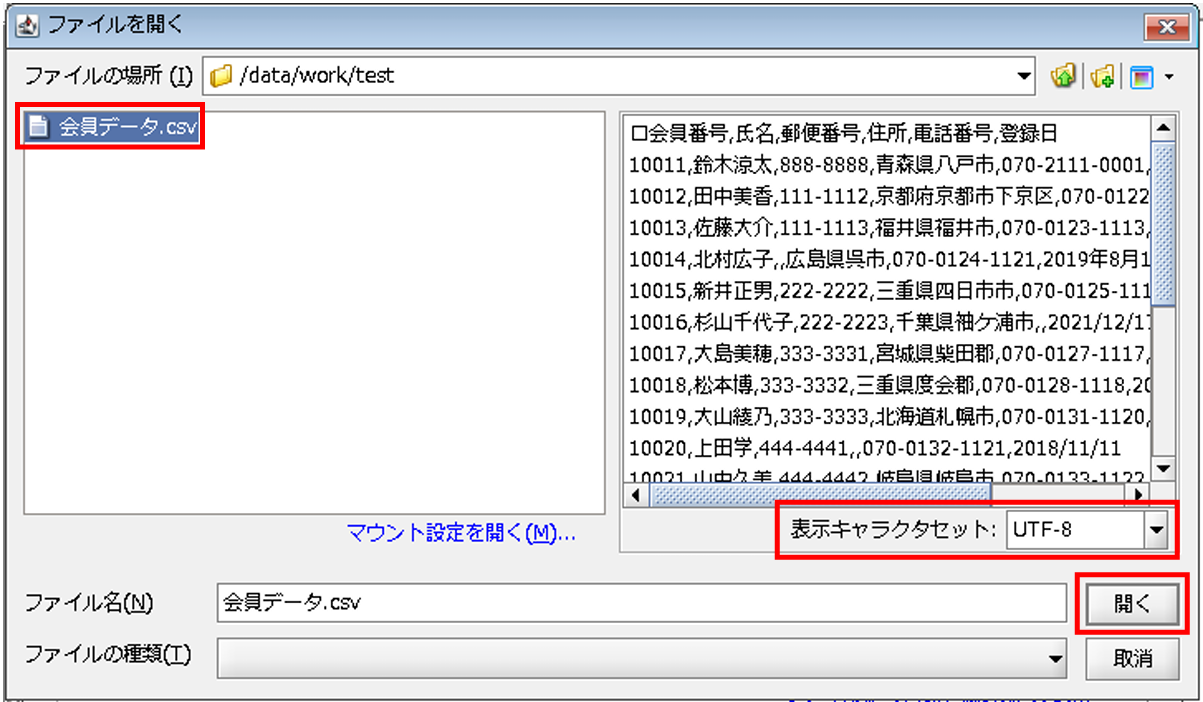
列一覧に列名がセットされます。 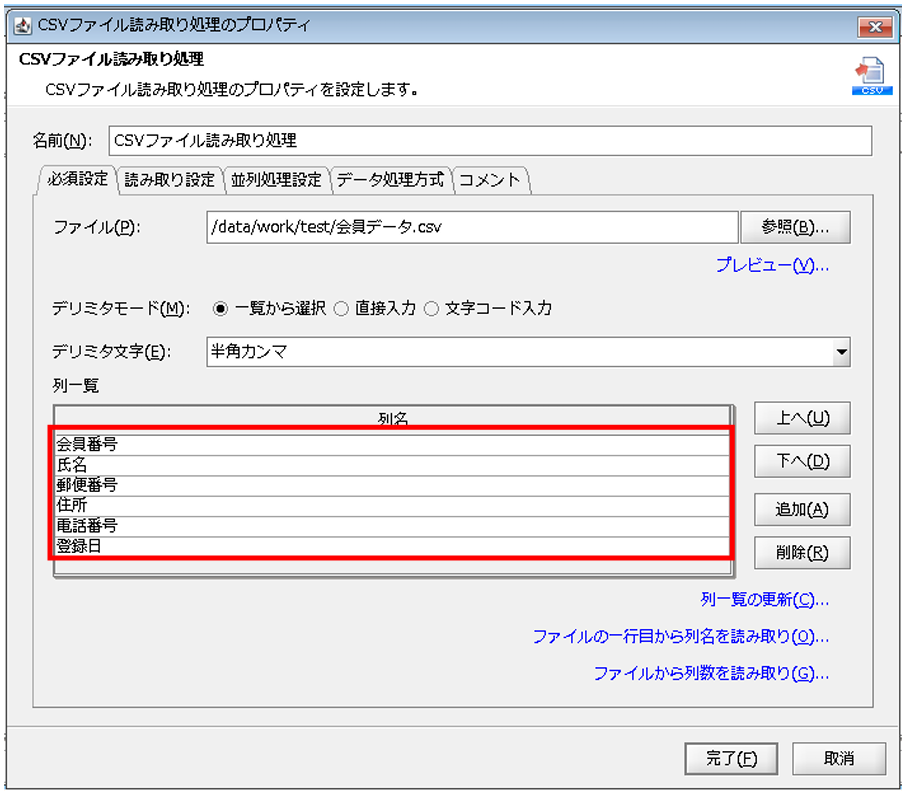
[完了]を押下すると、プロパティ設定ダイアログが閉じ、「CSVファイル読み取り処理」アイコンがキャンパスに配置されます。 
読み取ったデータを書き込む、データベースの設定を行います。
ツールパレットから[データベース]-[PostgreSQL]-[テーブル書き込み]を、スクリプトキャンバスにドラッグ&ドロップします。 
「テーブル書き込み処理」プロパティ設定ダイアログで、以下の通り設定を行います。
◎必須設定
[名前]:コンポーネント名
[入力データ]:入力データとなるコンポーネント名
[接続先]:グローバルリソースで設定済みの接続先
[テーブル名]:書き込み対象テーブル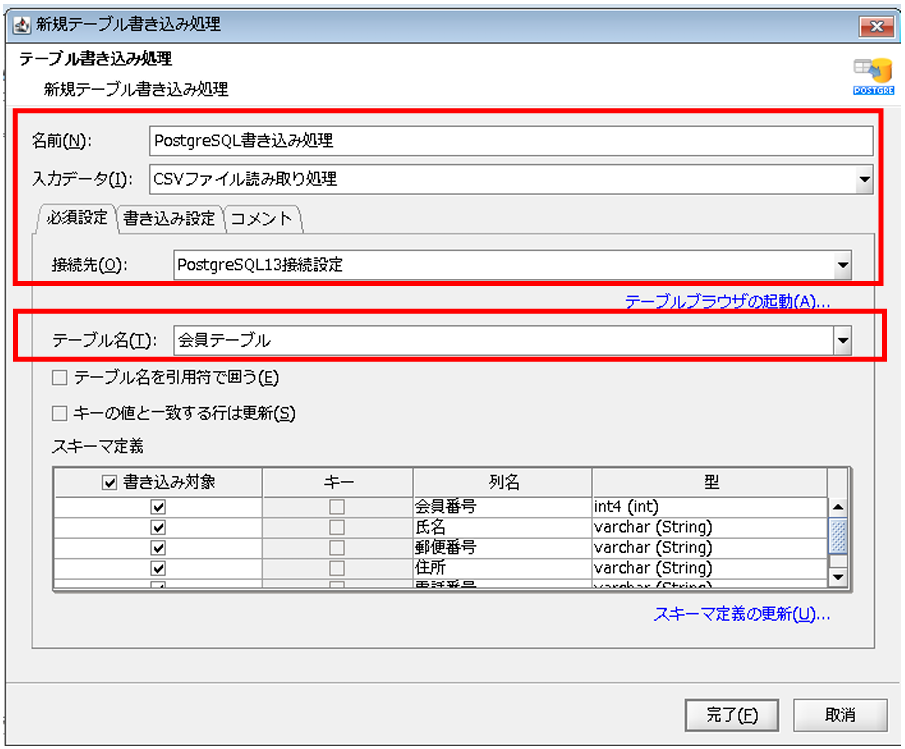
[キーと値と一致する行は更新]にチェックを入れ、[スキーマ定義]で[列名]が、「会員番号」の行の[キー]にチェックを入れます。
この設定によって、DBに格納されている会員番号と重複するデータが連携される場合は、連携されたデータで更新されます。 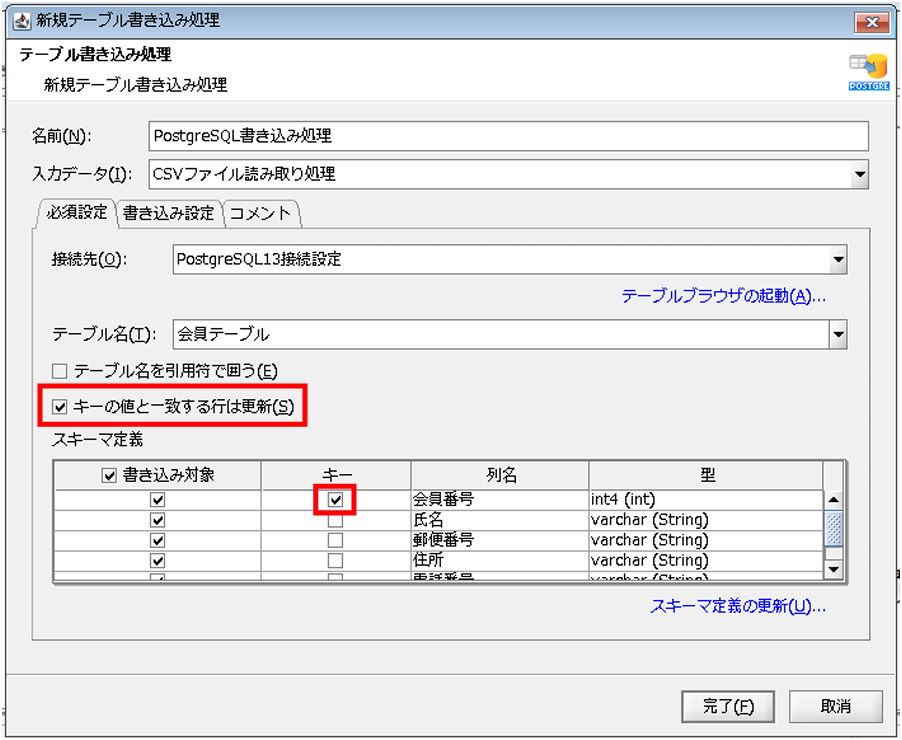
[完了]を押下すると、プロパティ設定ダイアログが閉じ、「PostgreSQL書き込み処理」アイコンがキャンパスに配置され、マッピングの追加ダイアログが表示されます。 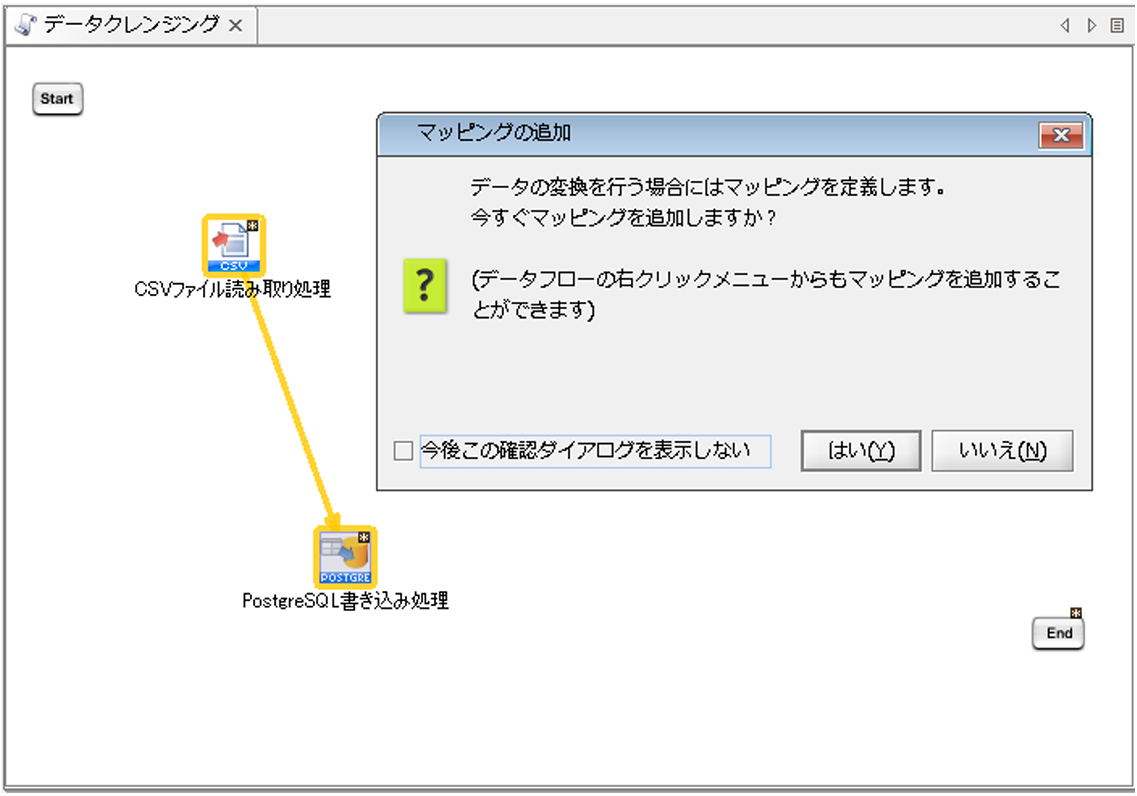
Mapperを追加し、連携元データと連携先データベースのデータ連携を作成します。
またMapper内でデータクレンジングを行います。
Mapper 追加ダイアログの「はい」を選択します。 
「CSVファイル読み取り処理」と「PostgreSQL書き込み処理」の間に、「mapping」アイコンが配置されます。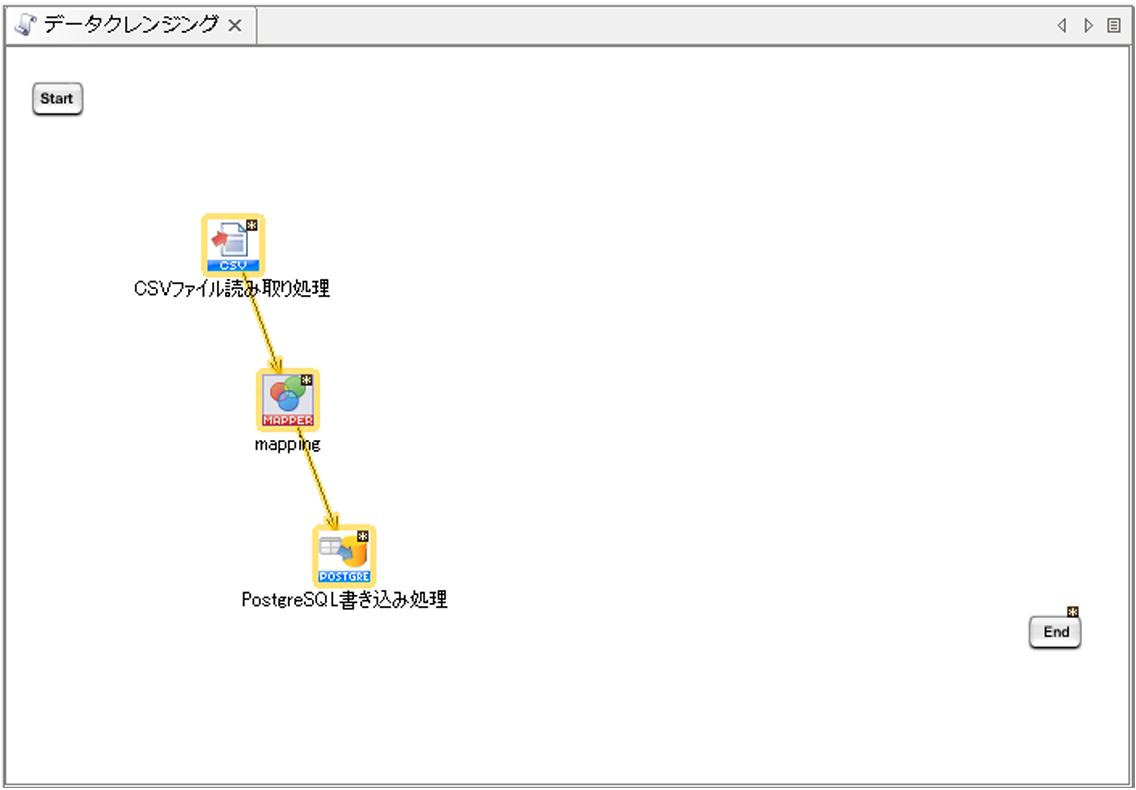
配置された「mapping」アイコンをダブルクリックし、Mapperエディタを開きます。 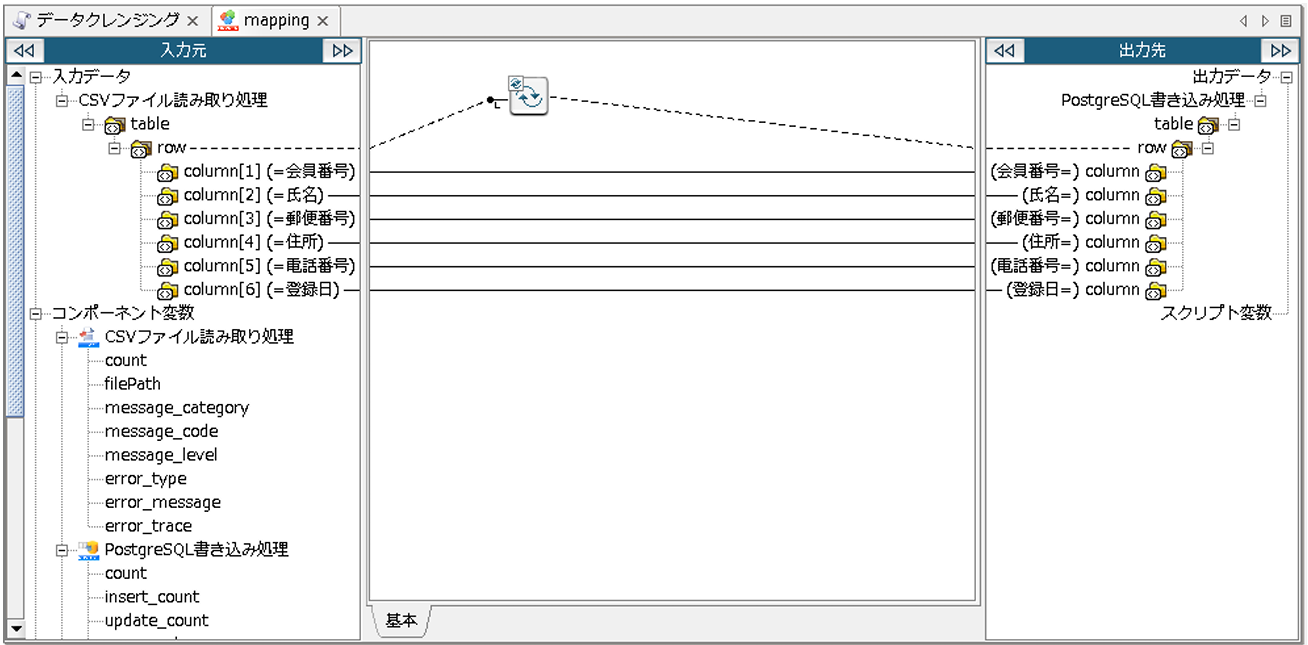
今回データクレンジングを行う内容は以下の通りです。
データクレンジングを行う前に、クレンジング内容ごとに、マッピングのレイヤを分けます。
マッピングキャンバス下部のレイヤタブがない場所を右クリックし、[レイヤを追加]を押下し、「レイヤ名」を入力後、[OK]を押下します。
〇設定項目
[レイヤ名]:作成したいレイヤ名 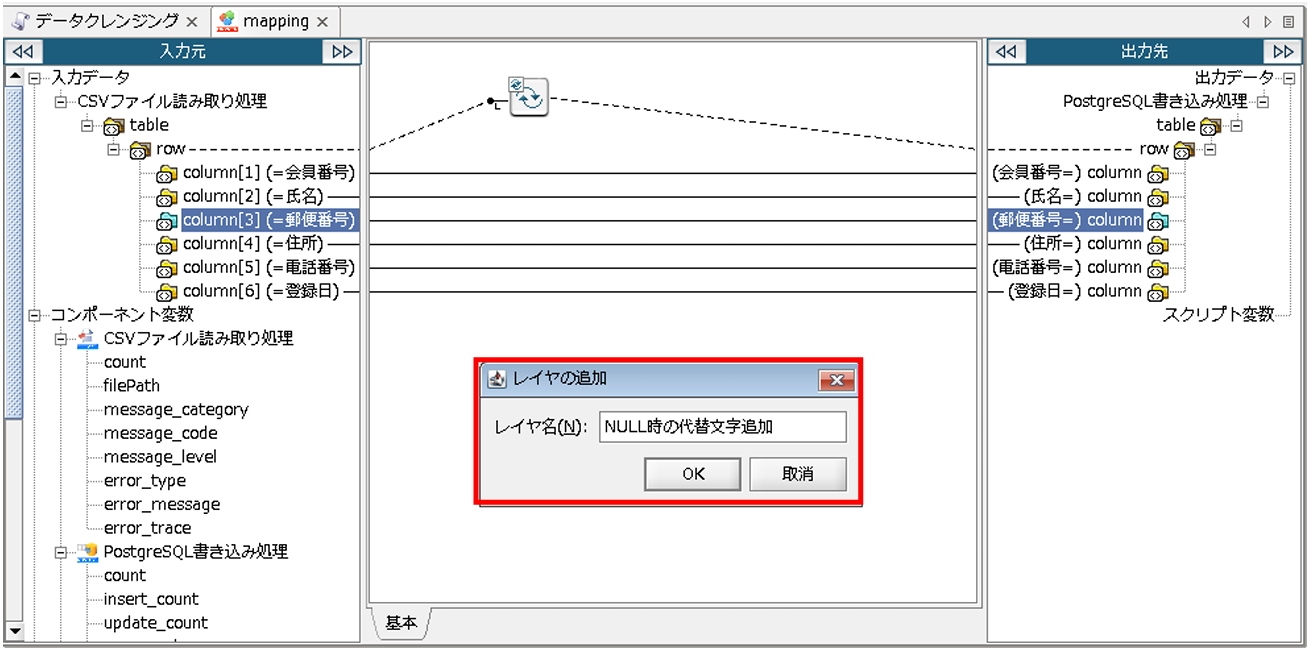
これで、レイヤが追加されました。
日付形式修正用のレイヤも、先ほどの手順で作成します。 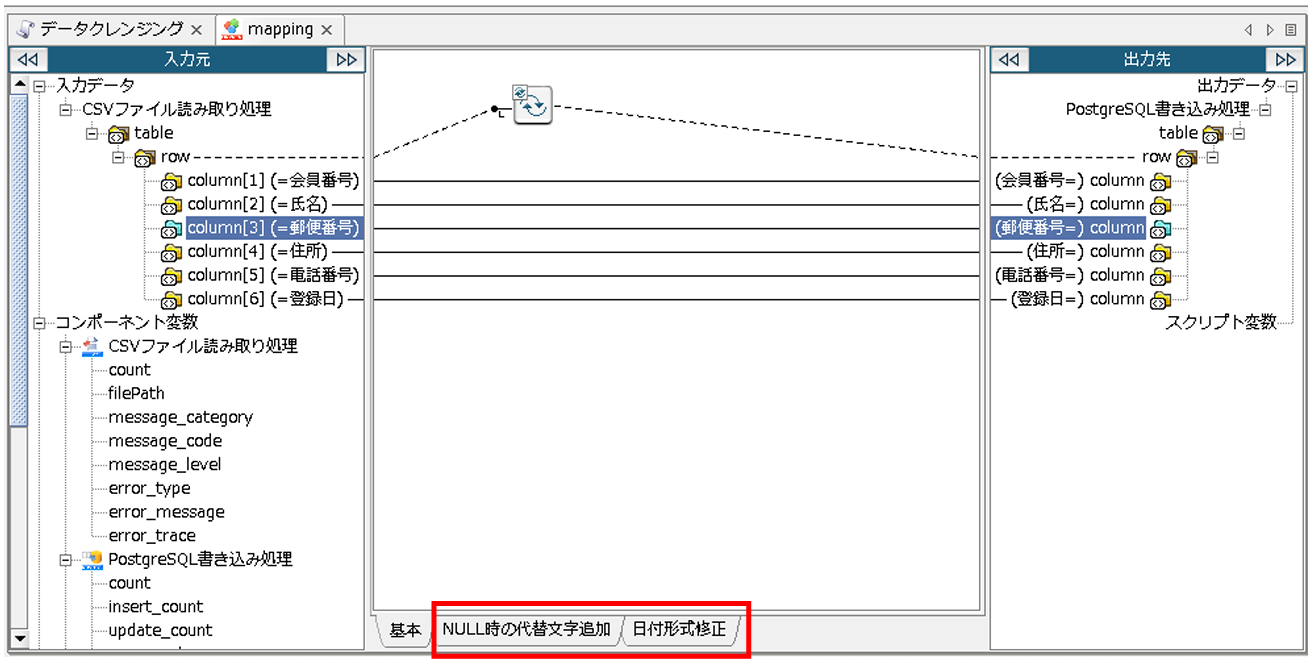
まず、連携元データ項目値がNULL時の代替文字の追加から行います。
今回、連携元データ項目値がNULLの場合には、ハイフンを出力するようにします。
レイヤを「NULL時の代替文字追加」に切り替え、Mapper エディタのツールパレットから[分岐]-[基本]-[スイッチ判定による出力の切り替え]をマッピングキャンバスにドラッグ&ドロップします。
[スイッチ判定による出力の切り替え]ロジックアイコンを使用することにより、出力データを場合分けすることができます。
(奇数番目の入力ハンドラには真偽値を、偶数番目の入力ハンドラには奇数番目のハンドラで受け取った値がtrueである場合に出力したい文字列を、最終番目の入力ハンドラには真偽値が全てfalseだった場合に出力したい文字列をマッピングします。) 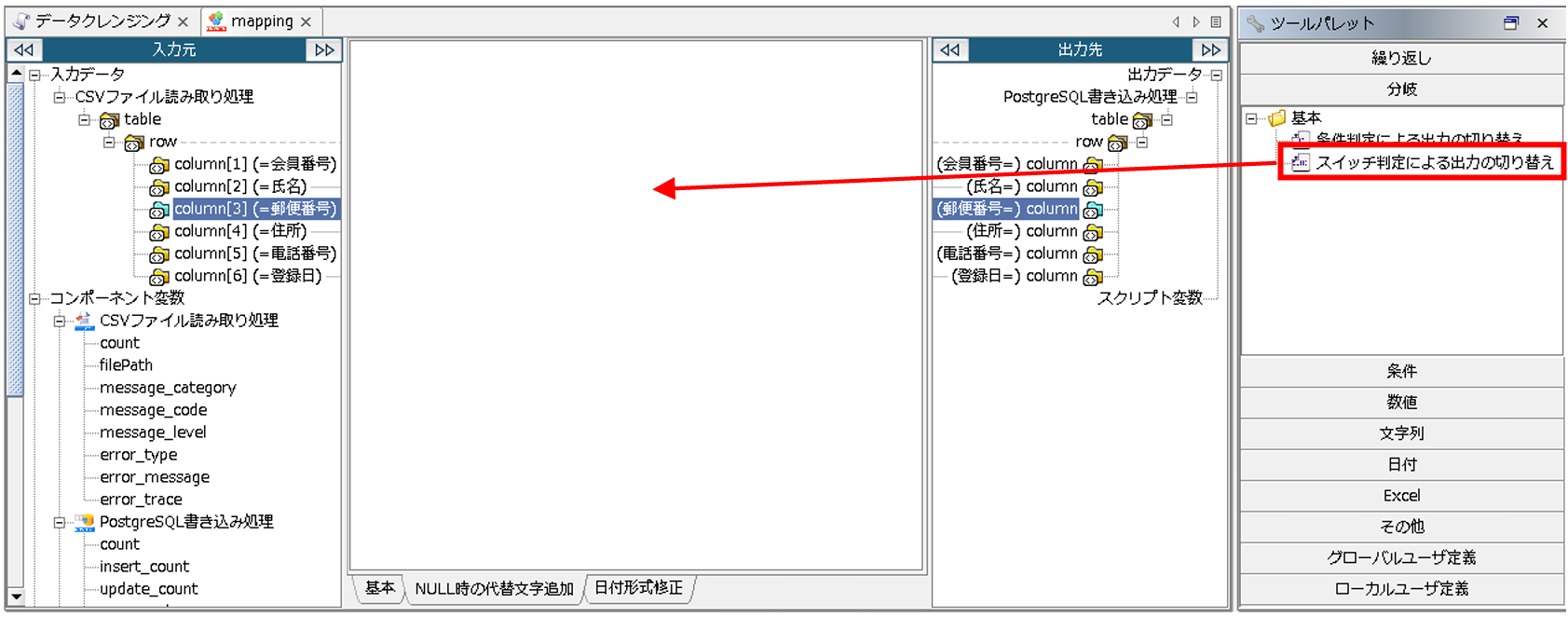
次に、[条件]-[真偽]-[nullチェック]をマッピングキャンバスにドラッグ&ドロップします。
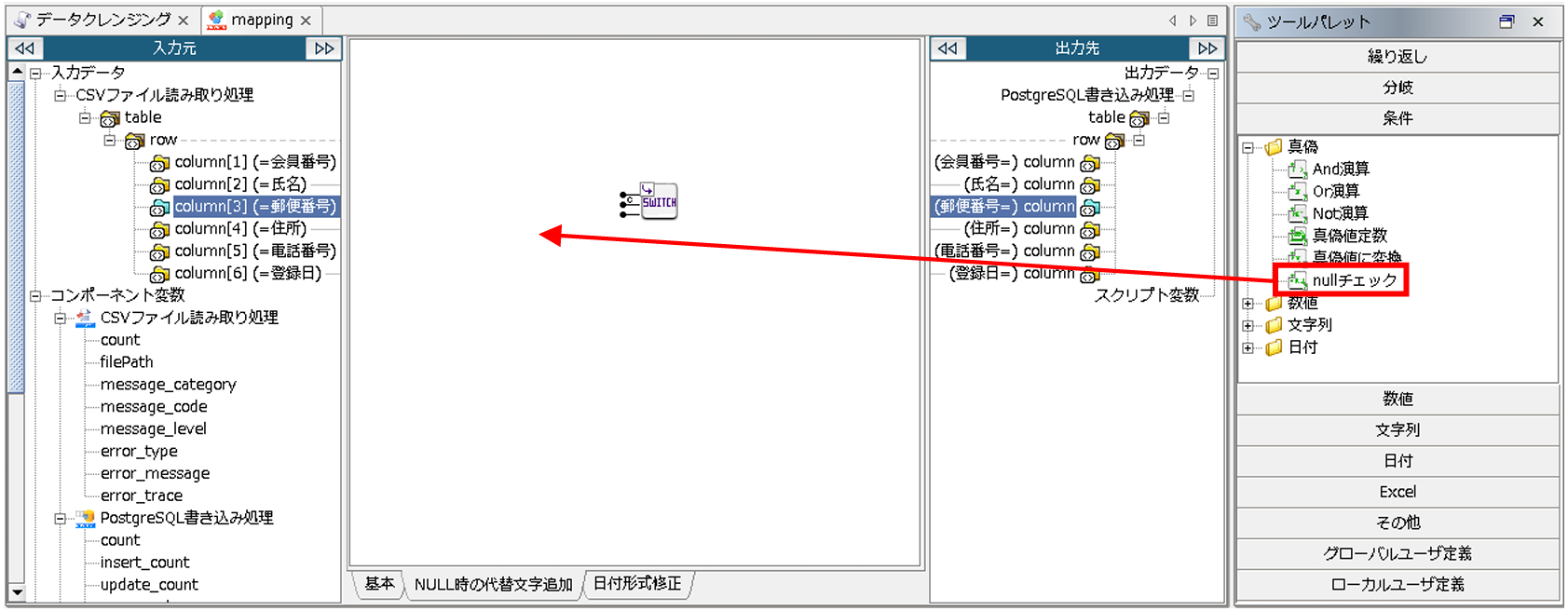
「スイッチ判定による出力の切り替え」、「nullチェック」ロジックアイコンが配置されたら、マッピングリンクを作成します。
連携元データ内でNULL値が入力されている項目は、「郵便番号」、「住所」、「電話番号」です。
初めに、「郵便番号」から設定していきます。
入力元「郵便番号」から「nullチェック」ロジックアイコンへリンクを引き、「nullチェック」ロジックアイコンを、「スイッチ判定による出力の切り替え」ロジックアイコンの、1番目の入力ハンドラへリンクを引きます。 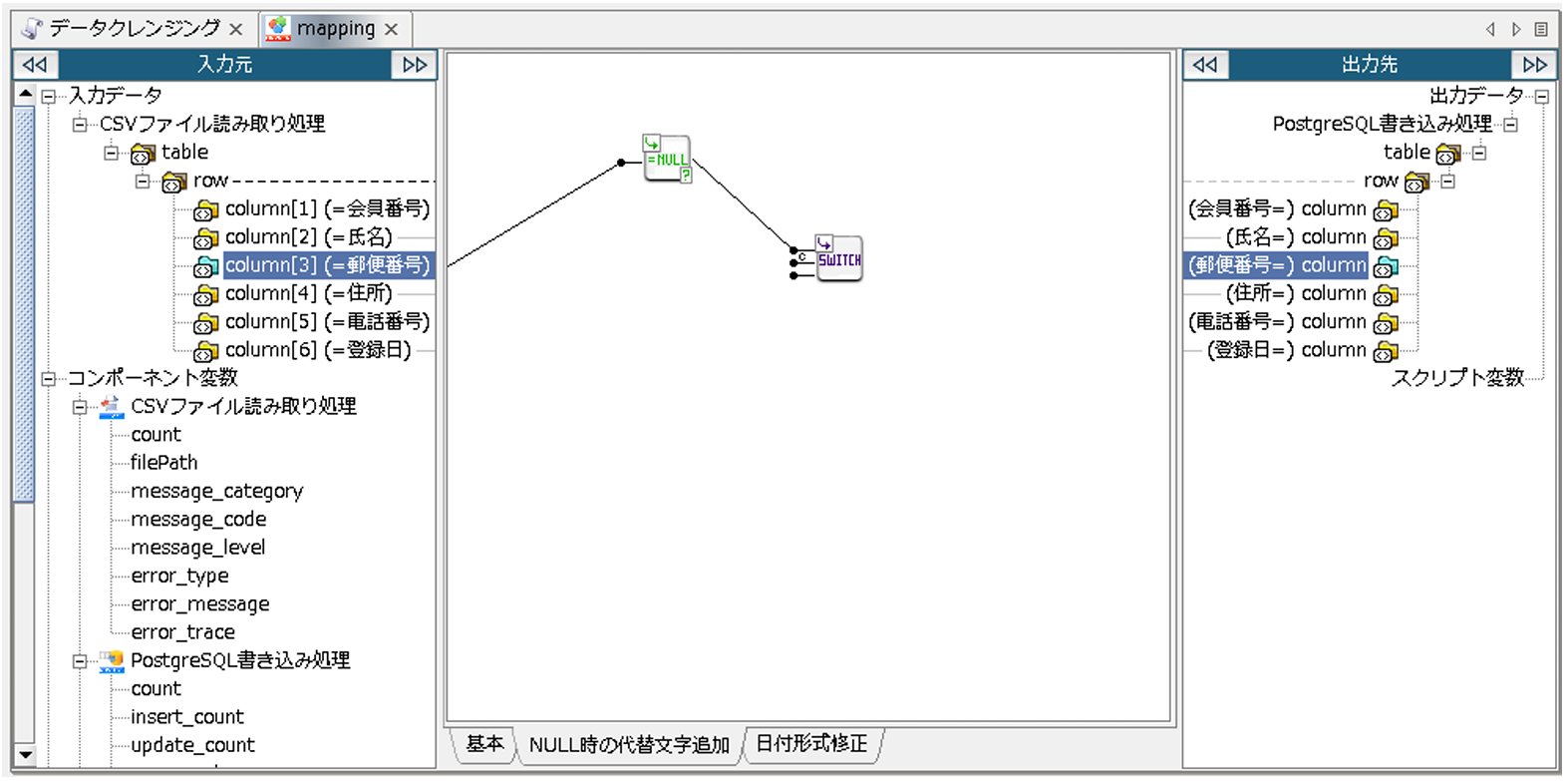
次に、Mapper エディタのツールパレットから[文字列]-[基本]-[単一行文字列定数]をマッピングキャンバスにドラッグ&ドロップします。 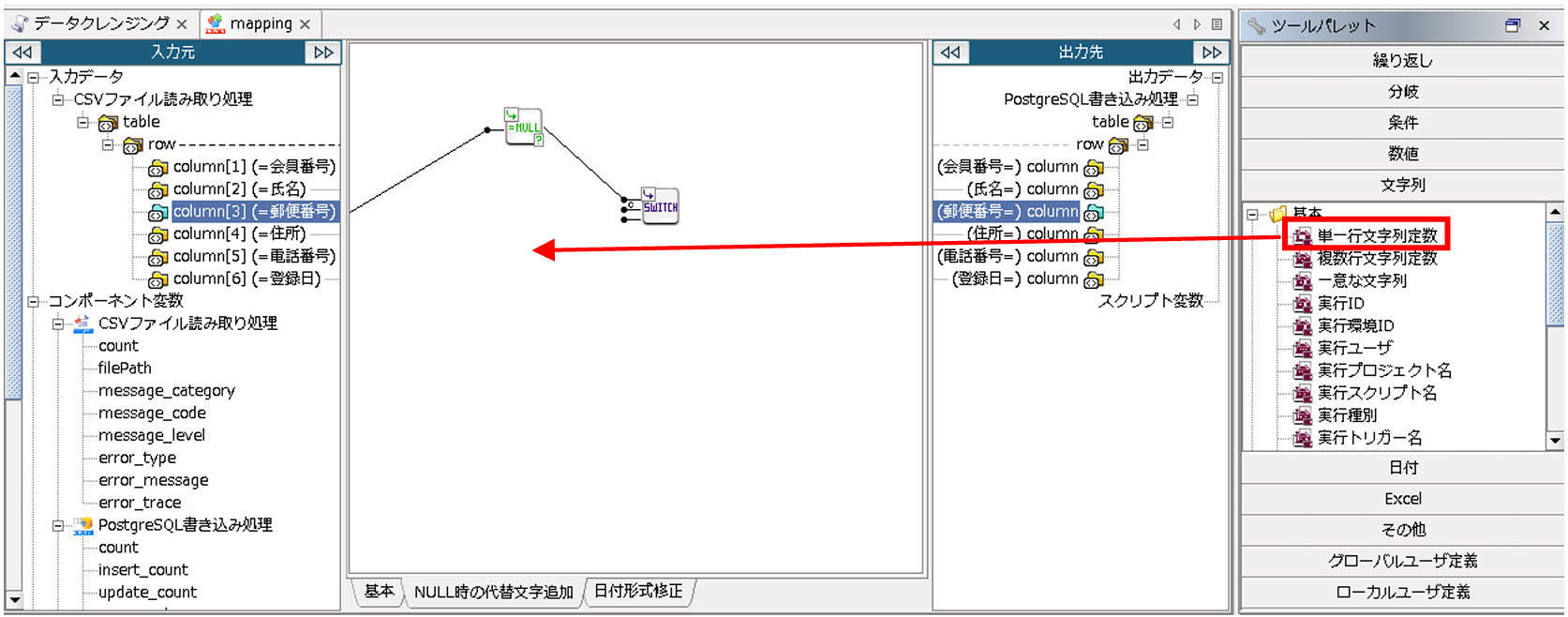
配置された「単一行文字列定数」ロジックアイコンをダブルクリックし、「単一行文字列定数ロジック」プロパティ設定ダイアログで、以下の通り設定を行い、[完了]を押下します。
◎必須設定
[一行文字列]:出力させたい文字列
[コメント]:スクリプト上に表示させるコメント 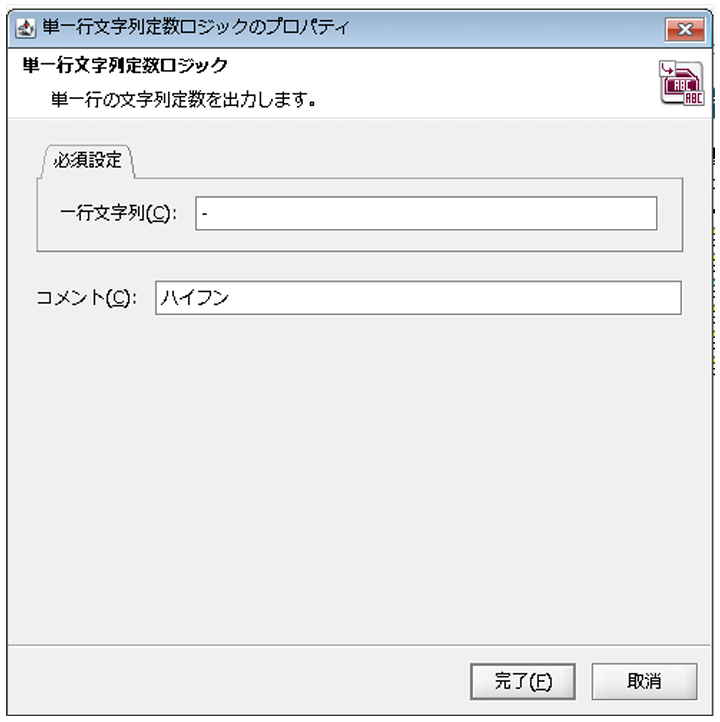
「スイッチ判定による出力の切り替え」ロジックアイコンの2番目の入力ハンドラには、先ほど配置した「単一行文字列定数」ロジックアイコンからリンクを引きます。 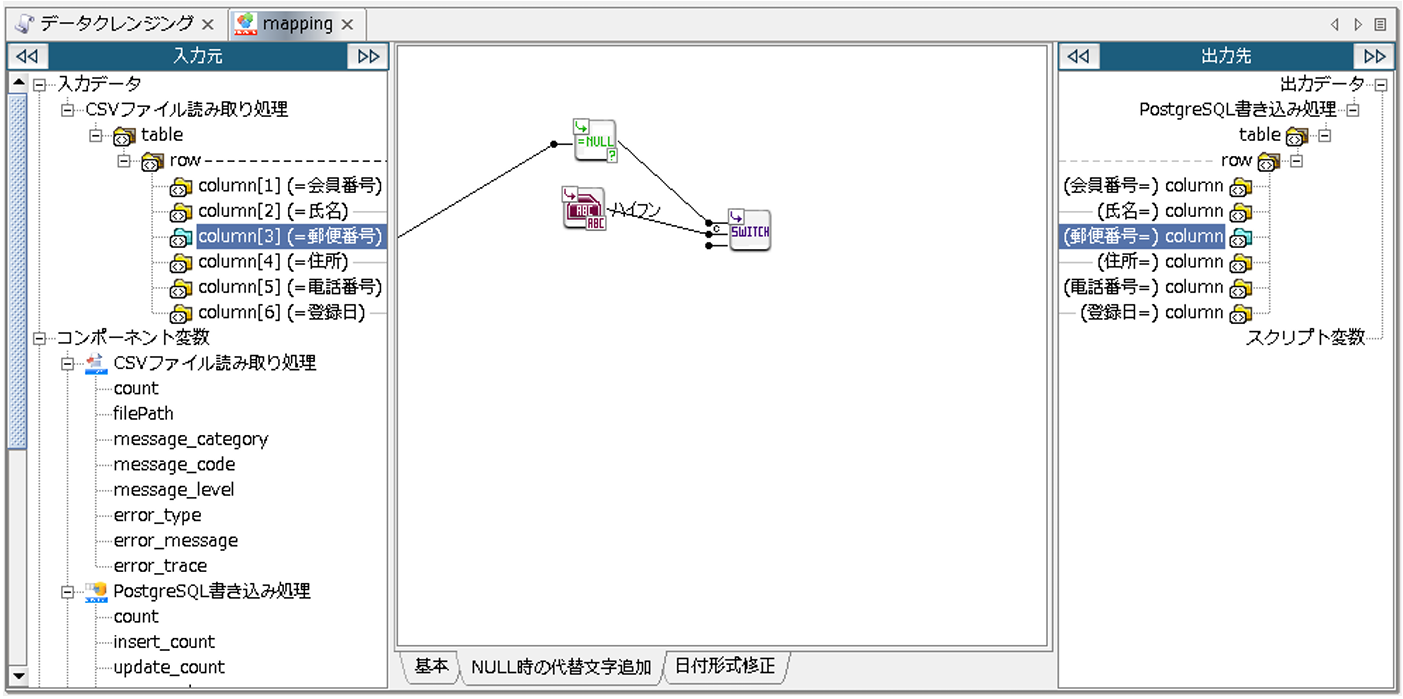
「スイッチ判定による出力の切り替え」ロジックアイコンの3番目の入力ハンドラには、入力元「郵便番号」からリンクを引き、「スイッチ判定による出力の切り替え」ロジックアイコンから出力先「郵便番号」へリンクを引きます。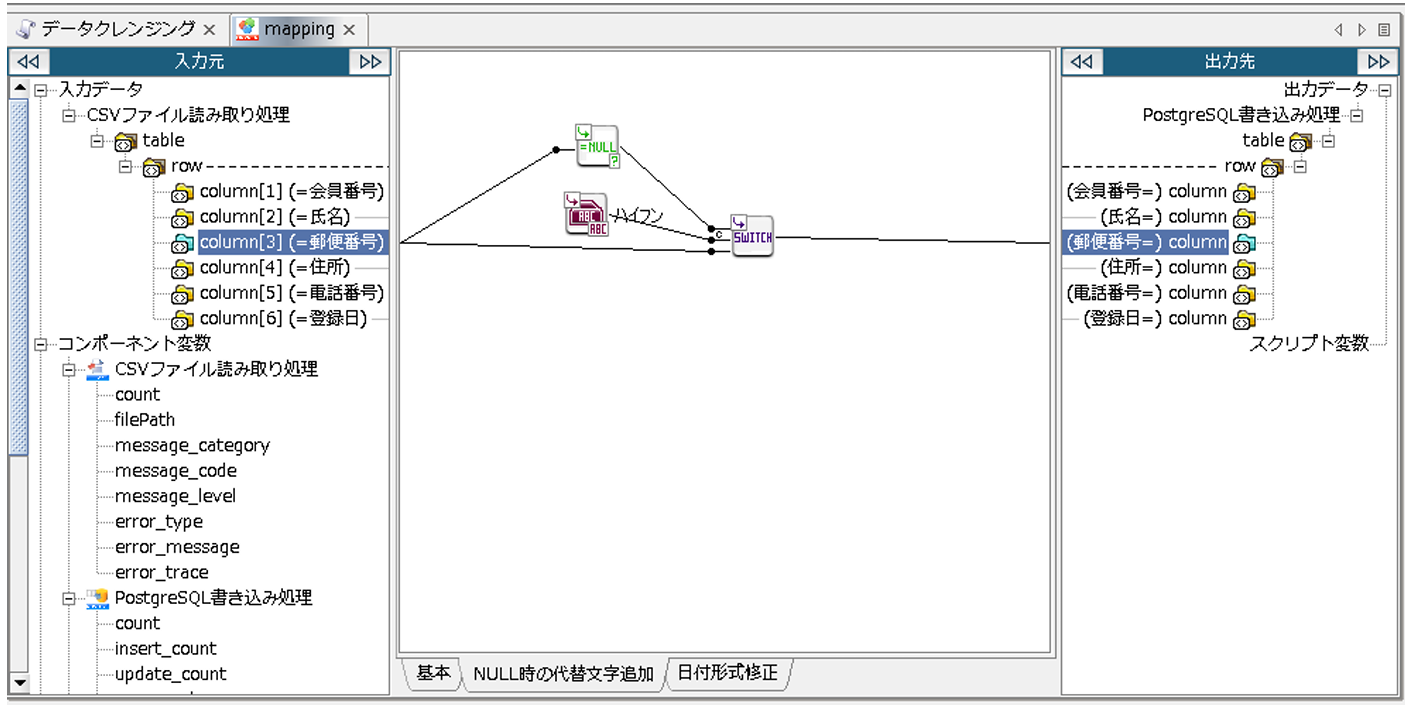
これにより、入力元「郵便番号」にNULL値が入力されている場合、出力先「郵便番号」にはハイフンが出力されるようになります。NULL値以外が入力されている場合には、入力元「郵便番号」に設定されている値がそのまま出力されます。
同じ手順で、「住所」、「電話番号」にも同様にマッピングを作成します。 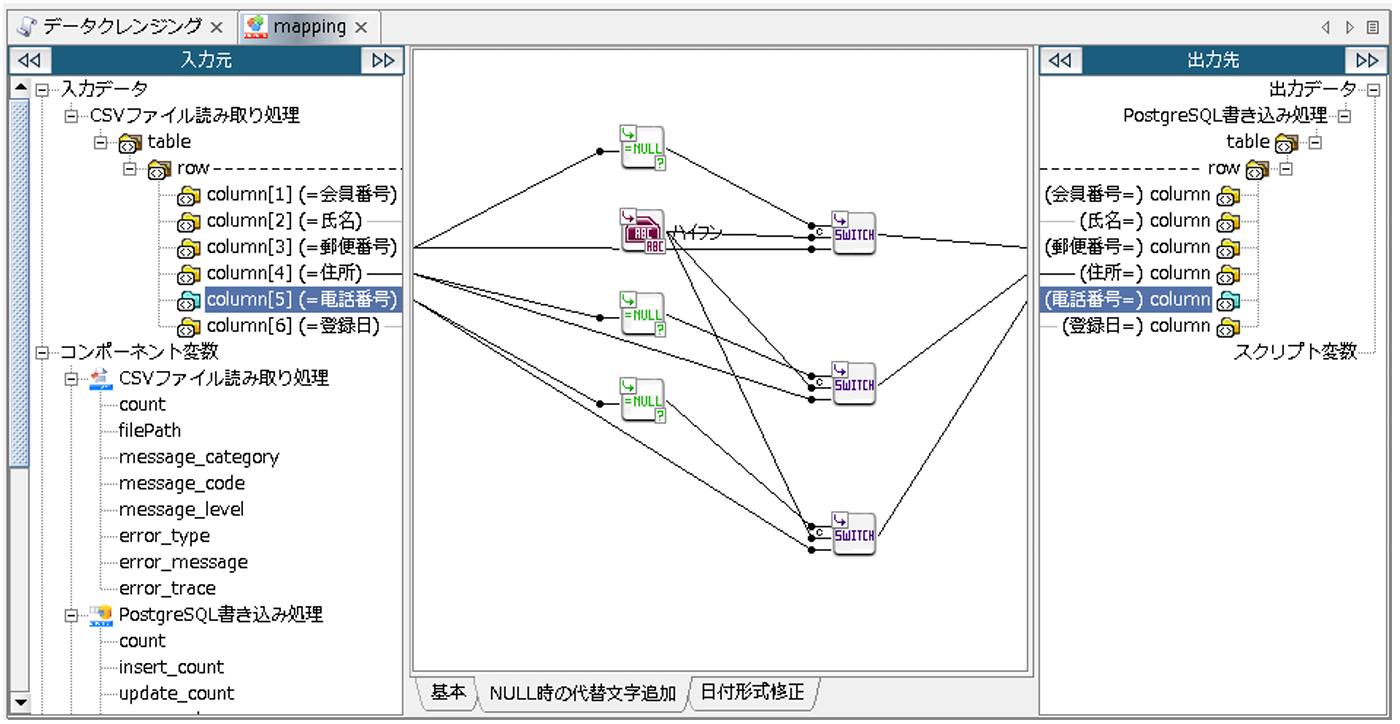
次に、日付形式の統一です。
「登録日」に入力されている日付の形式が統一されていないため、データ出力時に「yyyy/MM/dd」の形式で統一されるよう設定します。
レイヤを「日付形式修正」に切り替え、Mapper エディタのツールパレットから[文字列]-[日付]-[日時フォーマッティング]をマッピングキャンバスにドラッグ&ドロップします。 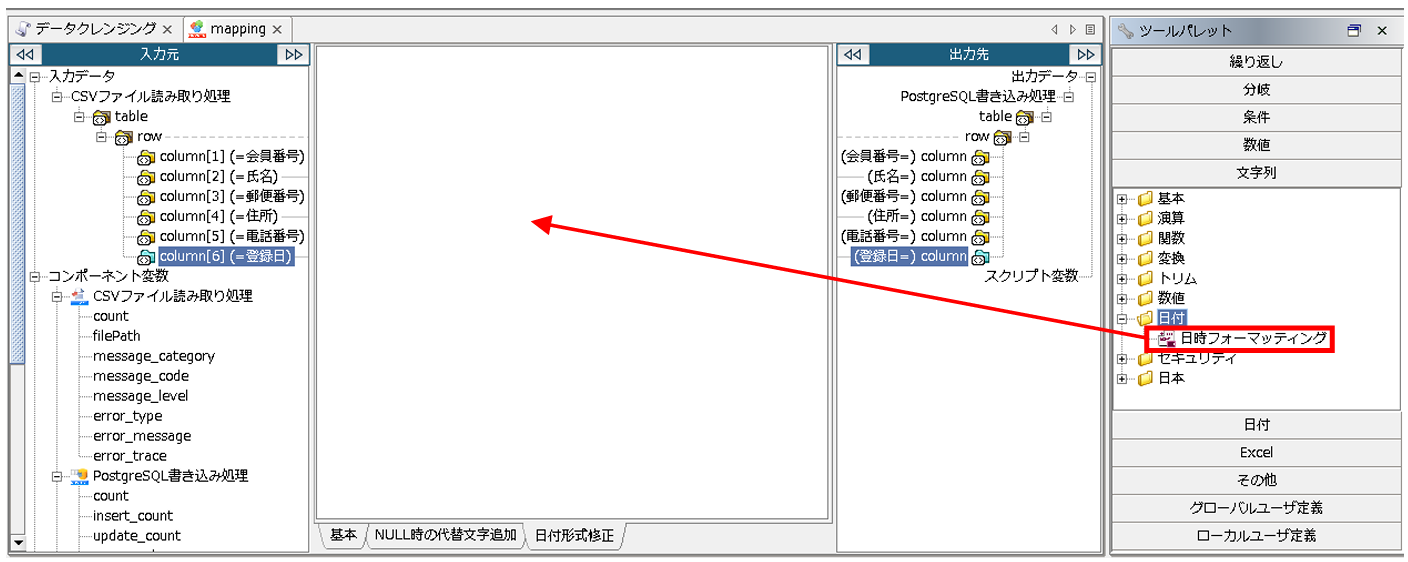
配置された「日時フォーマッティング」ロジックアイコンをダブルクリックし、「日時フォーマッティングロジック」プロパティ設定ダイアログで、以下の通り設定を行い、[完了]を押下します。
◎必須設定
[フォーマット]:出力させたい文字列
[コメント]:スクリプト上に表示させるコメント 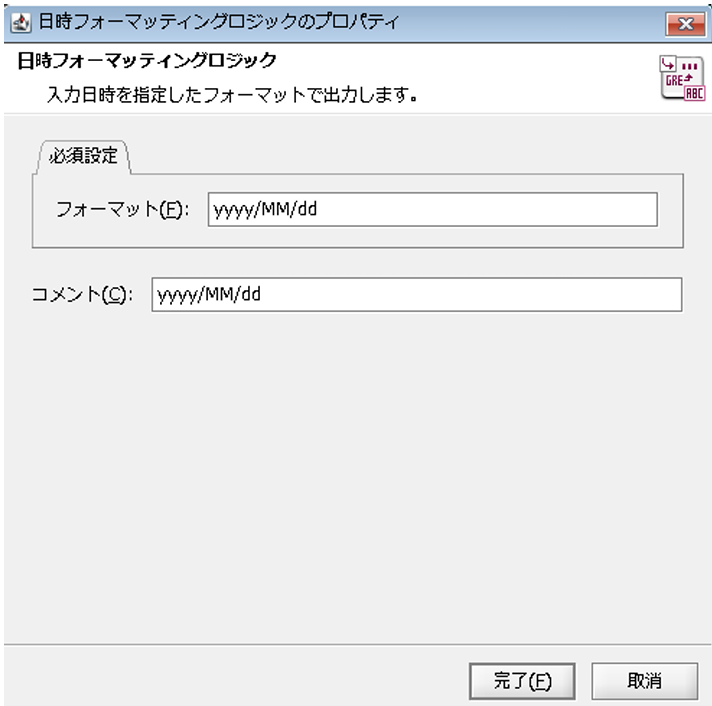
入力元「登録日」から「日時フォーマッティング」ロジックアイコンにリンクを引き、「日時フォーマッティング」ロジックアイコンから、出力先「登録日」へリンクを引きます。
これにより、入力元「登録日」に設定されている日付が、出力時に「yyyy/MM/dd」の形で統一されます。 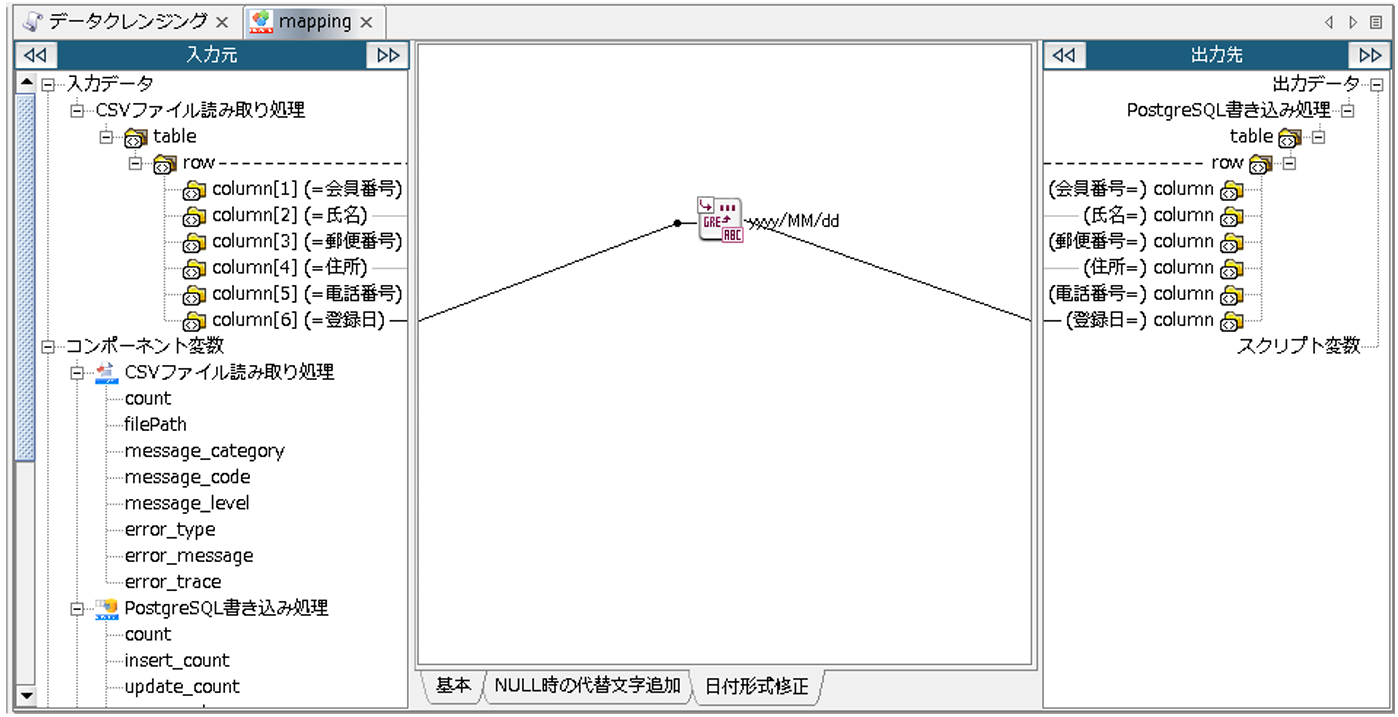
以上でデータのクレンジングは完了です。
処理の順番にプロセスフローを引きます。
(「Start」→「CSVファイル読み取り処理」→「mapping」→「PostgreSQL書き込み処理」→「End」の順) 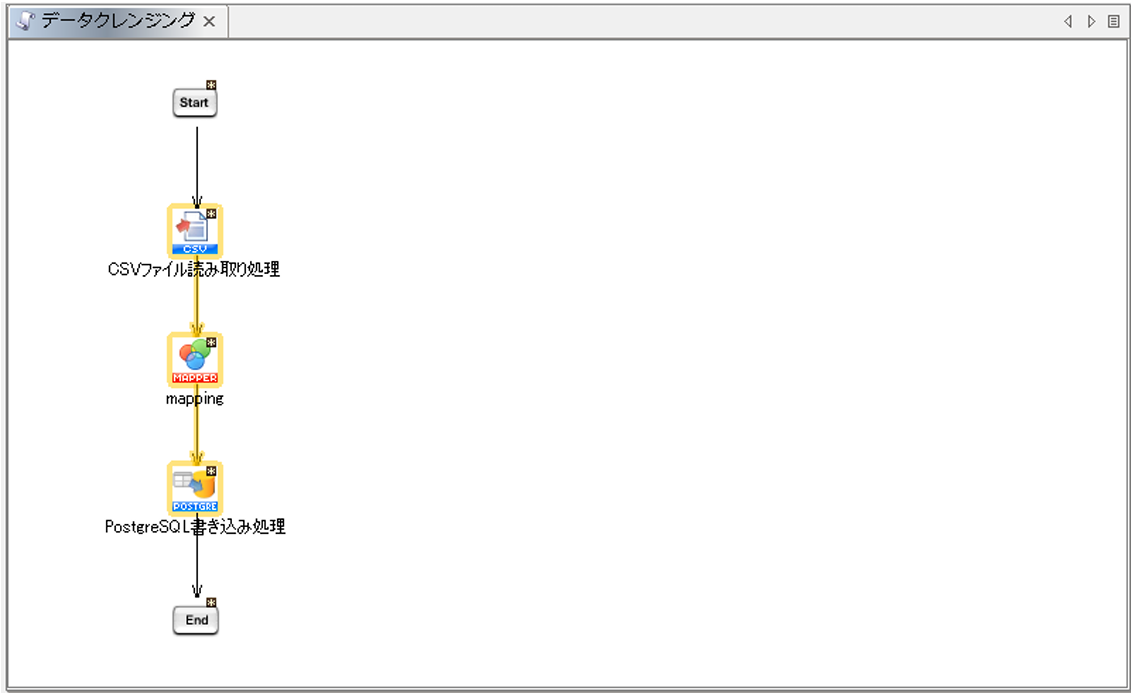
[デバッグ実行の開始/再開]を押下して処理を実行します。 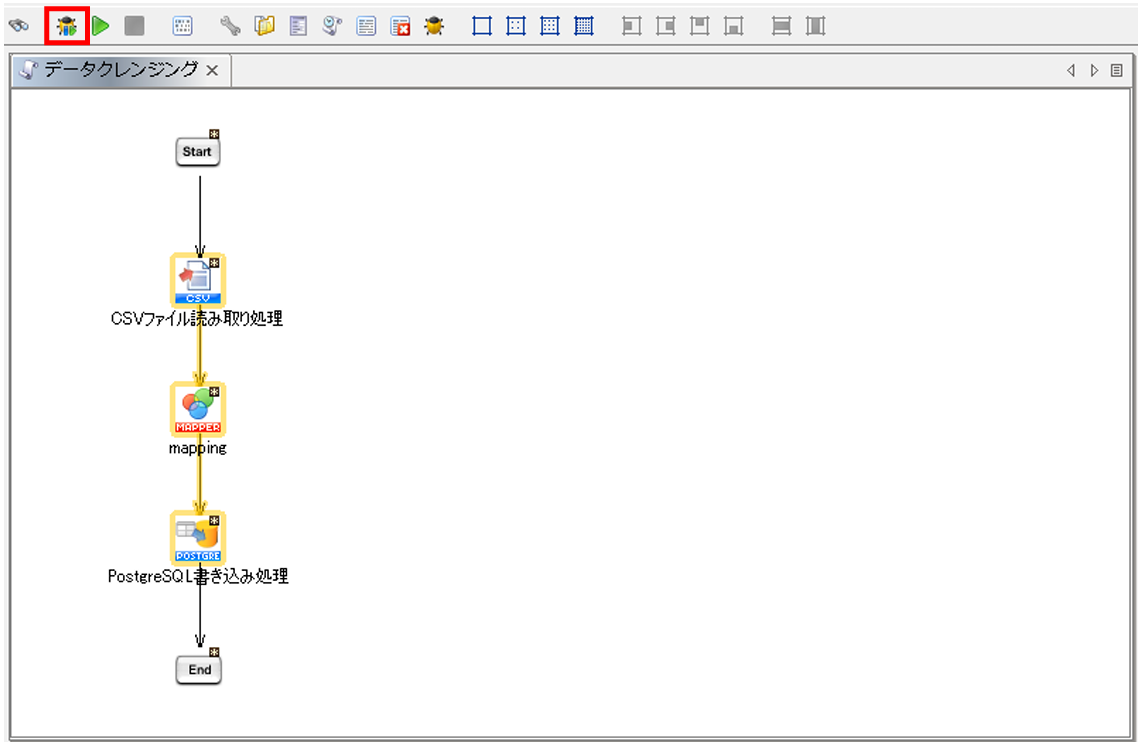
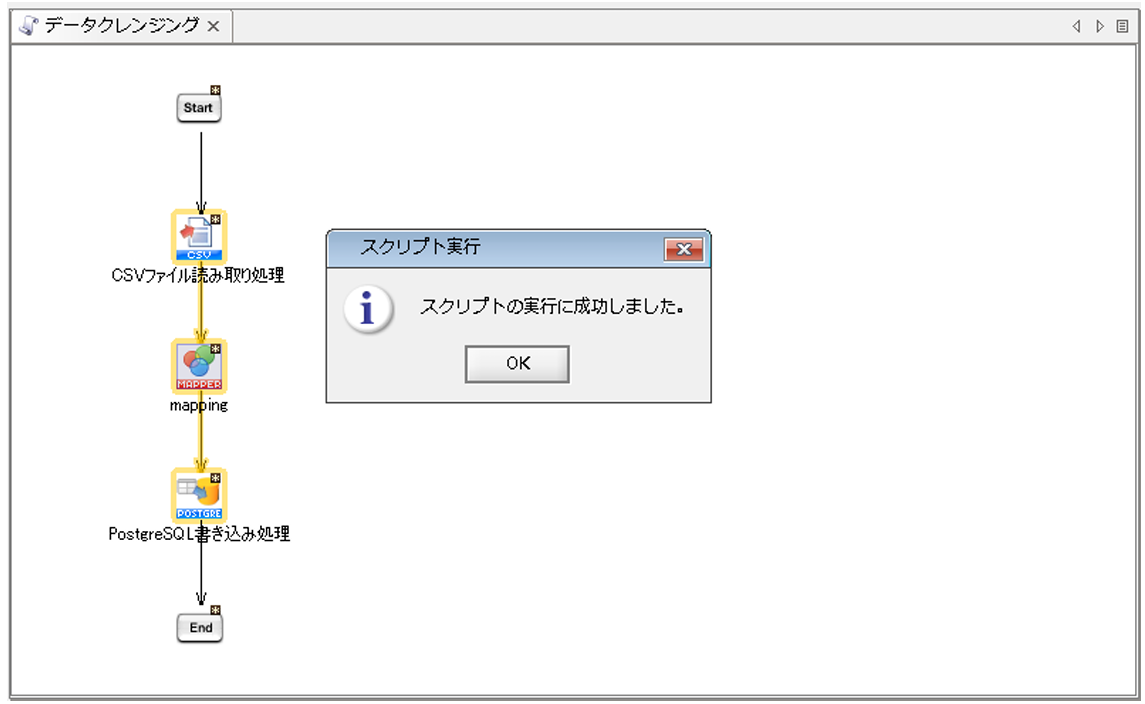
連携元データがPostgreSQLに書き込まれているか確認します。 
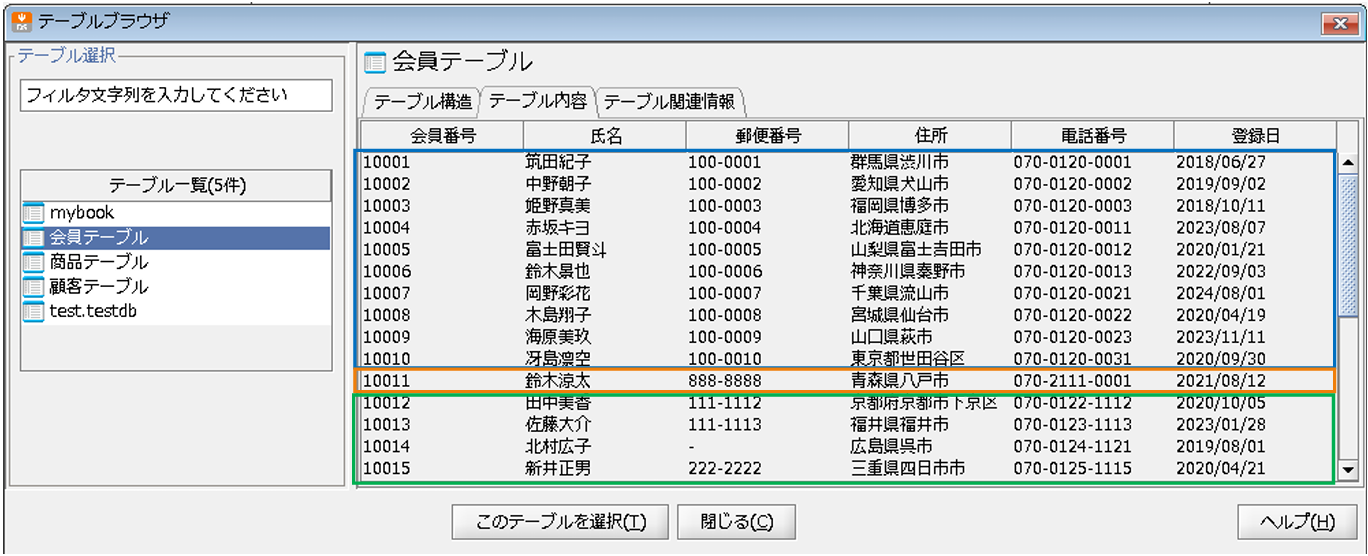
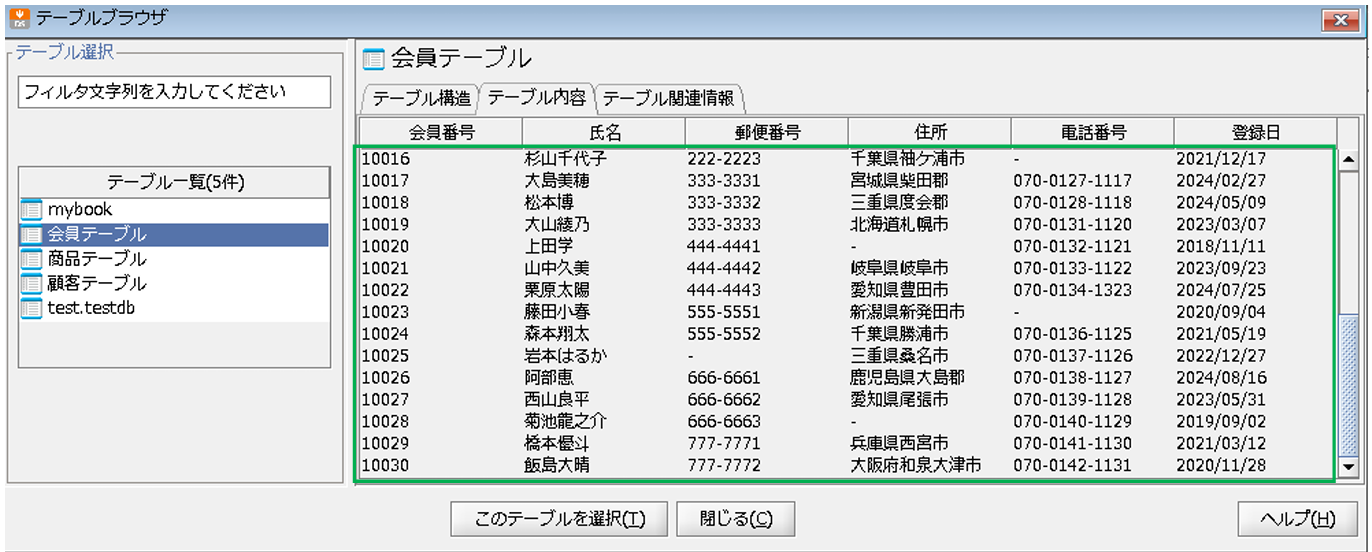
※元々のデータは青、追加されたデータは緑、重複更新されたデータは黄色で囲っています。
クレンジングした内容で、正常にデータ出力されていることが確認できました。
以上が、マッピング内でデータクレンジングを行う手順の説明になります。
何でもお気軽にご質問ください