バッチ処理とは、一定量のデータを集め、一括処理をするための処理方法です。定期的なタスクや大量データ処理を効率的に行い、主にデータの集計、変換、更新、エクスポート等の用途で使用します。
DataSpiderを用いてバッチ処理行うことで、リアルタイム処理後比べて、下記のようなメリットがあります。
| メリット | ・高いスループット |
|---|---|
| ・システム負荷の軽減 | |
| ・エラー処理の容易さ | |
| ・処理の自動化 | |
| ・データ整合性の確保 |
今回はDataSpiderを使用して、他サーバより取得したCSVファイルのデータを読み取り、読み取ったデータをデータベースの更新対象テーブルへ書き込むというスクリプトを作成し、毎日指定時間になるとトリガーの発火によって、作成したスクリプトが実行されるというバッチ処理を取り入れた連携の作成手順を説明します。
処理フローと処理内容は以下の通りです。
| 取得 |
|
|---|---|
| 読み取り |
|
| 書き込み |
|
| トリガー発火 |
|
今回の処理の前提条件は以下の通りです。
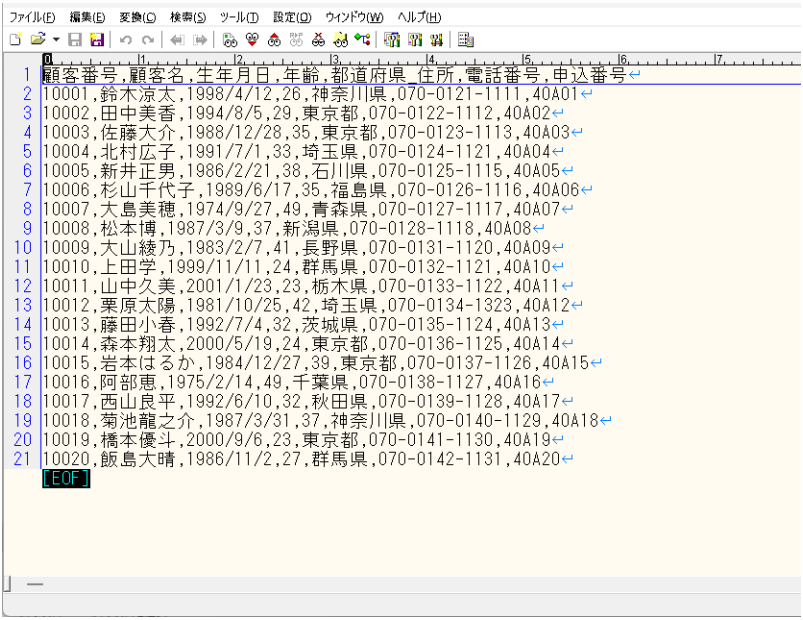
今回連携するCSVファイルの内容は以下の通りです。
※データは全てテスト用の架空データであり、実在の人物とは関係ございません
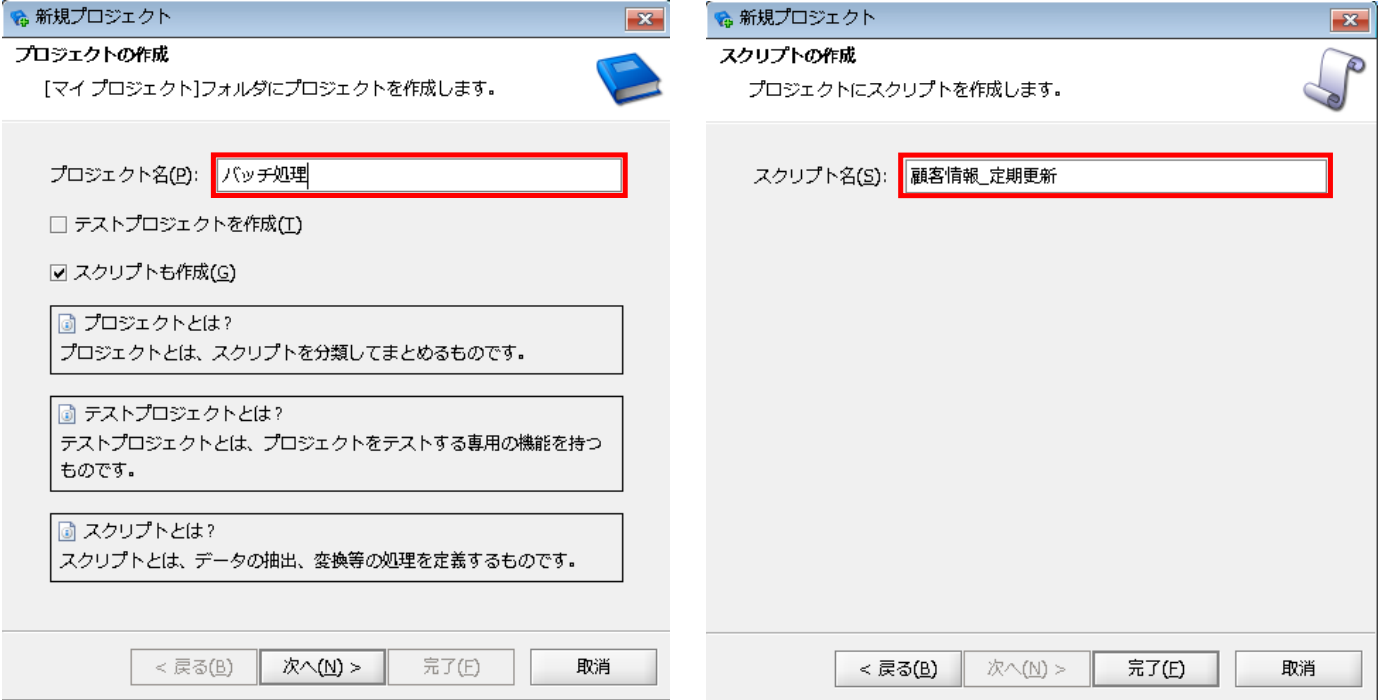
[プロジェクト名]:任意のプロジェクト名
[スクリプト名]:任意のスクリプト名
連携元CSVファイルを、接続したFTPサーバ上のフォルダから取得します。
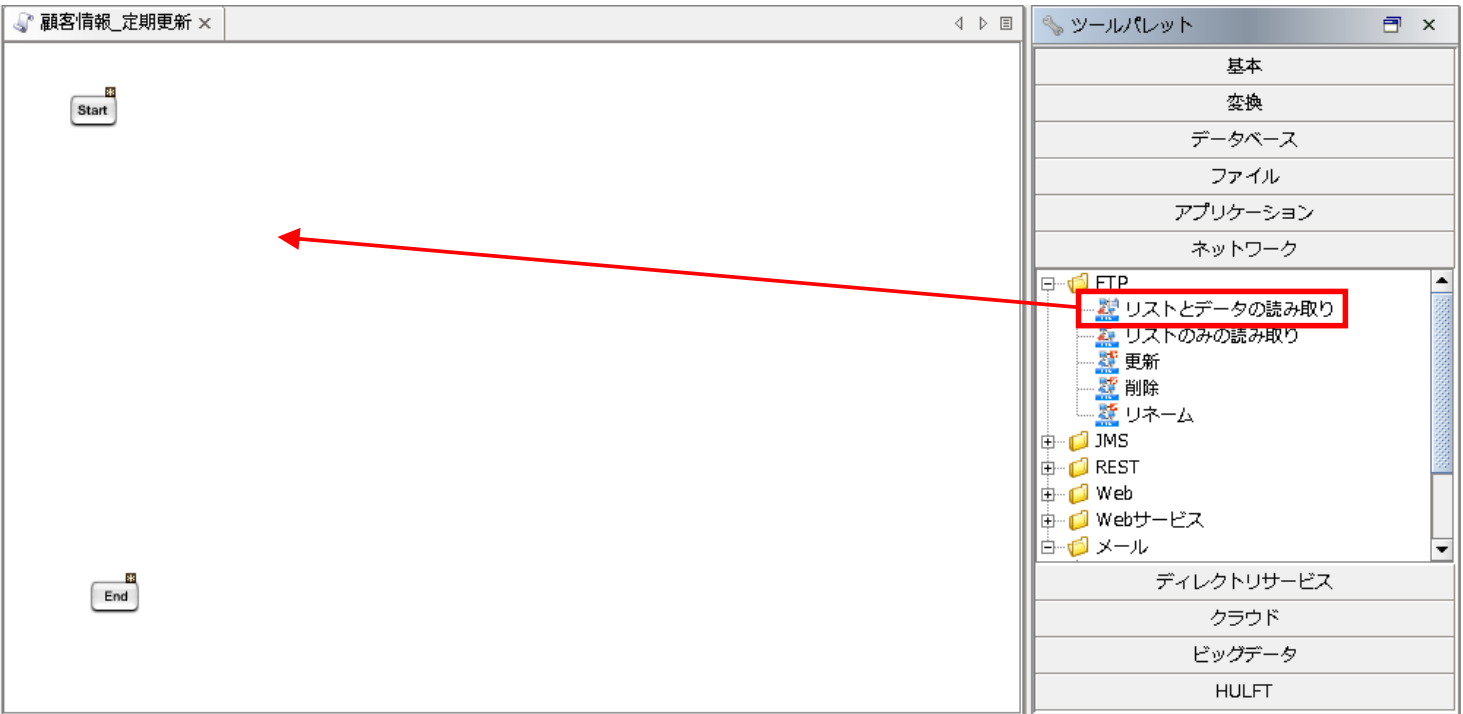
【5-1】
ツールパレットから[ネットワーク]-[FTP]-[リストとデータの読み取り]を、スクリプトキャンバスにドラッグ&ドロップします。
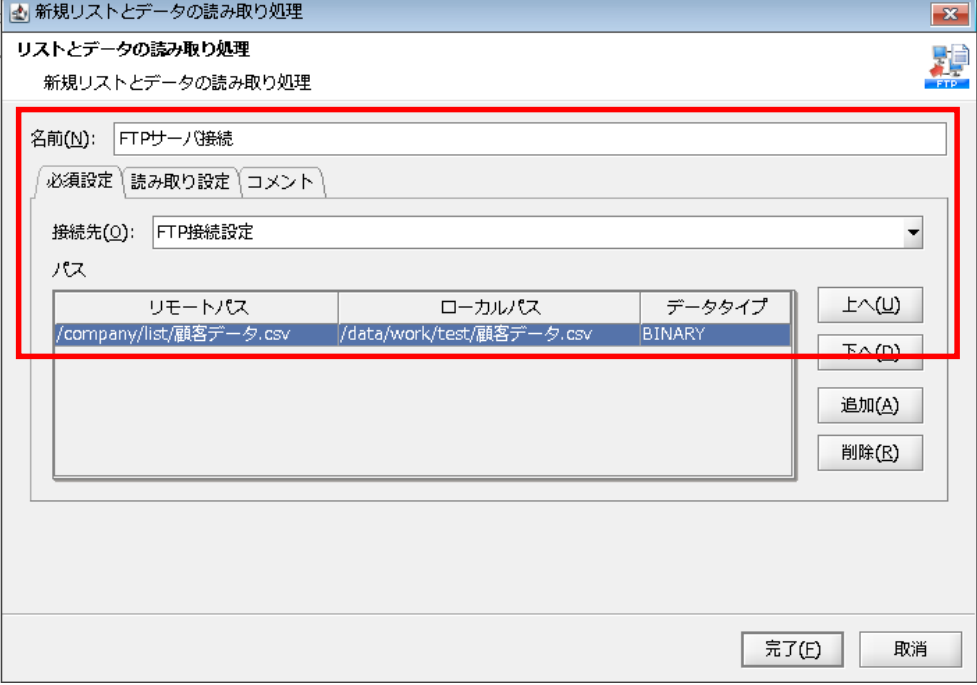
【5-2】
「リストとデータの読み取り処理」プロパティ設定ダイアログで、以下の通り設定を行います。
◎必須設定
[名前]:コンポーネント名
[接続先]:グローバルリソースで設定済みの接続先
[リモートパス]:FTPサーバ上の取得対象フォルダ/ファイル
[ローカルパス]:取得したファイルの格納先フォルダ/ファイル
[データタイプ]:データタイプ
【5-3】
[完了]を押下すると、プロパティ設定ダイアログが閉じ、「FTPサーバ接続」アイコンがキャンパスに配置されます。
FTPサーバから取得したCSVファイルを、読み取りファイルとして設定します。
【6-1】
ツールパレットから[ファイル]-[CSV]-[CSVファイル読み取り]を、スクリプトキャンバスにドラッグ&ドロップします。
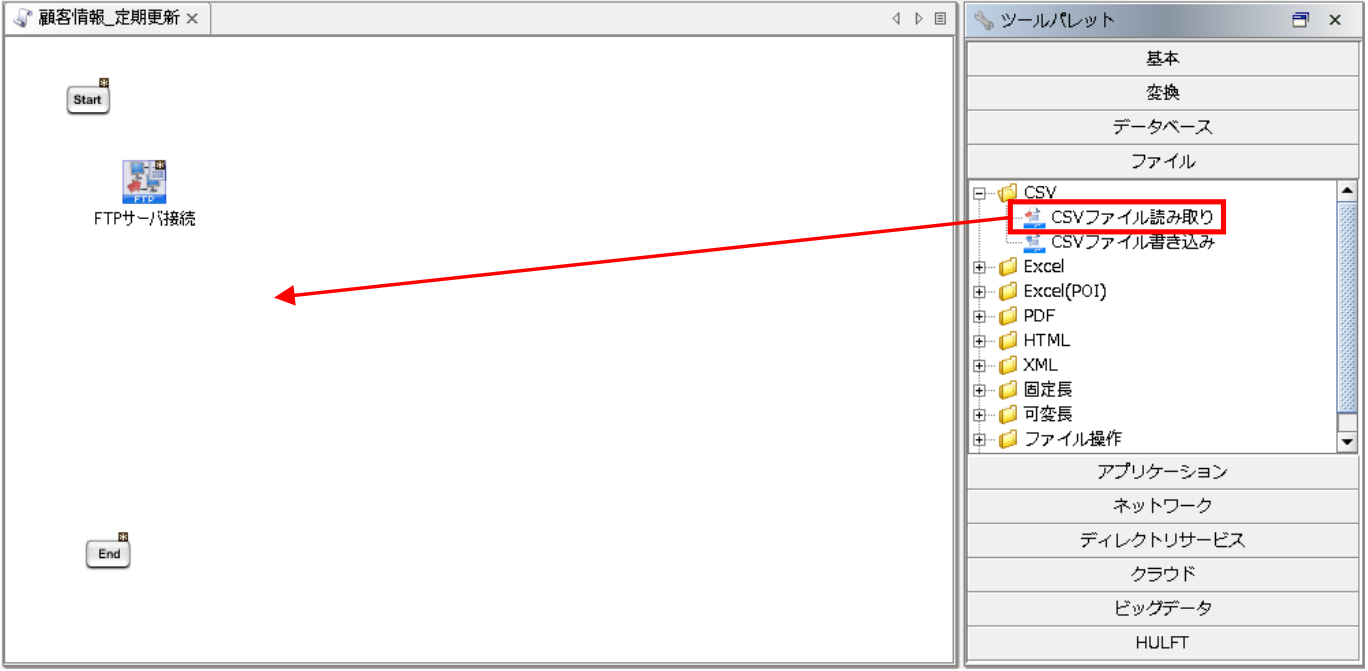
【6-2】
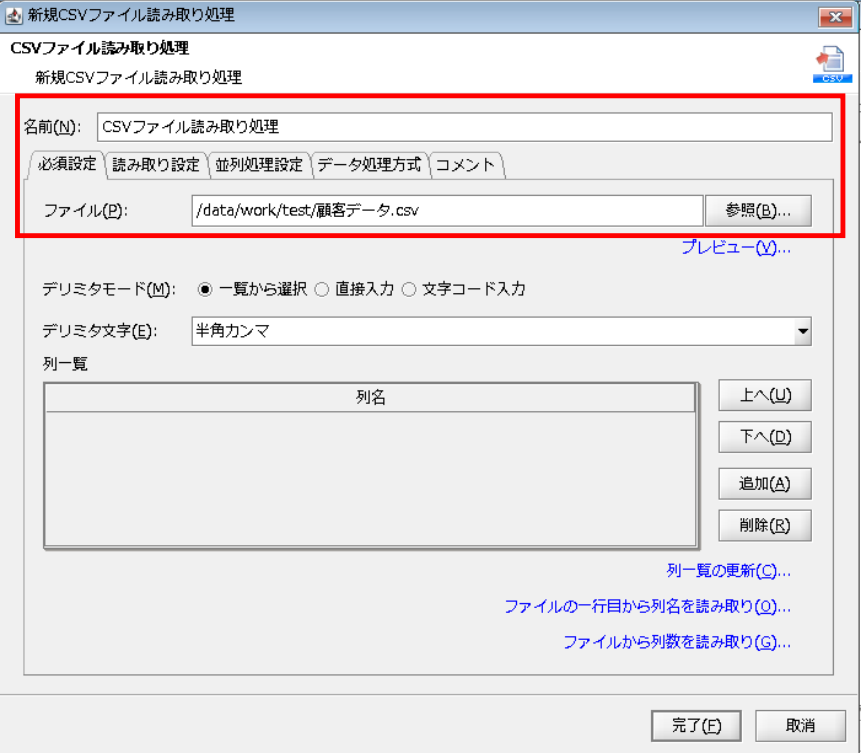
「CSVファイル読み取り処理」プロパティ設定ダイアログで、以下の通り設定を行います。
◎必須設定
[名前]:コンポーネント名
[ファイル]:読み取り対象ファイルの格納先フォルダ/ファイル
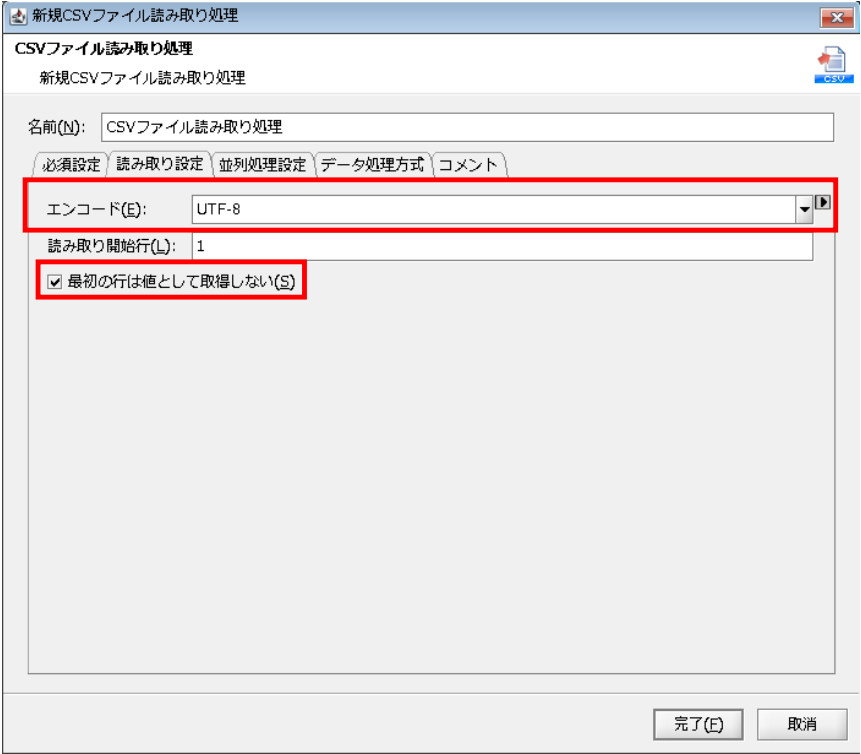
◎読み取り設定
[エンコード]:読み取り対象ファイルのエンコード
[最初の行は値として取得しない]:ファイルの読み取り開始行をデータとして扱うか選択
【6-3】
[ファイルの一行目から列名を読み取り]をクリックします。
【6-4】
ファイルの選択画面が表示されるため、今回のデータ入力元CSVファイルである「/data/work/test/顧客データ.csv」を選択し、[表示キャラセット]をUTF-8に変更します。
ファイルの中身が正常なことを確認し、[開く]を押下します。
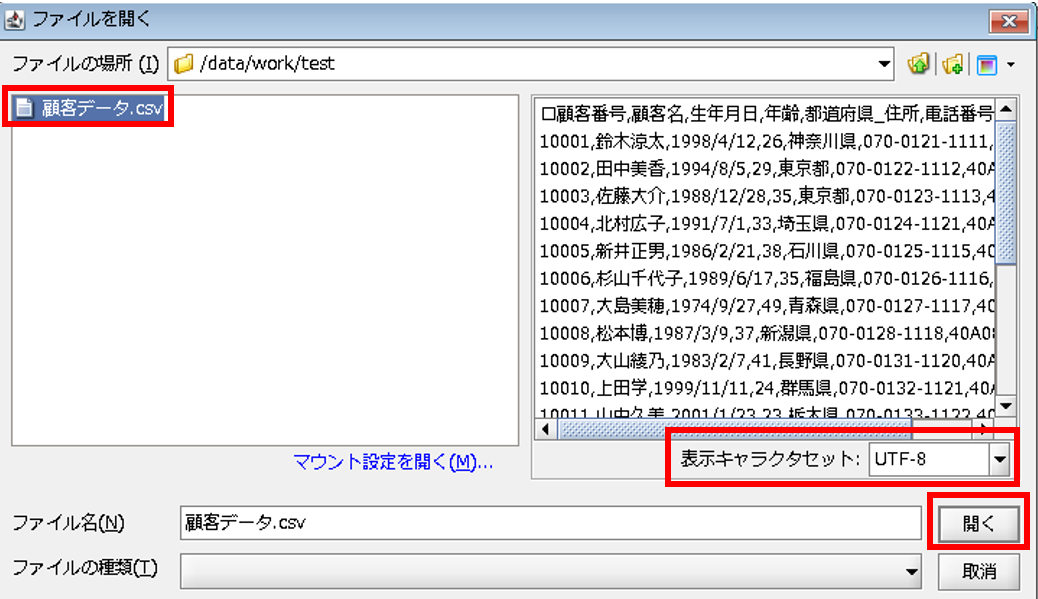
【6-5】
列一覧に列名がセットされます。
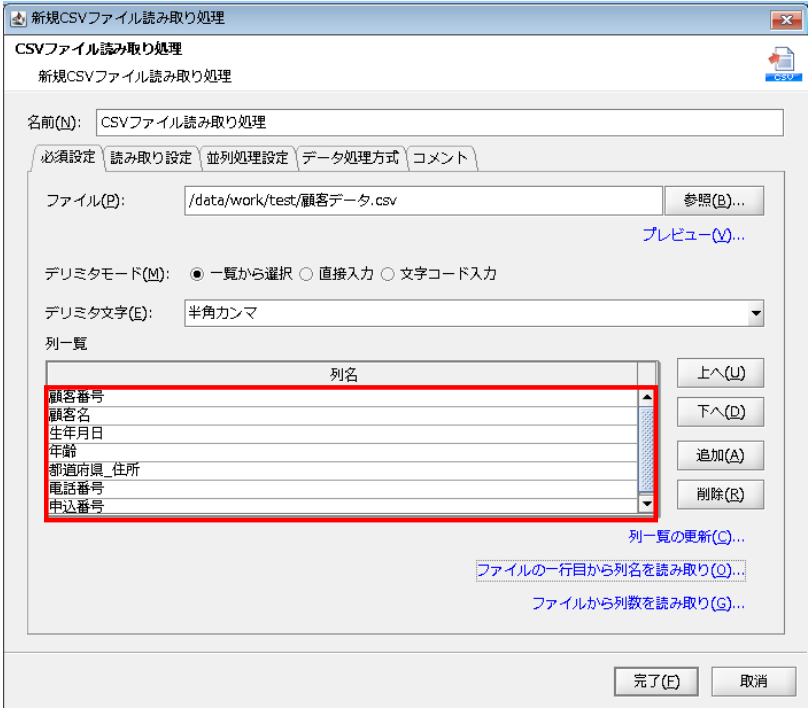
【6-6】
[完了]を押下すると、プロパティ設定ダイアログが閉じ、「CSVファイル読み取り処理」アイコンがキャンパスに配置されます。
読み取ったデータを書き込む、データベースの設定を行います。
【7-1】
ツールパレットから[データベース]-[PostgreSQL]-[テーブル書き込み]を、スクリプトキャンバスにドラッグ&ドロップします。
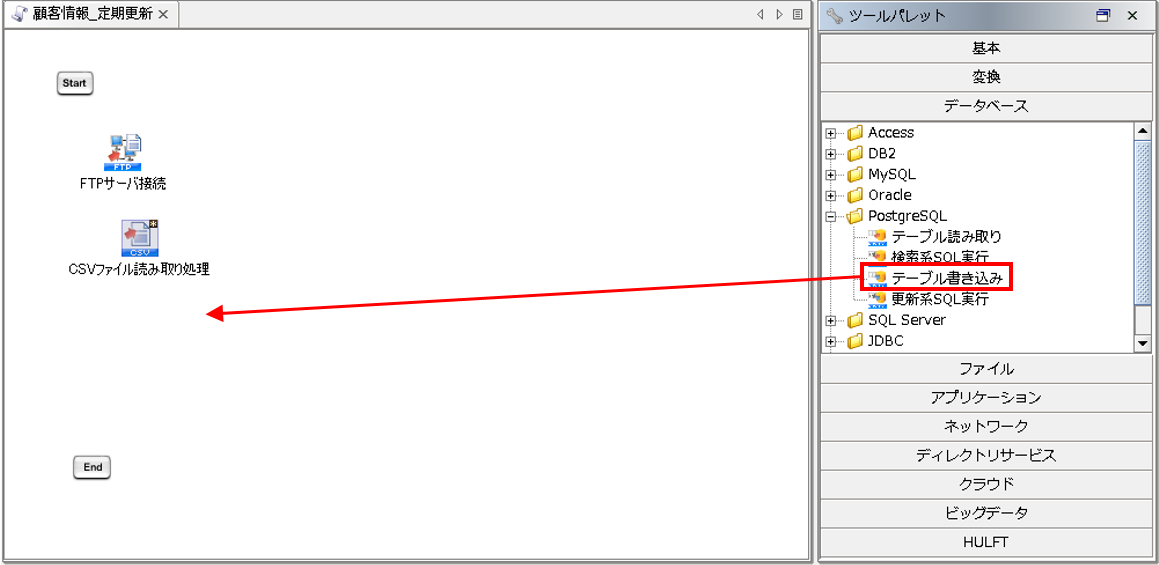
【7-2】
「テーブル書き込み処理」プロパティ設定ダイアログで、以下の通り設定を行います。
◎必須設定
[名前]:コンポーネント名
[入力データ]:入力データとなるコンポーネント名
[接続先]:グローバルリソースで設定済みの接続先
[テーブル名]:書き込み対象テーブル

【7-3】
[キーと値と一致する行は更新]にチェックを入れ、[スキーマ定義]で[列名]が、「顧客番号」の行の[キー]にチェックを入れます。
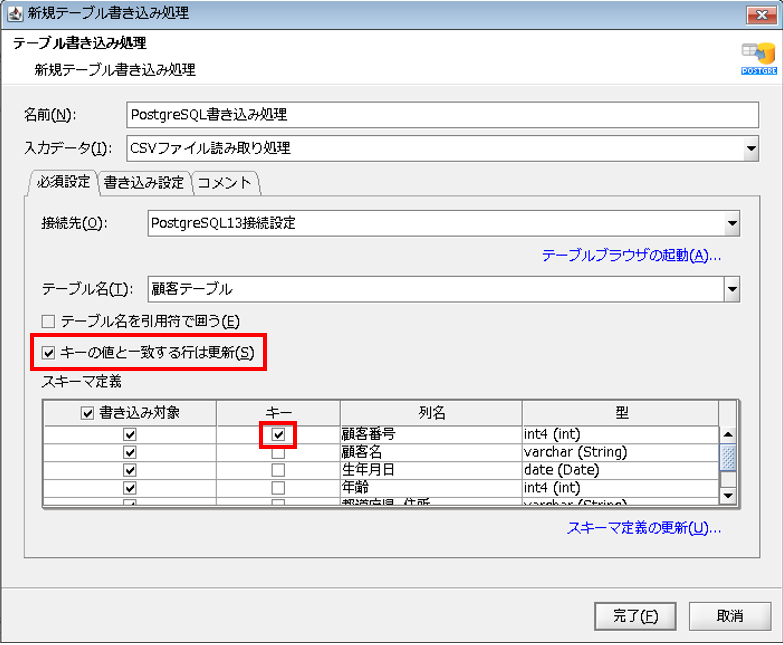
【7-4】
[完了]を押下すると、プロパティ設定ダイアログが閉じ、「PostgreSQL書き込み処理」アイコンがキャンバスに配置され、マッピングの追加ダイアログが表示されます。
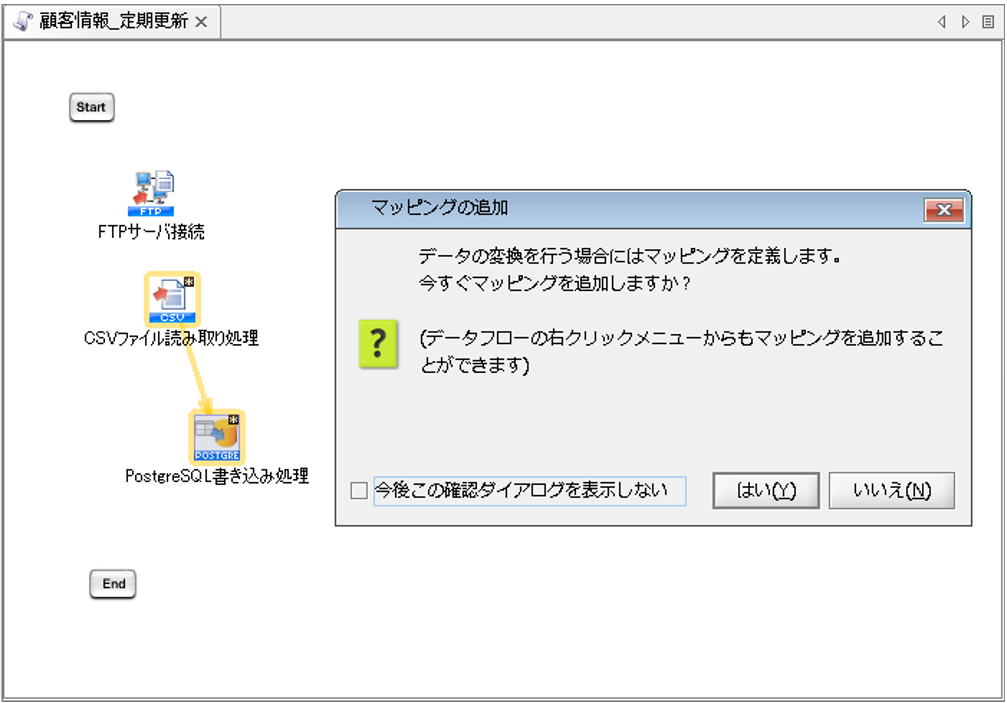
Mapperを追加し、連携元データと連携先データベースのデータ連携を作成します。
【8-1】
Mapper追加ダイアログの「はい」を選択します。
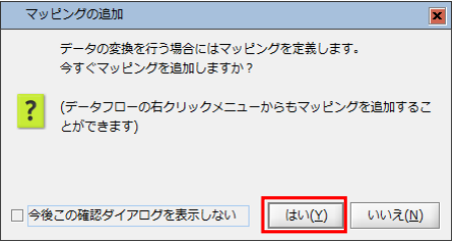
【8-2】
「CSVファイル読み取り処理」と「PostgreSQL書き込み処理」の間に、「mapping」アイコンが配置されます。
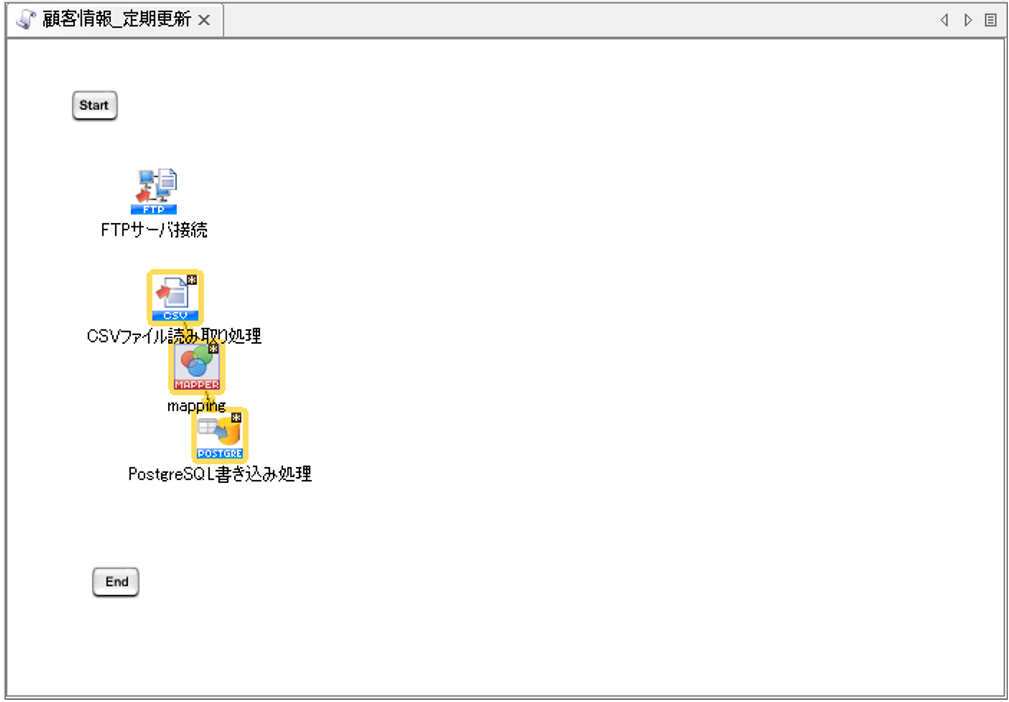
【8-3】
配置された「mapping」アイコンをダブルクリックし、Mapperエディタを開き、以下の通りにマッピングリンク、マッピング定義を作成します。
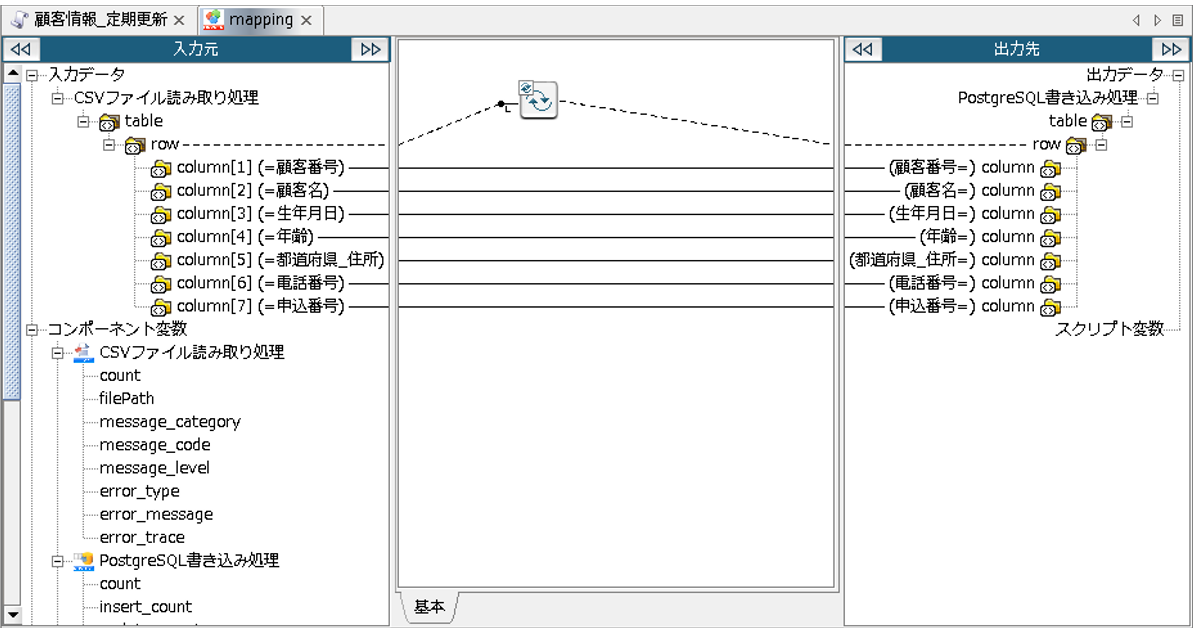
以上で、マッピングの完成です。
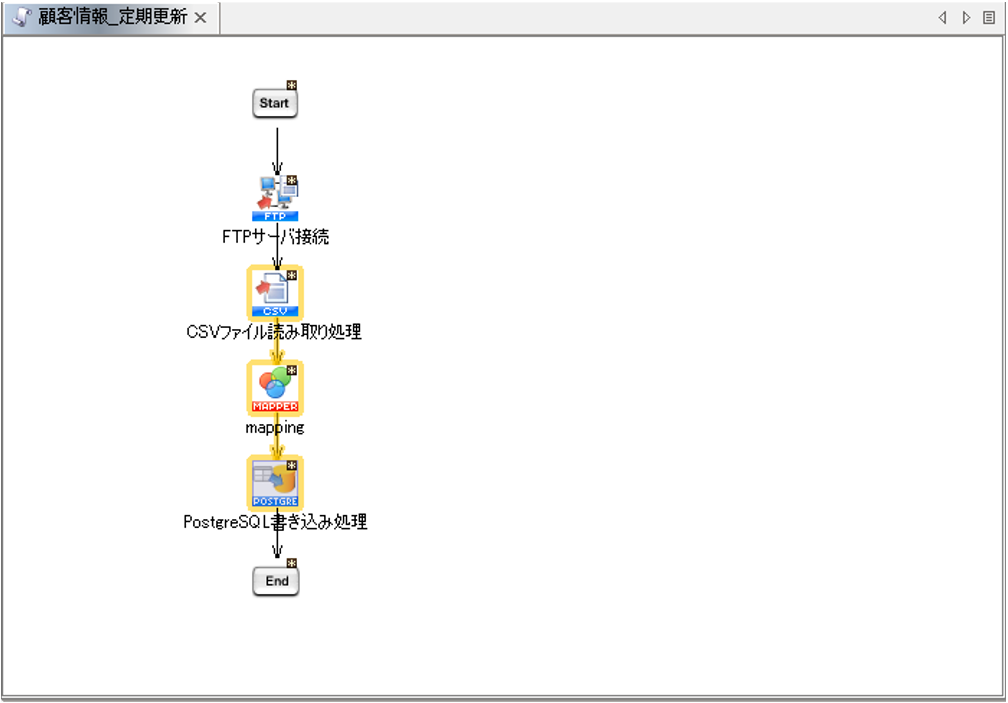
正常にスクリプトを実行させるため、設定した各アイコンを順番に繋ぎます。
処理の順番にプロセスフローを引きます。
(「Start」→「FTPサーバ接続」→「CSVファイル読み取り処理」→「mapping」→「PostgreSQL書き込み処理」→「End」の順)
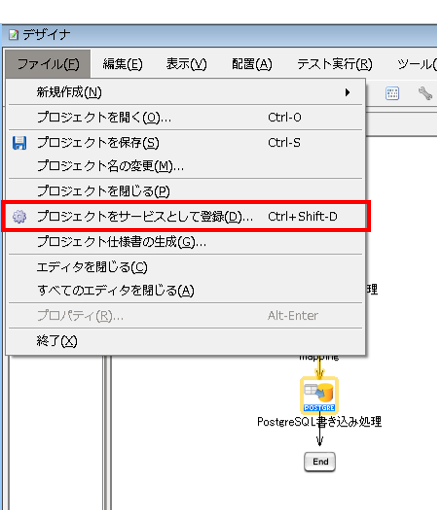
作成したスクリプトをスケジュールトリガーに設定するため、プロジェクトをサービスとして登録します。
【10-1】
[ファイル]メニューの[プロジェクトをサービスとして登録]を選択します。
【10-2】
[サービス名]を確認し、[完了]を押下します。
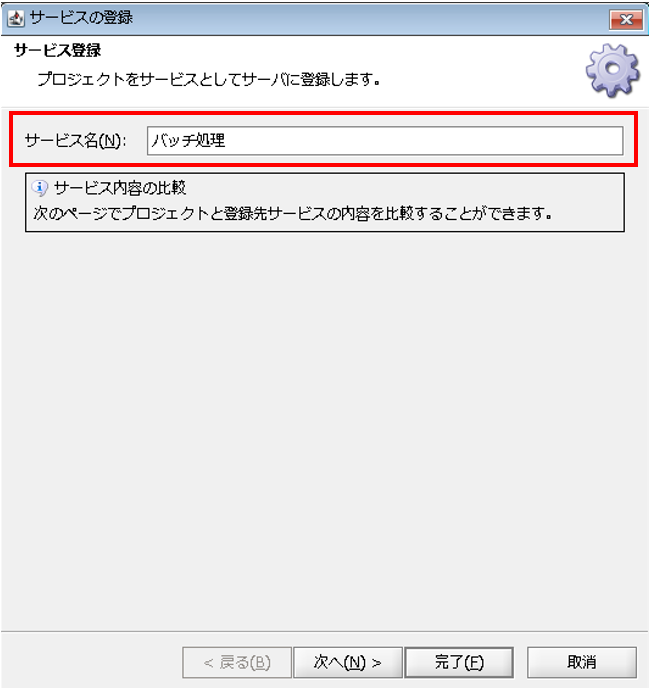
【10-3】
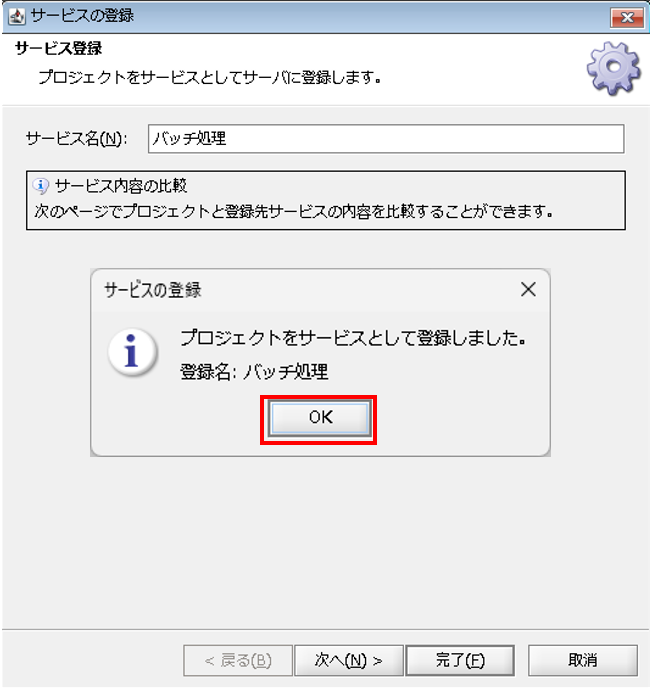
「サービスの登録」ダイアログが表示されるので、[OK]を押下します。
作成したスクリプトを指定したタイミング、スケジュールで実行させるため、スケジュールトリガーを作成します。
【11-1】
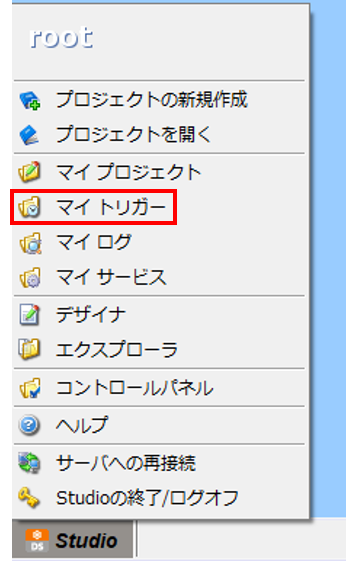
Studio のスタートメニューから、「マイトリガー」を選択します。
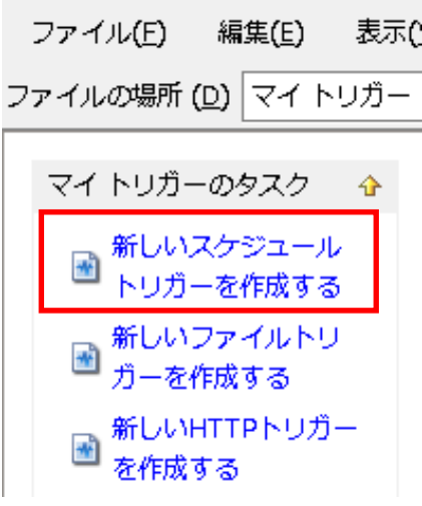
「マイトリガーのタスク」で[新しいスケジュールトリガーを作成する]を押下します。
【11-2】
まず、「スケジュールトリガー」プロパティ設定ダイアログが表示されるので、設定を行い[次へ]を押下します。
◎設定内容
[指定スケジュール]:実行スケジュールの選択
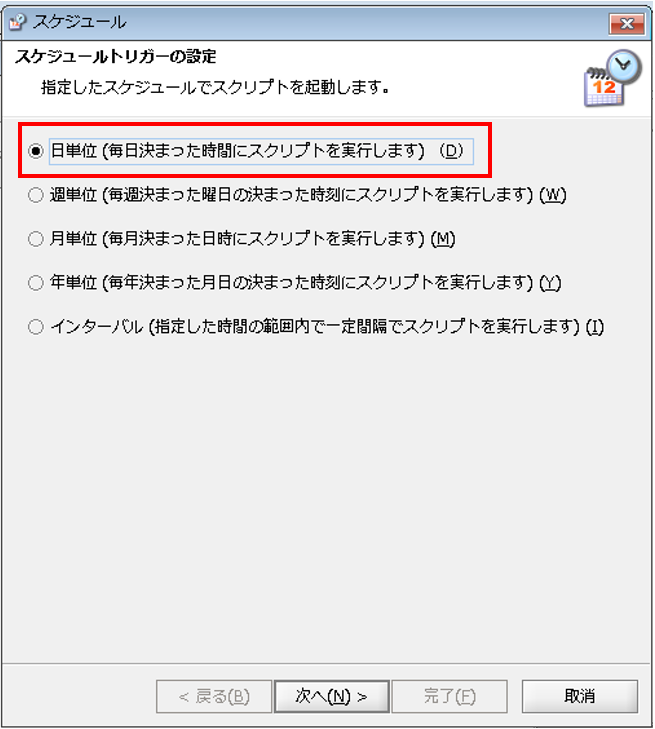
次に、「日次スケジュール」プロパティ設定ダイアログが表示されるので、設定を行い[次へ]を押下します。
◎設定内容
[トリガー名]:トリガーの名前
[実行開始時間]:スケジュールの開始時間
[有効期限の開始日]:スケジュールが有効になるタイミング
[有効期限の終了日]:スケジュールが無効になるタイミング
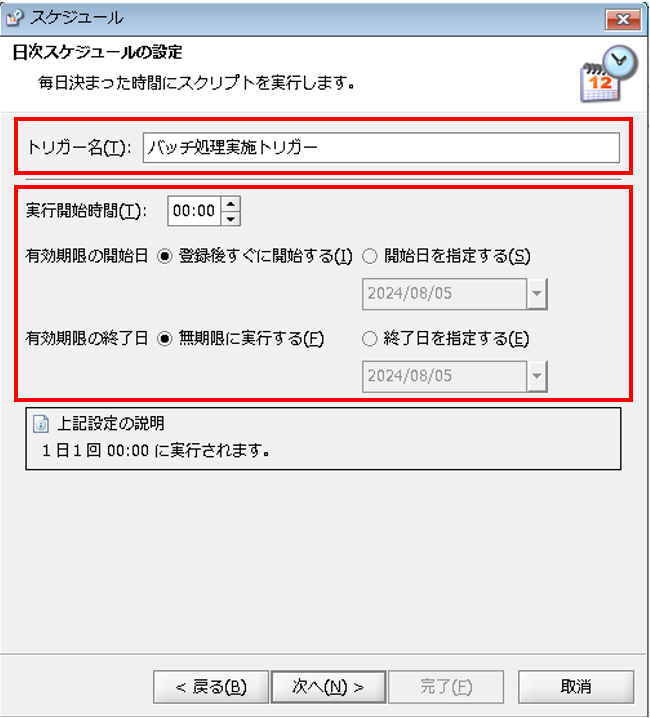
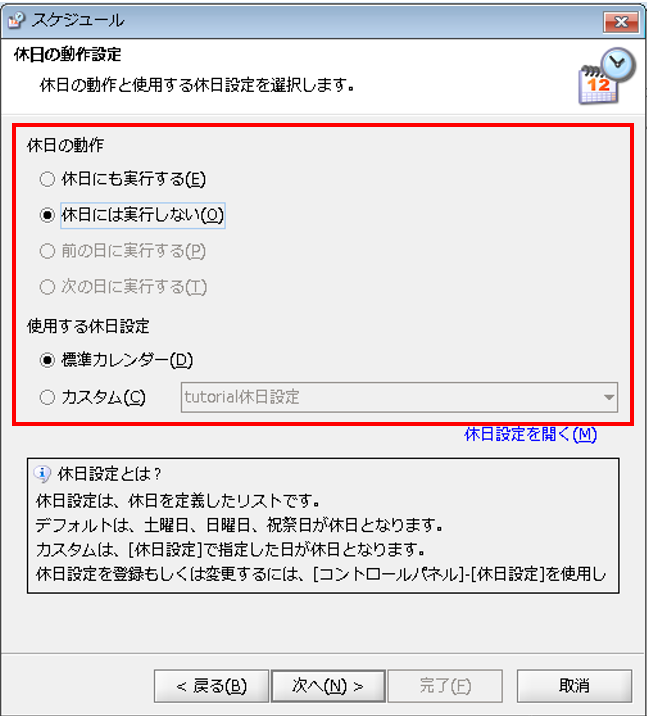
最後に、「休日の動作」プロパティ設定ダイアログが表示されるので、設定を行い[次へ]を押下します。
◎設定内容
[休日の動作]:休日の実行可否の選択
[使用する休日設定]:休日を反映するカレンダーの選択
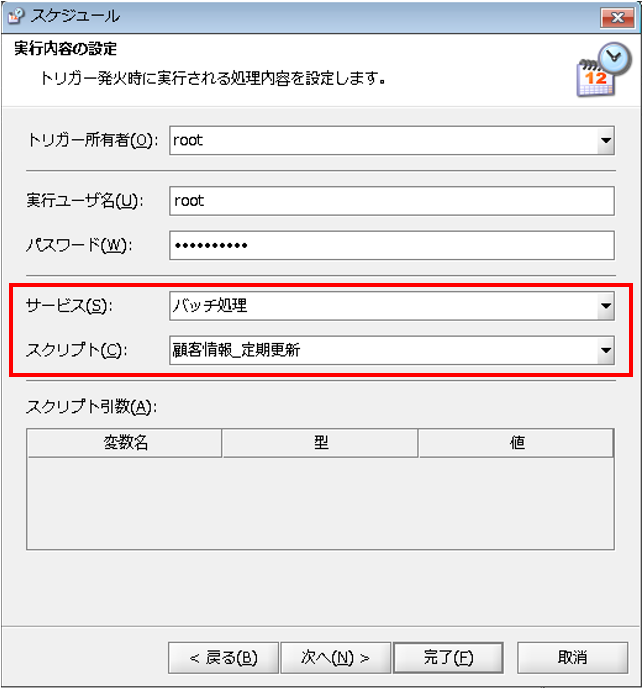
【11-3】
トリガー発火時に実行されるスクリプトを設定し、[完了]を押下します。
◎設定内容
[サービス]:トリガーで実行するスクリプトを含むサービス
[スクリプト]:トリガーで実行するスクリプト
「トリガー有効の確認」ダイアログが表示されるので、[はい]を押下します。
※[いいえ]を押下するとトリガーが無効状態で登録されます。
【11-4】
設定したトリガーの確認
マイトリガーで、設定したスケジュールトリガーが表示されていることを確認します。これにより、登録したスクリプトが毎日0時に実行されます。

スケジュールトリガーの正常発火、またそれによって作成したスクリプトの処理が正常に終了しているかどうかを確認します。
【13-1】
マイトリガーで、設定したスケジュールトリガーの「最終実行日時」、「最終実行結果を確認します。

正常終了していることが確認できたので、更新対象テーブル「顧客テーブル」の中身を確認します。

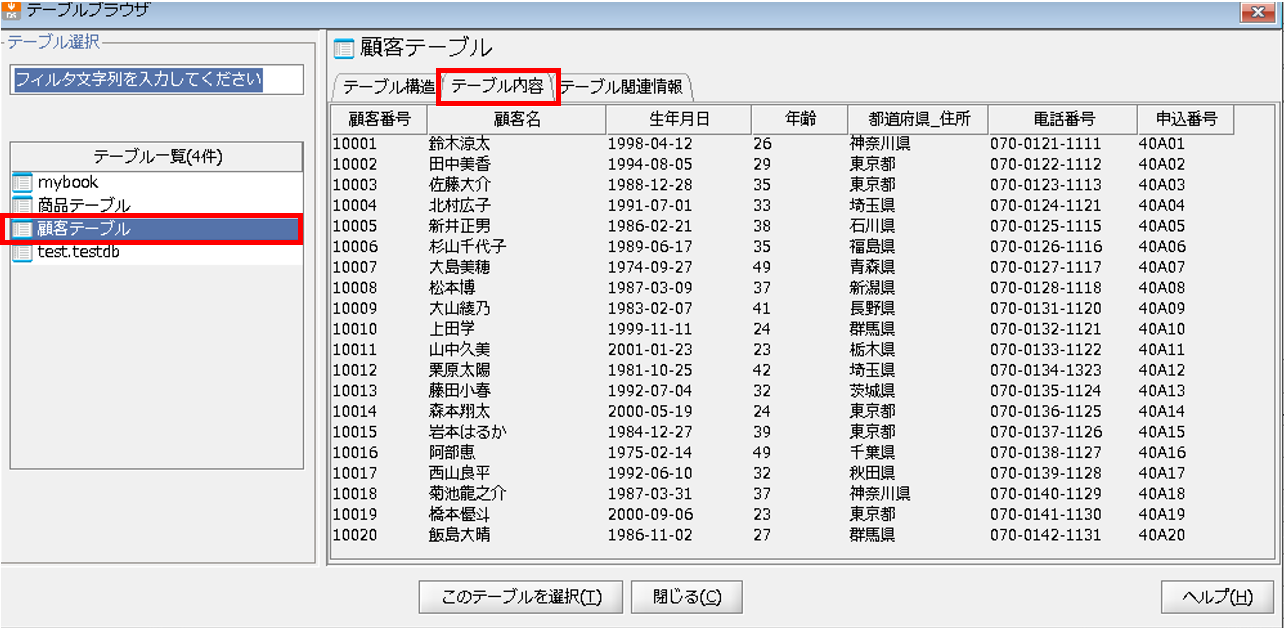
データベースが正常に更新されていることが確認できました。
以上が、毎日指定時間になると他サーバからFTPで取得したCSVファイルからのデータをデータベースの更新対象テーブルへ自動で書き込まれるという連携の作成手順説明になります。
何でもお気軽にご質問ください