
技術情報コラム
pSeven技術情報コラム第一回(ユーザー様向け)
構築・検証・探索 Part 1:Smart Selection

目次
- 1. Smart Selectionとは?
-
2. Smart Selection適用事例:スタティックミキサーの最適化
- 2-1 入力データ情報
- 2-2 高度なヒント
- 2-3 マニュアルモード vs Smart Selection
- 2-4 さらなる機能
1. Smart Selectionとは?
Smart Selection機能は、pSevenの設計空間探索および予測モデリングのツールに含まれる手法で、与えられた問題とデータの種類に対して最も適切な近似モデルとオプション解決策を自動的に選択するモデルトレーニング機能(機械学習のモデルを自動的に調整し構築する機能)です。
Smart Selectionとは?2. Smart Selection適用事例:スタティックミキサーの最適化
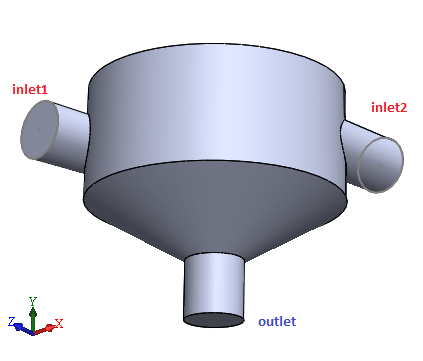
pSevenパッケージの解析サンプルにある、シンプルなスタティックミキサーを例として取り上げます。DOE(実験計画法)機能にてサンプルデータを使用して近似モデルを作成することで、目的のプロセスについて検証することが可能です。
このDOEサンプルには以下の入出力パラメータを含む200点のデータがあります。
- 入力(4パラメータ):ノズル角度、ノズル径、流速1、流速2
- 出力(2パラメータ):流体温度、圧力損失
2-1 入力データ情報
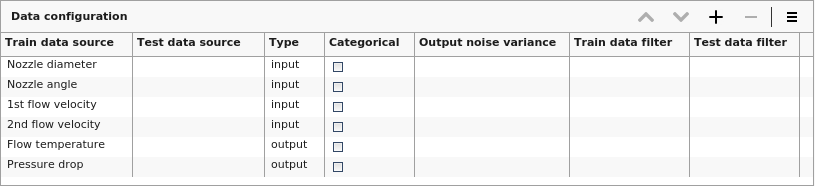
サンプルには最低限の情報しかありませんが、データがもっと多ければ近似精度の向上が見込めます。
- 検証用のテストデータセット(デフォルトではクロスバリデーションが適用されます)
- トレーニングサンプル中の入力データの重み
- トレーニングサンプル中の出力ノイズの分散
- カテゴリカル変数のマーク付け
- トレーニングサンプル、データサンプルのデータフィルター(外れ値の除外など)
2-2 高度なヒント
ドメイン知識、モデル要件、時間/品質の制約、の3つのグループについて、より高度なヒントを設定可能です。
-
① 目的のプロセスに関するドメイン知識
事前知識の適用により探索する設計空間の範囲が制限され、トレーニング時間の削減や、最終的なモデルの予測性能の向上に繋がります。- プロセスが非線形 or 不連続
- 入力データにノイズが多い
- 出力データ間の傾向や相関
-
② モデル要件
- モデルが滑らかな(微分可能な)近似関数である必要があるか
- 予測の不確実性を評価できる必要があるか
- トレーニングサンプル中で出力がNaN(無効データ)となっているデータポイント付近の領域でNaNを返し、モデルがトレーニングデータを正確に再現する必要があるか。
-
③ 時間の制約と品質のコントロール:時間と品質のトレードオフ
- このサンプルケースでは、許容可能な品質としてクロスバリデーションでのR2=0.99を定義
- 計算を行う時間の制限:毎夜に実行
インターフェース上では、タグとして設定したヒントを確認できます。

Smart Selectionアルゴリズムは設定した事前知識、モデル要件、時間/品質のトレードオフにて選択を開始します。
近似の精度は3種類の方法で評価することが可能です。
- ① 内部検証(トレーニングデータでのクロスバリデーション)
- ② トレーニングサンプルの一部をテスト用に分割して利用
- ③ トレーニングサンプルとは別のテスト用データセットの利用
各出力変数をベクトルとして(多次元で)出力する形で、最適なモデルが構築されます。
2-3 マニュアルモード vs Smart Selection
近似手法を深く知りたいコアユーザー向けに、全ての項目を設定可能なマニュアルモードも搭載しております。しかしながら、Smart Selectionはマニュアルモードと同等かそれ以上の近似精度となることが多いです。
2-4 さらなる機能
近似モデルを構築した後は、モデルバリデーター、スムージングの追加、他のフォーマット(C言語、Octave、FMIなど)での追加検証により、新しいデータでのバリデーションや、他のモデルとの比較が可能です。
今回のpSeven技術情報コラムでは、Part1として、Smart Selection機能とその適用事例についてご紹介しました。次回の構築・検証・探索 Part 2では、モデル品質の評価(予測性能など)や他のモデルとの比較を行う対話型分析ツールである、モデルバリデーターについて解説します。リファレンスデータに対するモデルのテスト、エラープロットや統計データを使用したモデル精度の確認などが可能です。さらに、構築・検証・探索 Part 3では、「モデルの中身」を見る方法を説明し、対話型の可視化ツールであるモデルエクスプローラーによりモデルの挙動を探索していきます。
- ※掲載されている製品、会社名、サービス名、ロゴマークなどはすべて各社の商標または登録商標です。
製品・サービスに関する
お問い合わせ・資料請求
ご質問、ご相談、お見積もりなど
お気軽にお問い合わせください。
プロダクト営業部
TEL:03-5859-3012
E-mail:eng-sales@scsk.jp お問い合わせフォーム

