
今日は何を買おうかな?

2021年になり、レコメンデーションエンジンがあちこちで見られるようになりました。オンラインショッピング、食品、音楽、そしてオンラインデートであっても、ユーザーにパーソナライズされたレコメンデーションを提供する競争は、多くの競合が存在します。ユーザーの購買戦略やデジタル上での相互作用に基づいて、ユーザーが必要とするものを提供する技術は実に強力であり、徐々に浸透しつつあります。当然ながら、私はかなり以前からこの分野の探求に興味がありました。今回、「Kaggle BIPOC Program 2021」の助成対象者になる機会を得たことで、プログラムの成果物として取り上げることにしました。
プロジェクトの目的は、ユーザーの購買履歴をもとに、各ユーザーにパーソナライズされた商品をレコメンドすることです。そのために、いろいろと調べた結果、協調フィルタリングを導入することにしました。協調フィルタリングは、ユーザーと商品の過去のやりとりを利用して、ユーザーがどのような商品を好むかについてインテリジェントに予測するものです。私は、行列因子法(Matrix Factorization Algorithm)が有名であることから、このアルゴリズムを使用することにしました。
行列因子分解とは?
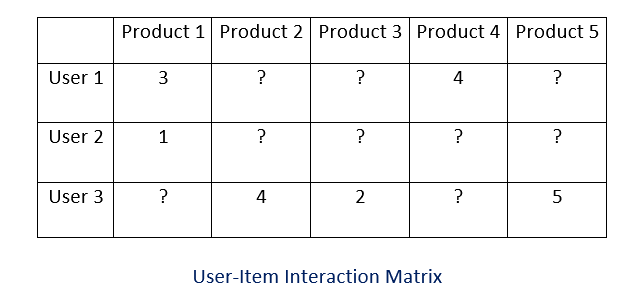
簡単に言うと、行列因子分解とは、1つの行列を2つの等価な行列に分解し、その積で元の行列を得るための手法です。我々のレコメンデーション問題を行列因子分解のようにモデル化するためには、ユーザーと商品間の相互作用を一つの行列にする必要があります。この行列は、すべてのユーザーを行、すべての商品を列とし、商品の評価を行列の値とします。
簡単に言えば、このアルゴリズムはユーザが既にレビューした製品に基づいて、「?」というラベルが付けられたエントリの値を予測します。このモデルはH2O.aiのGPUパッケージを使用して構築されており、GPUに最適化されているため、sklearn.NMFライブラリよりも高速な処理を実現しています。
データセットの準備
Amazon Reviews Datasetを利用して、異なる商品カテゴリのレビューとメタデータを結合し、モデル構築の準備をします。入力データセットをトレーニングセットとテストセットに分割する際、テストセット内のユーザーと製品の一意なリストはトレーニングデータ内のそれらのサブセットであることに留意する必要があります。なぜなら、行列分解アルゴリズムは新しいユーザー(つまり、購入履歴が無いユーザー)や新しい製品(トレーニングデータ内で、どのユーザーにも購入/評価されていない製品など)に対する予測を行えないためです。
モデル構築
RMSEを評価行列として、ハイパーパラメータ(n_components, lambda, max_iters)の組み合わせを変えてモデルをチューニングし、最も誤差が小さくなる組み合わせを選択しました。そして、モデルは、前述のハイパーパラメータの最適な組み合わせを使用して、データセット全体(トレーニングとテストの両方)に最適化されました。
このデータセットはロングテールであったものの、誤差は少なくほぼ満足のいく結果を得ることができました。さらに学習データを追加し、各ユーザーがより多くの履歴データ(異なるカテゴリに対する多様な購入履歴)を持つようにすれば、アルゴリズムがよりよく学習し、より適切なレコメンデーションを行えるようになります。
ウェブアプリの構築
プロジェクトの最終成果物は、H2O Waveを使って作られたWebアプリケーションです。左側にユーザーの購入履歴、右側に各ユーザーに特化したおすすめ商品トップ10を表示するシンプルなダッシュボードになっています。ユーザーの選択は、50人程度のユーザーを入力したシンプルなドロップダウンを使って行うことができます。このアプリの簡単なデモをご紹介します。

H2O Waveを使うことの特典の1つは、簡単なPythonのコードを使ってリアルタイムのWebアプリケーションを構築できることです。私はフロントエンド技術の経験があまりないので、新しいフロントエンド技術を短時間で習得することに少し不安を感じていました。しかし、H2O Waveの簡潔で有用なドキュメントにより、非常に分かりやすいプロセスになっています。また、MLモデルを本番環境にデプロイする際のプロセスや課題についても理解を深めることができました。
次のステップは?
パイプラインが完成したことで、様々な実装を検討することができるようになりました。より多くのデータを学習に取り込むことは別として、類似性のような有用な情報だけでなく、異なる評価を捉えられるモデルを分析するのは興味深いことです。その他の改善点としては、以下のようなものが考えられます。
- SVD、Gradient Descentを用いた行列因子分解アルゴリズムの実装
- 平均予測値のような他の評価指標の検討
- コンテンツベースのフィルタリング、ブースティング、ハイブリッドモデルなど、他のアルゴリズムのトライアル。
- 商品レコメンデーションに加え、商品レビューなどの追加データがユーザーの購買行動に与える影響の把握
- フィードバックループを組み込むことにより、モデルのレコメンドとユーザー行動の関連性の探求
そのゴールは、時間とともに進化し、スムーズなユーザー体験を提供することができる高度なインテリジェントシステムを構築することです。
原題
(公式)H2O.ai Blog
What are we buying today?
Rohan Rao