コンテナ+ Kubernetes監視、アラートの実行、トラブルシューティングを実現
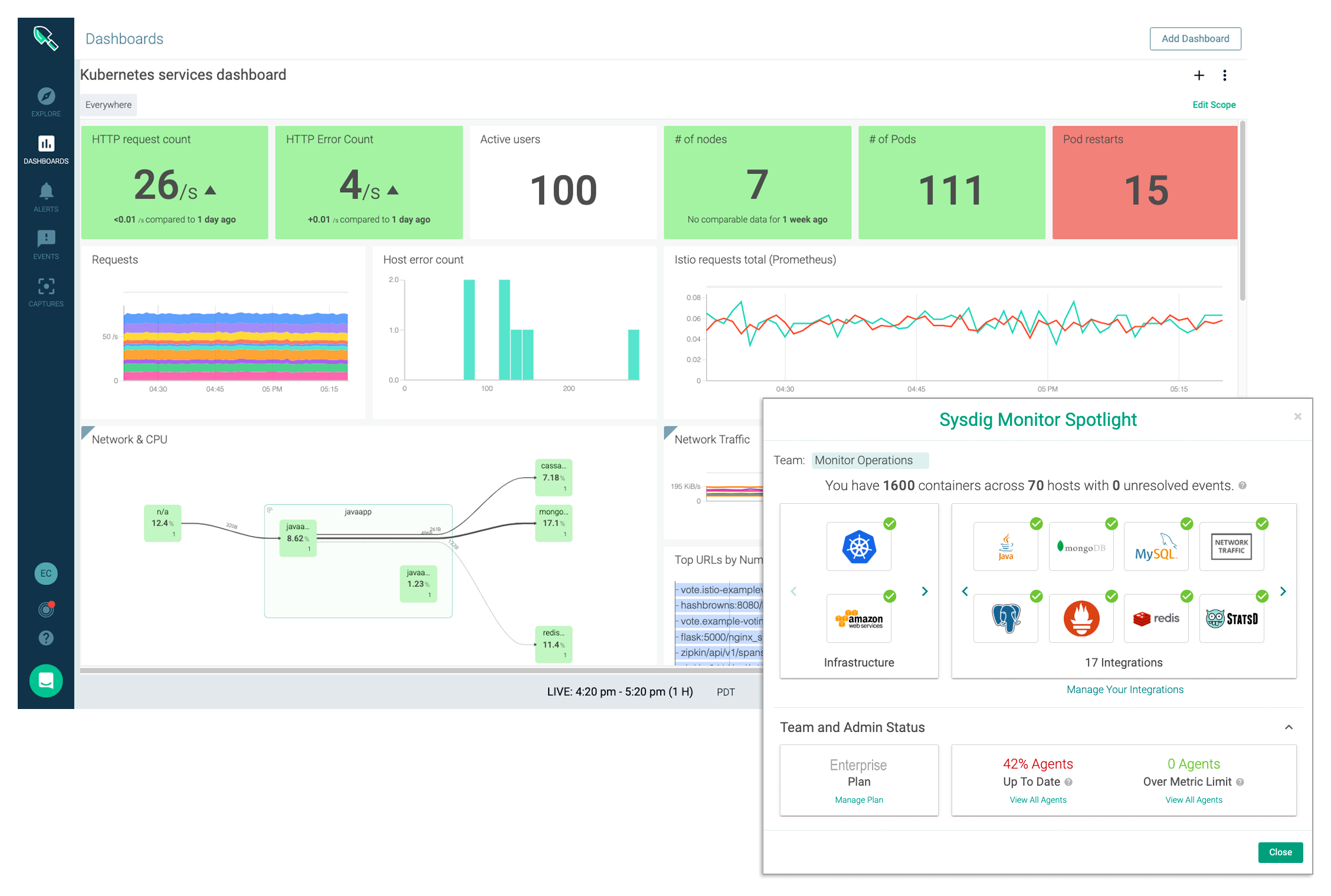
Sysdig Monitorは、複数のクラウド環境を統合したKubernetesクラスタおよびコンテナのヘルスチェック、リスク・マネージメント、マイクロサービスのパフォーマンス管理を実現します
アプリケーションのパフォーマンス情報、ホストとコンテナ、Prometheus、JMX、StatsDメトリクス、サービスメッシュとネットワークの状態、およびオーケストレーションなど、ノードごとに1つの計測ポイントからこれら全ての情報を取得します。
Node Exporterを経由してPrometheusのメトリクスを取り込むことで、エンタープライズ・クラスのPrometheus運用とトラブルシューティングを可能にします。
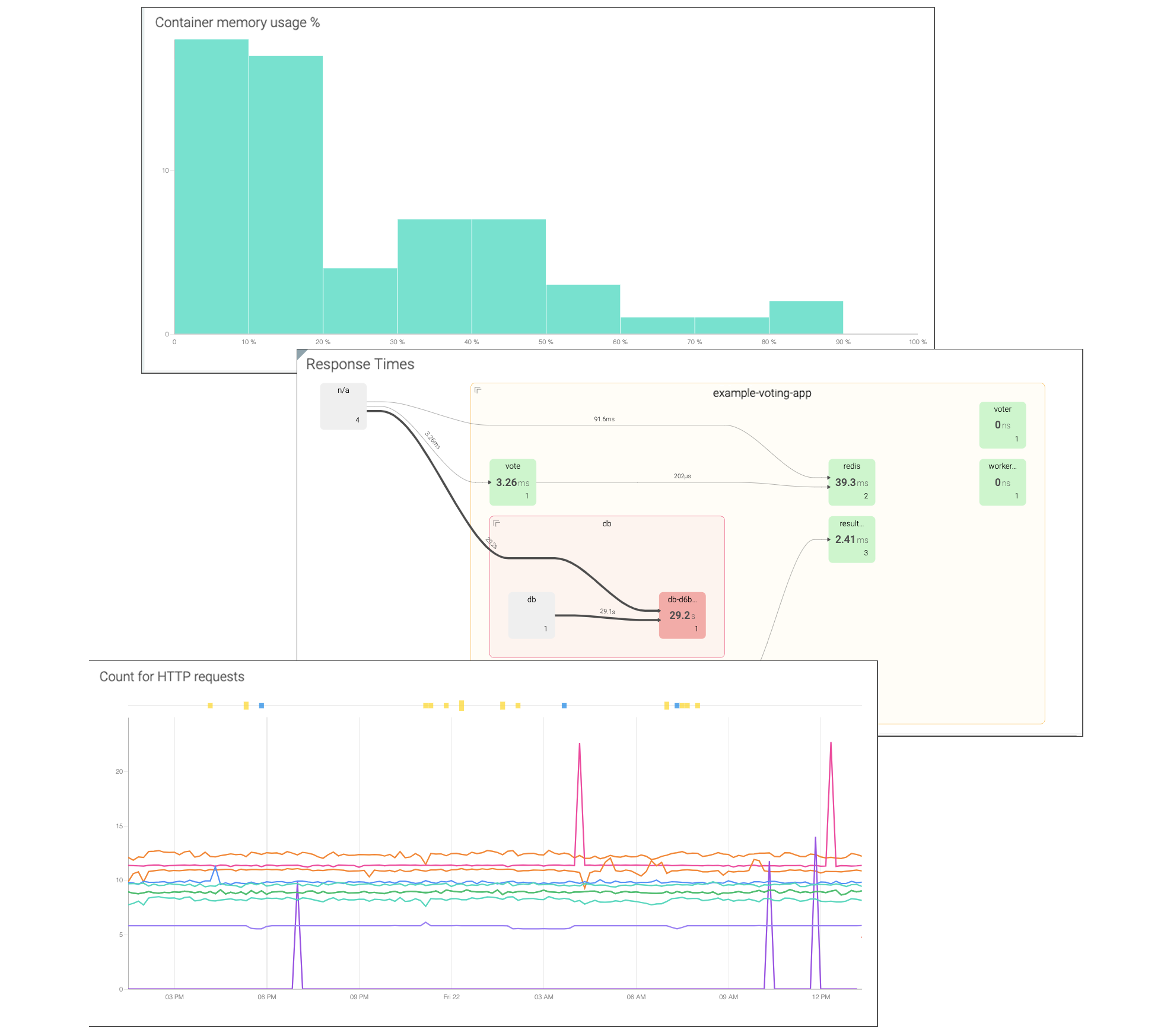
リアルタイムでのトラフィックの状況やボトルネックの特定、マイクロサービスのストリーム・ラインや相関関係を把握できます。

各コンテナやKubernetes、 CI/CDパイプラインで発生したイベントも参照可能です。
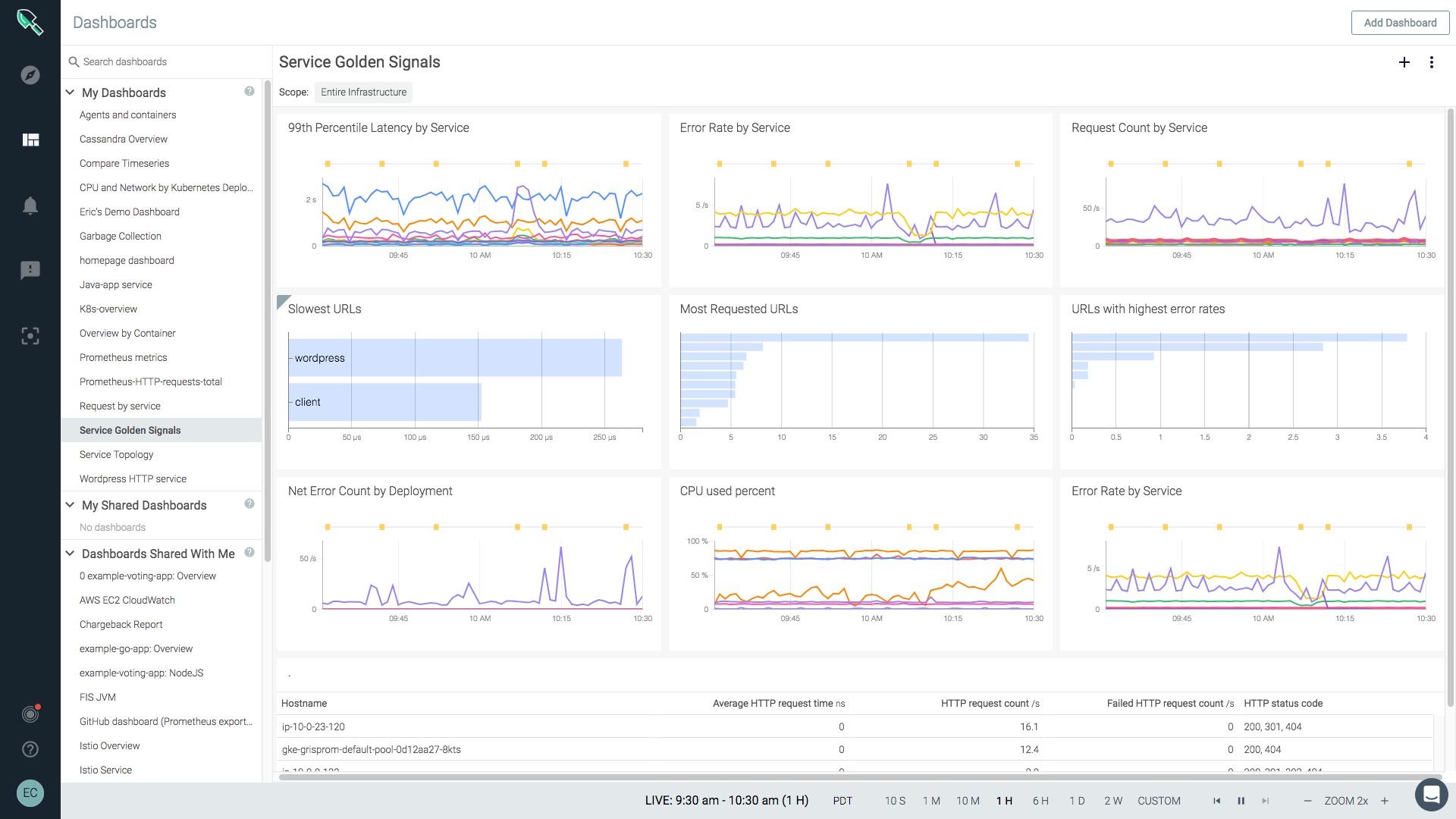
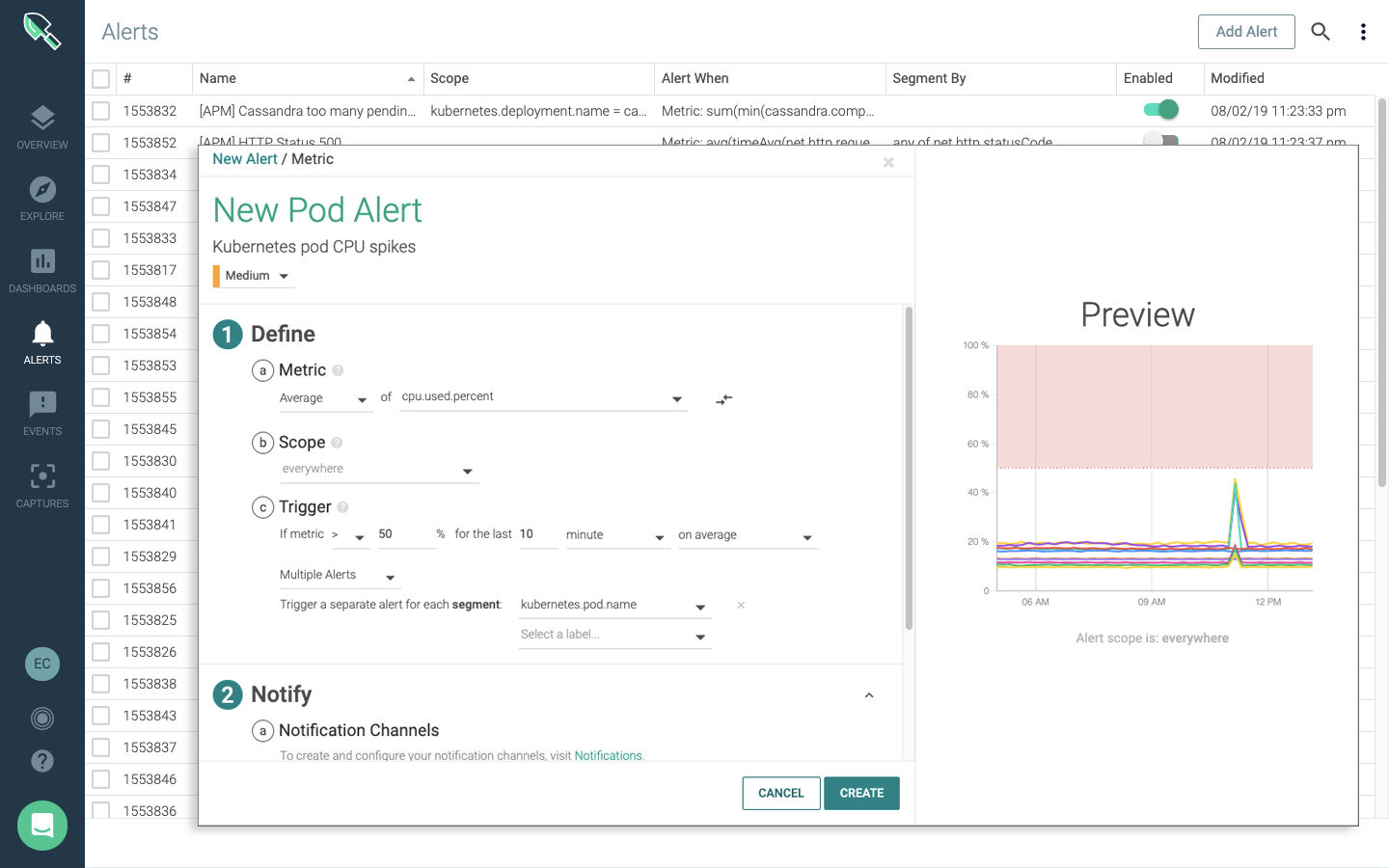
カスタム・アラートの作成も可能で、
ServiceNow、PagerDuty、Slack、VictorOpsなどのインシデント管理ツールに通知を送信します。
アラート前後におけるシステム・キャプチャも自動で取得し、トラブルシューティングを実現します。
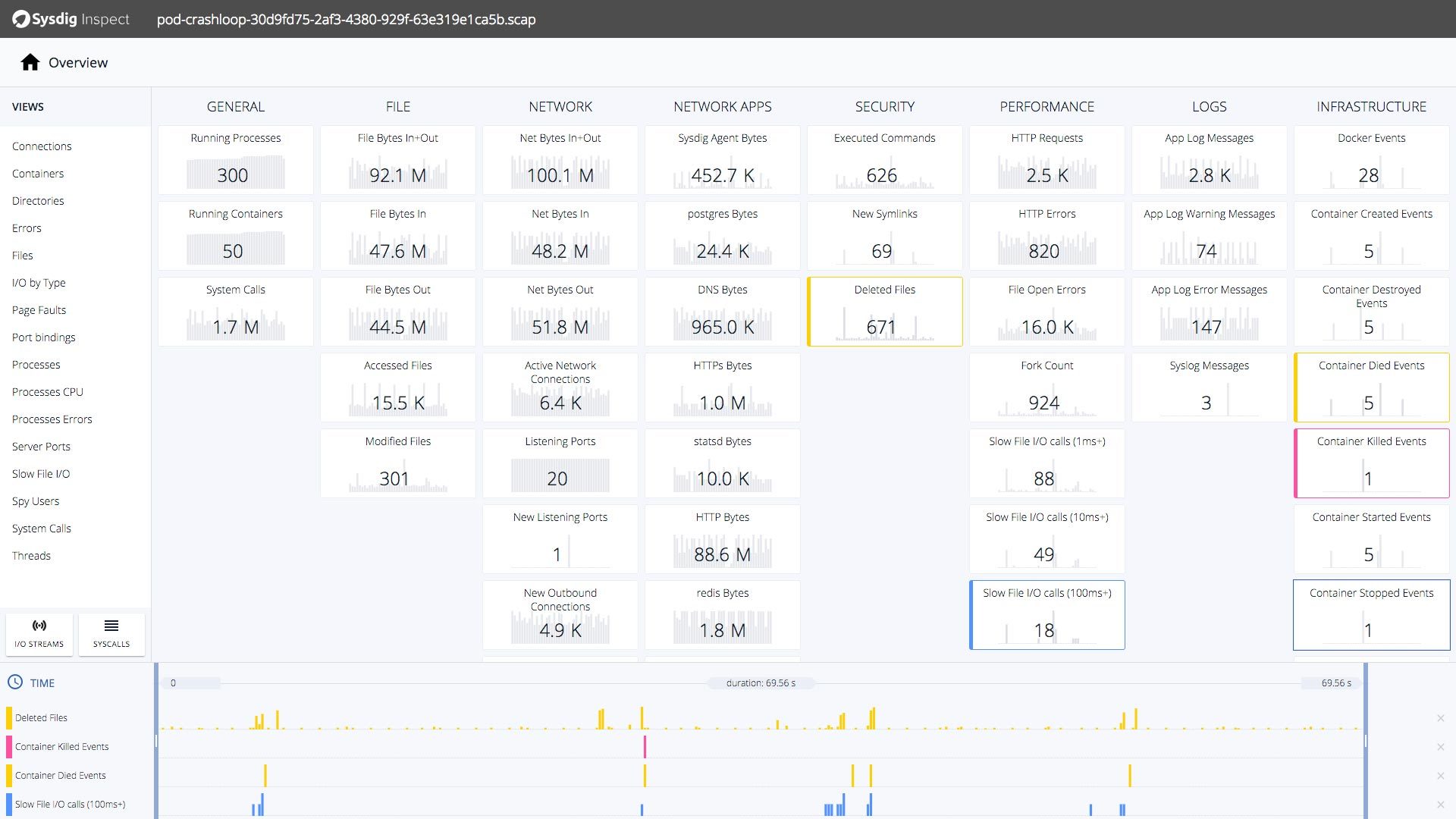
たとえコンテナが消え去ったあとでも、イベントを検知した前後のシステムコール・キャプチャを自動的に取得可能なため、オフライン環境で問題の根本原因を追究していくことが可能です。
データやダッシュボードは、チーム・ユーザー・顧客・環境毎など、任意の単位で設定することが可能です。
コンテナ、ネームスペース、サービス、ホストなどへの明示的なアクセスを提供します。