

こんにちは、SCSK株式会社 R&Dセンターの齋藤です。
第2回ではライントレーサーを題材にして、自前の環境で深層強化学習を行う方法をご紹介しました。
教師あり学習のように学習データを準備する必要はありませんが、学習を行う環境を設計する必要があると理解して頂けたと思います。
ライントレーサーでは、環境の中に1つのエージェントが自由に動き回っていました。
しかし、解決したい課題によっては複数のエージェントを環境に定義する必要があります。
例えば、囲碁や将棋などの対戦を学習する場合、対戦相手がいないと学習を進めることができません。
また、大縄跳びを学習する場合には、縄を回す人と縄を飛ぶ人の複数のエージェントが必要になります。
今回は「3目並べ」を題材に対戦相手がいる場合の深層強化学習について考えていきます。
3目並べとは
ご存知だとは思いますが、今回の題材である3目並べとは、3×3のマスにマルとバツを交互に入れていき、先に縦・横・斜めのいずれかで3個連続のマル又はバツを並べる対戦ゲームです。
また、今回は既に埋まっているマスにマルかバツを入れようとすると、その時点で反則負けとなるようにしています。
想定される対戦相手
まずは対戦相手の実装方法について考えます。
必ずしも対戦相手も強化学習エージェントでなければいけないということはありません。
「ランダムな行動を取る相手」、「ルールベースや教師あり学習など別の手法で作成したAI」、「強化学習エージェント」の3つが想定できます。
それぞれのメリットとデメリットを表にまとめました。
| ランダムな行動を取る | 別手法で作成したAI | 強化学習エージェント | |
|---|---|---|---|
| メリット |
|
|
|
| デメリット |
|
|
|
※1. 社会的ジレンマの問題:
社会全体にとっての最適な行動と、個人にとっての最適な行動に乖離が発生するという問題です。
複数のエージェントが存在すれば必ず発生するという訳ではなく、個人間での協力や裏切りによってそれぞれの報酬が変動する場合にこの問題が発生します。
ここでは有名な「囚人のジレンマ」をご紹介します。
共犯罪の容疑者である囚人A, Bが警察から別々の部屋で尋問を受けています。
・2人とも黙秘を続けた場合、証拠不十分で刑期は1年
・どちらか1人だけが自白をすれば自白した人は司法取引により刑期0年、黙秘をした人は10年
・2人とも自白をすれば、2人とも刑期は5年
| 囚人B 黙秘 | 囚人B 自白 | |
|---|---|---|
| 囚人A 黙秘 | (1, 1) | (10, 0) |
| 囚人A 自白 | (0, 10) | (5, 5) |
この時、囚人A, Bは共に黙秘をすることが2人にとって最適な行動であると判断できます。
しかし、個人にとっての最適な行動を考えてみましょう。
囚人Bが黙秘した場合、囚人Aは自白をした方が幸せになれます。
囚人Bが自白した場合、こちらも囚人Aは自白をした方が幸せになります。
つまり、囚人Bがどちらの選択をした場合であっても囚人Aは自白をした方がよいと判断します。
囚人Bにとってもこれは同じであるため、個人だけの最適な行動を考えるだけでは絶対に2人とも自白を選択することになります。
この乖離が社会的ジレンマと呼ばれ、強化学習においても発生する可能性があり、最適な行動を学習できない1つの要因となります。
3目並べ程度であればルールを実装することで強力な対戦相手を作り上げることは簡単です。
また、デメリットである予想外の行動を取らないということに対しては、適度にランダムな手を打つように実装すれば対策可能です。
しかし、大抵の場合は対戦相手を実装することが困難なので深層強化学習という手法を選択しているはずです。
そのため、今回は強化学習エージェントを対戦相手とします。
3目並べであれば対戦相手との協力などはないため、デメリットである社会的ジレンマの問題が発生することはありません。
また、対戦相手も自分と同じように学習すれば問題ないため、自分自身を対戦相手とすることで学習させるエージェントは実質1つで済みます。
深層強化学習で3目並べを実装
いつも通り「エージェント」、「環境」、「3つの相互作用」を定義します。
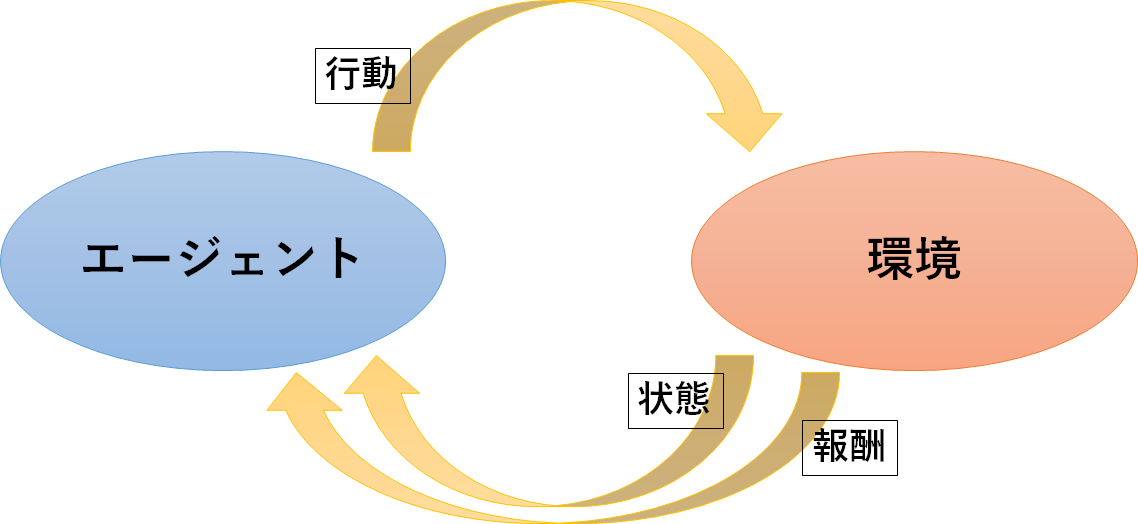
エージェント
深層強化学習ですので、ニューラルネットワークを実装します。
今回も中間層の構成やアルゴリズムはCartPoleと同じにしています。
環境
3×3の盤面を用意します。
盤面を用意すると言っても、画像などを準備する訳ではなく3×3の配列を用意するだけです。
今回はPC上で動く3目並べを想定しているので、これで十分です。
仮に現実で動く3目並べエージェントを作成する際には、PC世界と現実世界のギャップを埋める必要があるため、
盤面の画像を環境にして学習を実行するか、盤面の画像と3×3の配列を紐づける必要があります。
3つの相互作用
●行動
盤面のどこか1つのマスに石を配置します。
既に埋まっているマスであっても、選択することは可能になっています。
ただし、その場合は反則負けとなるため、埋まっているマスに配置してはいけないというルールも学習対象になります。
●状態
各マスを空・マル・バツの3通りとして、盤面全体を状態とします。
盤面は3×3の配列で表現をし、各マスは空の場合は(0, 0)、マルがある場合は(1, 0)、バツがある場合は(0, 1)と表現をしています。
●報酬
- ゲームに勝利すると、1点を与える
- ゲームに敗北すると̠-1点を与える
- ゲームに引き分けると、0.5点を与える
- ゲームが終了していない場合は、-0.001点を与える
報酬の設計は深層強化学習にとってとても大切なステップです。
今回、ゲームが終了しない場合はマイナスの報酬を与えています。
考え方として、反則負けをしなかったことに対してプラスの報酬を与えるということもできると思います。
しかし、エージェントは1つのエピソード(3目並べでは1ゲーム)でより多くの報酬を得ようとするため、
勝敗が決さないことにプラスの報酬を与えると、試合をわざと長引かせるように誘導することになります。
また、-0.001という値は、ゲームの勝敗への影響を少なくするためです。
仮にゲームが終了しない場合に-1の報酬を与えると、試合が長引くよりも早く敗北したほうが全体の報酬が良くなるため、思った通りに学習してくれません。
また、仮に1の報酬を与えると、早く勝つよりも試合を長引かせて引き分けにしたほうが全体の報酬が良くなるため、こちらも思った通りに学習にしてくれません。
この報酬を設定する際には、ゲームが終わるまでに発生する回数とゲーム終了時の報酬の大きさの2点を考慮する必要があります。
今回であれば、「最短で勝利した時の合計報酬 > 引き分け時の合計報酬 > 最短で敗北した時の合計報酬」という関係は最低限守る必要があります。
これを計算すると勝敗が決さなかった時の報酬は-0.75までであれば、この関係が破綻しません。
そのため、-0.001であっても-0.5であっても完成するエージェントの強さに大きな差は生じません。
この範囲内でどの報酬が一番良いのかは実際に試して確認してみるしかありません。
ただし、盤面の大きさが変わった場合は-0.1でもこの関係が破綻する可能性があります。
「学習を行う」の章で説明しますが、盤面の大きさは自由に変更できるようにしているため、報酬の値は十分に小さい-0.001としています。
このように報酬をどう与えるかによって、エージェントの学習方針が変わります。
報酬の与え方は1つに決まっている訳ではないため、試行錯誤が必要になります。
ChainerRLで実装
今回は自前環境用のPythonファイルとしてenv_n_moku.py、学習用のPythonファイルとしてchainerrl_n_moku.py、学習済みエージェントと対戦するためのファイルとしてn_moku_gui.pyを用意しました。
こちらのzipファイルを展開してください。
●自前環境用のPythonファイル
env_n_moku.pyに該当します。
このファイルでは環境だけではなく、3つの相互作用も定義します。
なお、このソースコードはMITライセンスのもと利用を許諾するものとします。
ライントレーサーと同じように、step()関数とreset()関数の定義が必須となります。
第2回でも述べましたが、2つの関数の主な処理内容は以下の通りです。
- step()関数:
エージェントから受け取った行動に従って環境を変化させ、報酬・状態・試行を終えるかどうかを返す - reset()関数:
環境を初期化し、その状態を返す
途中の計算は解決する課題によって異なりますので、今回も要点のみ説明します。
1. step()関数
1回のステップで、自分と相手が順番に石を置きます。
対戦相手はself.opponent_agentで表されています。
この変数に自分自身を定義すると自己対戦になり、学習済みエージェントを定義するとそのエージェントに勝てるように学習を行います。
自己対戦と言っても特殊なアルゴリズムを利用する訳ではなく、対戦相手のターンに自分自身が最適と思う行動をさせるだけです。
環境を変化させる要因が自分だけではないため、エージェントにとっては学習が難しくなる可能性はありますが、実装としては順番に処理を行うだけになります。
def step(self, action):
x, y = self.action_to_xy(action)
if self.verbose:
print("agent's move: {}, {}".format(x, y))
info = None
if not self.is_valid_move([x, y]):
if self.verbose:
print("not a valid move!")
reward = -1
done = True
return self.get_obs(), reward, done, info
# actionに応じて石を置く
self.board[y][x][self.PLAYER_AGENT] = 1
# 勝敗をチェックする
agent_win = self.check_finish((x, y))
if agent_win:
reward = 1
done = True
return self.get_obs(), reward, done, info
elif not self.is_ok_to_continue():
reward = 0.5
done = True
return self.get_obs(), reward, done, info
# 対戦相手が石を置く
if self.opponent_agent is not None and random.random() > self.opponent_epsilon:
opponent_action = self.opponent_agent.act(self.get_obs_inverse())
x, y = self.action_to_xy(opponent_action)
else:
x, y = self.get_move_random()
if self.verbose:
print("opponent's move: {}, {}".format(x, y))
self.board[y][x][self.PLAYER_OPPONENT] = 1
# 勝敗をチェックする
opponent_win = self.check_finish((x, y))
if opponent_win:
if self.verbose:
print("opponent won!")
reward = -1
done = True
return self.get_obs(), reward, done, info
elif not self.is_ok_to_continue():
reward = 0.5
done = True
return self.get_obs(), reward, done, info
# 勝敗が決まらなかった場合
reward = -0.001
done = False
return self.get_obs(), reward, done, info
2. reset()関数
全てのマスを空にします。
この時点で先攻後攻を決め、後攻の場合は相手が石を置いた状態を初期状態として返します。
def reset(self, opponent_first=None):
if self.verbose:
print('****** game reset ******')
# 全てのマスを空にする
self.board = np.zeros(self.board.shape)
# 先攻後攻をランダムに決める
# 後攻の場合は相手が石を置いた状態を初期状態とする
if opponent_first is None:
opponent_first = random.choice([True, False])
if opponent_first:
if self.opponent_agent is not None and random.random() > self.opponent_epsilon:
opponent_action = self.opponent_agent.act(self.get_obs_inverse())
x, y = self.action_to_xy(opponent_action)
else:
x, y = self.get_move_random()
if self.verbose:
print("opponent's move: {}, {}".format(x, y))
self.board[y][x][self.PLAYER_OPPONENT] = 1
return self.get_obs()
●学習用のPythonファイル
chainerrl_n_moku.pyに該当します。
なお、このソースコードはMITライセンスのもと利用を許諾するものとします。
学習のアルゴリズムなどに変更はありませんが、記述方法を変更しました。
今まではエピソードやステップの分だけFor文を回していましたが、ChainerRLではそれらを省略した書き方ができます。
学習方法は変わらないため、参考にしてください。
def train(env, agent, save_dir, steps):
chainerrl.experiments.train_agent_with_evaluation(
agent, env,
steps=steps,
eval_n_runs=10, # 10 episodes are sampled for each evaluation
max_episode_len=200, # Maximum length of each episodes
eval_interval=1000, # Evaluate the agent after every 1000 steps
outdir='result') # Save everything to 'result' directory
agent.save(save_dir)
●学習済みエージェントと対戦するためのファイル
n_moku_gui.pyに該当します。
このファイルは人間が学習済みエージェントと対戦するための画面を描画するためのファイルになります。
深層強化学習には影響を与えないソースコードですので、説明は省略させて頂きます。
なお、このソースコードは MITライセンス のもと利用を許諾するものとします。
学習を行う
これでコードの準備が整いましたので、実際に学習をさせてみましょう。
以下のコマンドを3つのファイルがあるディレクトリで実行することで学習が始まります。
python chainerrl_n_moku.py
学習終了後、nmokuagentというフォルダに学習済みモデルが保存されます。
続いて、以下のコマンドを実行することで、学習したエージェントと3目並べで対戦することができます。
python chainerrl_n_moku.py --test_interactive
対戦用画面が開きますので、交互に石を並べてみてください。
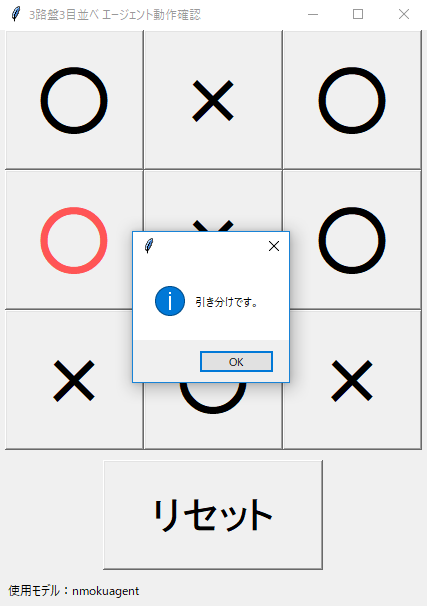
正しく学習できているようで、私と同等の強さになりました。
また、今回は3×3の盤面で3目並べを実装しましたが、盤面の大きさや並べる石の数は変更することができます。
以下のように学習を実行すると、5×5の盤面で4目並べを学習することが可能です。
学習済みモデルは4mokuagentに保存されます。
python chainerrl_n_moku.py --board_size 5 --n_moku 4 --save_dir 4mokuagent
このようにした場合、対戦する時も以下のように盤面の大きさと並べる石の数を指定してください。
python chainerrl_n_moku.py --test_interactive --board_size 5 --n_moku 4 --save_dir 4mokuagent
ただし、取り得る状態の個数がかなり増えるため、同じ条件で学習しただけではうまくいきません。
正しく学習させるためには、試行回数を増やすなど、様々な工夫をする必要があります。
まとめ
全3回を通して、様々なケースで深層強化学習を実装しました。
機械学習で実現できることの幅が広がったということが理解して頂けたかと思います。
大切なことは、教師あり学習を置き換えるような技術ということではなく、それぞれ解決できる課題が違うということです。
深層強化学習では事前に学習データを準備するという手間は省けますが、その分簡単に実装できるという訳ではありません。
代わりに、環境や3つの相互作用の定義という別の手間がかかります。
これらを定義するためには、深層強化学習以外の知識も必要となります。
環境を定義する際には、数学や物理などの知識が必要になることも多々ありますし、3つの相互作用を定義する際には、解決したい課題への正しい理解が必要となります。
このことを理解した上で、深層強化学習を利用するべきか教師あり学習を利用するべきかを判断してください。
また、今回はDoubleDQNというアルゴリズムを利用し、各種パラメータはほとんどデフォルト値としています。
それでも様々なケースを正しく学習することができました。
しかし、複雑な課題を解決する際にはアルゴリズムの選択やパラメータの調整が必要になります。
ChainerRLには様々なアルゴリズムが用意されていますし、主要なパラメータは簡単に変更することができます。
まずは今回実装したものをさらに良くするためには何を変更したら良いのか、試行錯誤をして理解を深めてみてください。
そしてお時間のある方は4目並べを正しく学習できるエージェントの作成にチャレンジしてみてください。
お読み頂き、ありがとうございました。
- BACK
- 1
※Chainer(R)は、株式会社Preferred Networksの日本国およびその他の国における商標または登録商標です。
その他、本コンテンツ内で利用させて頂いた各プロダクト名やサービス名などは、各社もしくは各団体の商標または登録商標です。
