

こんにちは、SCSK株式会社 R&Dセンターの齋藤です。
第1回では、深層強化学習の概要をご説明しました。
OpenAI Gymで用意されている環境を利用することで、簡単に深層強化学習を実装できたと思います。
しかし、自分が直面している課題に対して、環境がいつも用意されているとは限りません。
むしろ、そうでない場合のほうが多いでしょう。
ですので、第2回では自分で作った環境で深層強化学習を実装することに挑戦します。
今回は「ライントレーサー」を題材にしたいと思います。
ライントレーサーとは
ライントレーサーとは、ライン(線)をトレース(追跡)するものです。
ライントレーサー自体は強化学習でなくても実現することが可能です。
線上にあるかどうかを判断するセンサーを2つ持った機械を準備することができたとしましょう。
あとは、以下の2つのルールを実装するだけで実現することができます。
1. 両方のセンサーが反応しなければ直進する
2. センサーが反応したら、反応があったセンサーの方向に曲がる
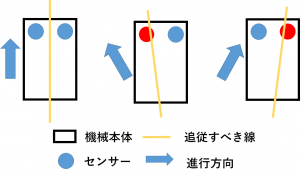
非常に単純なルールのため、実装は容易ですが、今回はこのルールは与えずに深層強化学習を用いてライントレーサーのルールを見つけます。
深層強化学習で実装
第1回でも述べたように、深層強化学習では「エージェント」、「環境」、「3つの相互作用」を定義する必要があります。
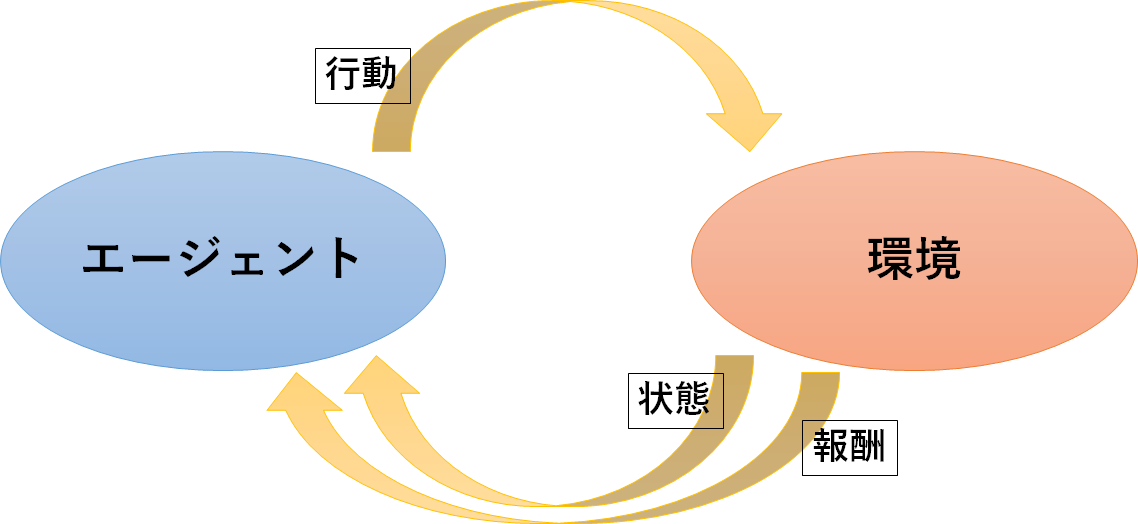
エージェント
深層強化学習で実装しますので、ニューラルネットワークを実装します。
ただし、今回はニューラルネットワークの中間層の構成や学習アルゴリズムは前回のCartPoleと同じにします。
ニューラルネットワークの入出力は、観測する”状態”の数と選択可能な”行動”の数に依存するため、CartPoleとは異なります。
環境
ライントレーサー本体と、トレースする対象を定義する必要があります。
ライントレーサー本体は、エージェントの指示を受けて行動をとる環境となります。
紺の円がライントレーサー本体を表し、ピンクの円は線上にいるかどうかを判断するためのセンサーを表しています。
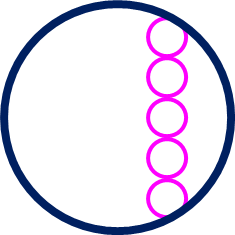
どのような線でも問題はありませんが、今回はわかりやすいように下図のような単純な図形をトレース対象とします。

また、今回は解決する課題をシンプルにするため、移動の抵抗などは考慮しません。
3つの相互作用
●行動
エージェントがとれる行動を定義します。
下図の黄色矢印が示している7方向の内のどこか1方向へ進むこととします。
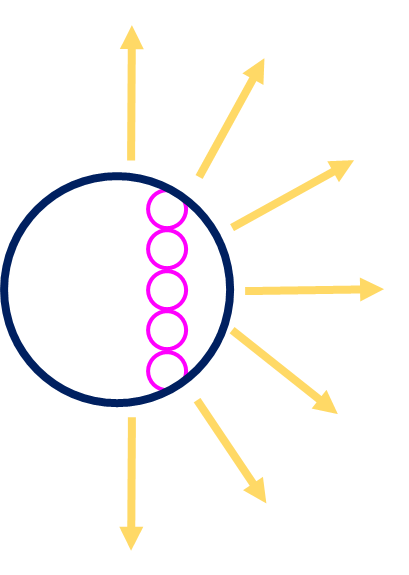
●状態
エージェントが観測できる環境の要素を定義します。
トレーサーには、線上にあるかどうかを判断する複数のセンサーを搭載していますので、その値を状態とします。
上述のライントレーサーの説明では2個のセンサーを搭載していましたが、
今回は精度をあげるため合計5個のセンサーを配置しています。
●報酬
以下のように報酬を定義します。
- 黒に反応しているセンサーの数に応じて、最大で1点を与える
- 黒に反応しているセンサーが1つもないときは‐1点を与える
- エージェントが画像の外へ出たときは-10点を与える
エージェントはこの報酬が大きくなるように学習していくはずです。
ChainerRLで実装
今回は環境用の画像ファイルとしてtarget.png、自前環境用のPythonファイルとしてenv_line_trace.py、学習用のPythonファイルとしてchainerrl_line_trace.pyを用意しました。
こちらのzipファイルを展開してください。
●環境用の画像
target.pngに該当します。
今回はトレース対象を画像から読み込むようにしていますので、この画像を変更することで、トレース対象が変更されます。
なお、この画像のライセンスは CC0とします。
●自前環境用のPythonファイル
env_line_trace.py に該当します。
このファイルでは環境だけではなく、3つの相互作用も定義します。
なお、このソースコードは MITライセンス のもと利用を許諾するものとします。
前回のCartPoleではOpenAIGymを利用していたため不要でしたが、今回は自前の環境を定義します。
このPythonファイルでは学習の様子を描画するために、OpenCVというライブラリを利用しています。
以下のコマンドを実行して、インストールを行ってください。
pip install opencv-python
また、第1回でChainerRLをインストールしていない方はインストールを行ってください。
自前環境用を作る際のポイントの1つは、OpenAI Gymの環境クラスを継承していることです。
OpenAI Gymの環境クラスを継承することで、環境作成が容易になります。
クラスを定義する際にclass ClassName(gym.core.Env):のように、継承しましょう。
また、ChainerRLを使う際にはstep()関数とreset()関数の2つの関数の定義が必須になります。
1. step()関数:
環境に行動を反映させるための関数です。
この関数では以下の処理を行います。
- エージェントから行動を受け取る
- 行動を環境を反映させる
- 状態と報酬を計算する
- 1回の試行を終えるかどうかの判断をする
- 状態と報酬と試行を終えるかどうかの判断結果を返す
途中の計算に関しては、解決する課題によって異なるため、計算方法の説明は省略します。
今回のライントレーサーでは主に以下の計算を行っています。
- トレーサー本体を移動する
- 移動先でのセンサー情報を取得し、黒線に反応しているセンサーの個数の計算する
- トレーサーが画面外に出ているかどうか、指定回数の試行を繰り返したかどうかを判断する
'''
エージェントからactionを受け取り、その行動後の状態や報酬を返す。
1. エージェントから受け取ったactionに従って、Tracerを移動させる
2. 移動先でセンサー情報を取得する
3. センサー情報に基づいて報酬の計算を行う
4. 試行を終わらせるかどうかを判断する
5. 状態、報酬、試行終了の判断結果 をエージェントに返す
'''
def step(self, action):
done = False
# actionに従って移動する
self.direction = self.direction + self.direction_list[action]
self.pos_x = self.pos_x + self.distance * np.cos(self.direction)
self.pos_y = self.pos_y + self.distance * np.sin(self.direction)
# 移動先でセンサー情報を取得する
self.pos_sensor_list = self.get_sensor_pos()
state = np.array([1.0 if np.sum(self.target_img[int(x), int(y)]) == 0 else
0.0 for (y, x) in self.pos_sensor_list])
# 報酬を計算する
# 黒に反応したセンサーの個数が多いほど点数が増え、最大1を与える
# 黒に反応したセンサーが無い場合は-1を与える
reward = np.mean(state) if np.sum(state) != 0 else -1
# Tracerが場外に出たら試行を終了する
# 報酬は-10を与える
if self.pos_x < self.radius or self.pos_x > self.target_img_width - self.radius or self.pos_y < self.radius \
or self.pos_y > self.target_img_height - self.radius:
done = True
reward = -10
# 指定のstep数経過したら試行を終了する
if self.step_count > self.max_episode_len:
done = True
else:
self.step_count += 1
return state, reward, done, {}
2. reset()関数:
環境を初期化するための関数です。
毎試行の始まりに呼ばれるもので、初期化時の状態を返します。
ライントレーサーでは、主にトレーサー本体を初期位置に戻すという処理をしています。
# 環境を初期化して状態を返す
def reset(self):
# Tracerの中心位置を初期化
self.pos_x = 400
self.pos_y = 80
# Tracerの向き (0~2πで表現)を初期化
self.direction = 0
# センサーの位置を取得
self.pos_sensor_list = self.get_sensor_pos()
# step数のカウントを初期化
self.step_count = 0
# OpenCV2のウィンドウを破棄する
cv2.destroyAllWindows()
return np.array([1.0 if np.sum(self.target_img[int(x), int(y)]) == 0 else 0.0 for (y, x) in self.pos_sensor_list])
環境と3つの相互作用は解決する課題に合わせて自分で考えるしかありません。
これらを正しく定義することが深層強化学習で最も重要なことでもあり、最も手間のかかることでもあります。
また、解決する課題によっては数学や物理などの幅広い知識が必要になります。
●学習用のPythonファイル
chainerrl_line_trace.py に該当します。
なお、このソースコードは MITライセンス のもと利用を許諾するものとします。
前回のCartPoleとは違い、自前の環境を利用します。
ただ、学習のアルゴリズムは変更しておらず、以下の環境を呼び出す部分のみ変更されています。
env = gym.make('CartPole-v0')→env = EnvLineTrace(5, 7, 'target.png')
これにより、自前環境のPythonファイルを利用して学習を行うことができます。
また、今回追加したtest_episode()関数は学習後に動作を確認するための関数なので、学習には影響を及ぼしません。
学習を行う
これでコードの準備が整いましたので、実際に学習をさせてみましょう。
以下のコマンドを3つのファイルがあるディレクトリで実行することで学習が始まります。
python chainerrl_line_trace.py
学習終了後、line_trace_agentというフォルダに学習済みモデルが保存されます。
続いて、以下のコマンドを実行することで、学習した結果の動作を確認できます。
python chainerrl_line_trace.py --test
また、黒線の上を走ることだけに報酬を与えて学習を行ったので、
同じ学習済みモデルを利用しても、違う形状の黒線をトレースすることができます。
また、状態や行動は容易に変更できるようになっていますので、ご興味のある方は条件を変更させて学習させてみてください。
おわりに
第2回では、自前の環境で深層強化学習を行いました。
環境と3つの相互作用を定義することは容易ではありませんが、準備さえしてしまえば学習が可能です。
ただし、裏を返せば、これらを定義できない問題に対しては強化学習では解決することができません。
第1回でも述べましたが、機械学習の3つの手法には向き不向きがあります。
強化学習に向いている課題かどうかを判断する時には、環境や3つの相互作用を定義することができるのかどうかを考えると良いでしょう。
教師あり学習において、良い結果を出すためには良い学習データが必要でした。
深層強化学習において、良い結果を出すためには良い環境と3つの相互作用の設計が必要になります。
2回を通して、深層強化学習の良い点と悪い点をお伝えできたかと思います。
次回は、別の事例を題材にして深層強化学習のテクニックをお伝えします。
※Chainer(R)は、株式会社Preferred Networksの日本国およびその他の国における商標または登録商標です。
その他、本コンテンツ内で利用させて頂いた各プロダクト名やサービス名などは、各社もしくは各団体の商標または登録商標です。
