
2026.01.28





皆様、はじめまして
「NebulaShift di」のKafka技術を担当しております、上村と申します。
本ブログではKafkaの概要から具体的なユースケースまで紹介させていただければと思います。
第0回で第1回はDatabricksに関する記事だと告知しておりましたが、私自身のKafkaへの熱量が高まりすぎた結果、予定より早く記事が仕上がってしまいました。 そのため、順番が前後してしまい大変恐縮ですが、急遽Kafka編を第1回としてお届けします。
Databricks編をお待ちの皆様も、ぜひ今回はKafkaについて最後までお付き合いいただけますと嬉しいです。
企業システムの高度化・多様化が進む一方、部門ごとに異なる業務システムやSaaS、IoT機器などから発生する多様なデータを"つなぐ"ことが大きな課題となっています。
具体的には、現状のデータ連携には以下のような課題が存在します。
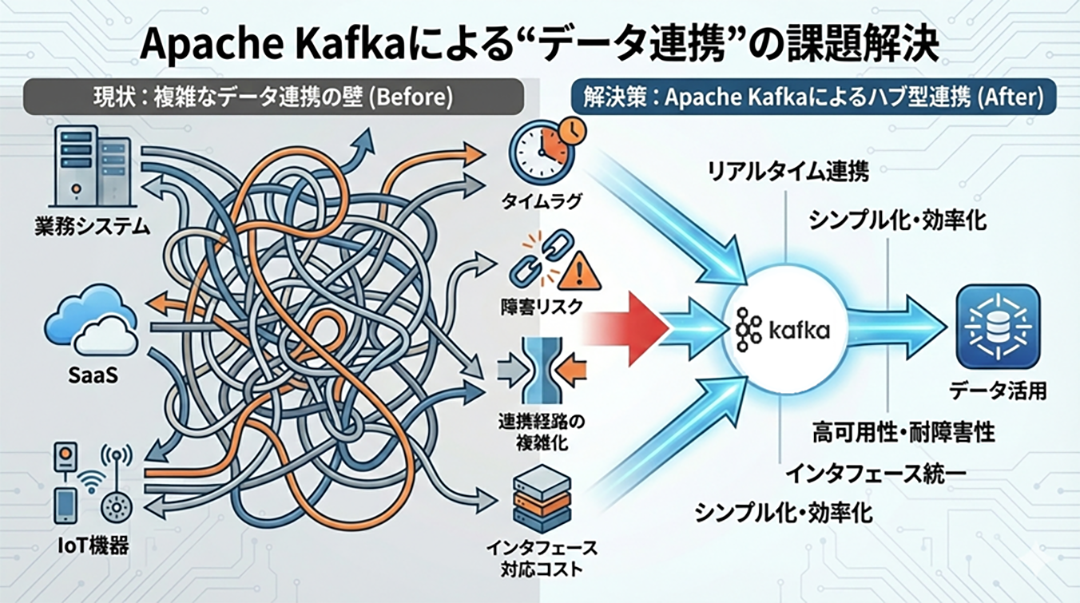
こうした「連携経路の複雑化」「障害時停止のリスク」「インタフェース対応コスト」がシステム運用現場の悩みの種になっています。
上記課題を解決するために、Apache Kafkaが有効です。
Apache Kafkaは、分散型でスケーラブルなストリーミングデータプラットフォームです。 特徴的なのは「超高速スループット」「低レイテンシ」「自動冗長化・切替で止まらない」設計思想です。 Kafka導入することで、データ連携に関して下記4点の効果が期待できます。
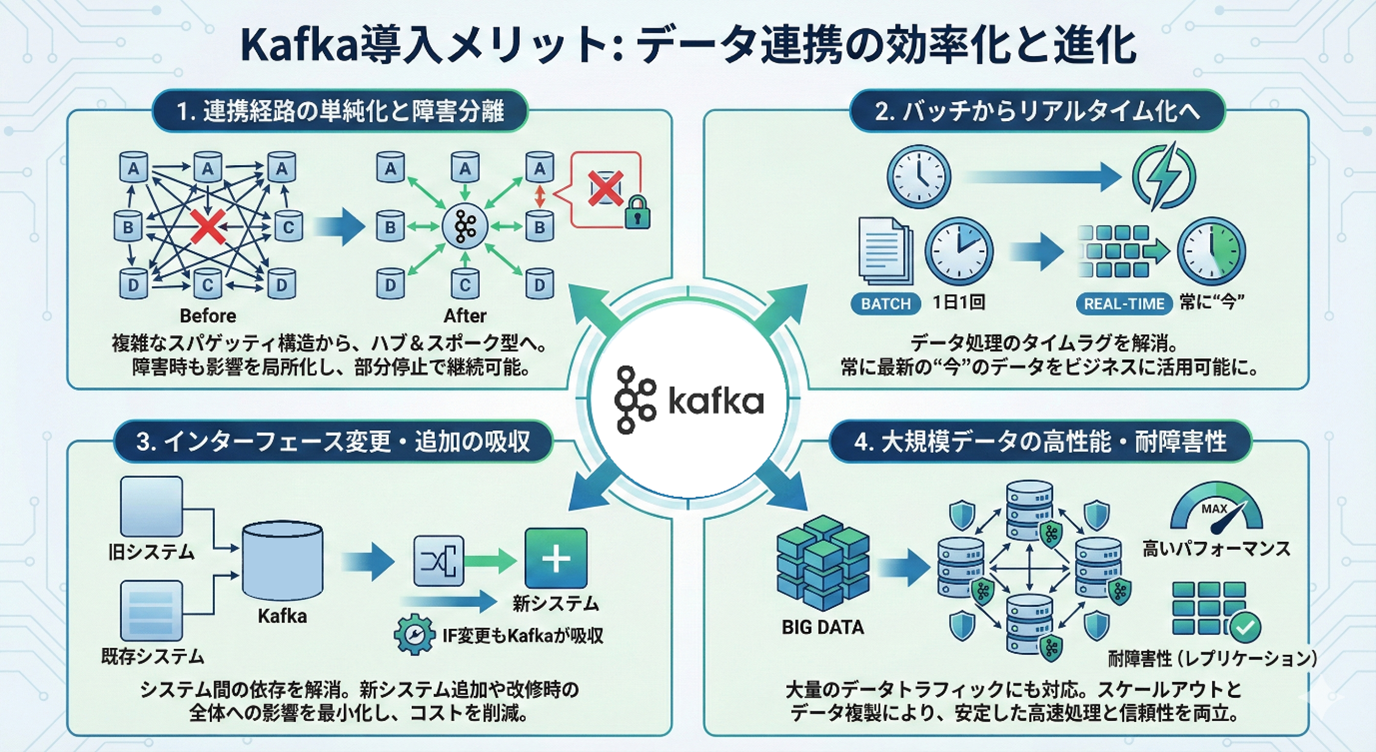
結果、部門間・業務間・内外のシステムをつなぐデータ基盤の近代化が、現場運用の負担もコストも大きく軽減します。
Kafkaの代表的なユースケースとしては下記となります。
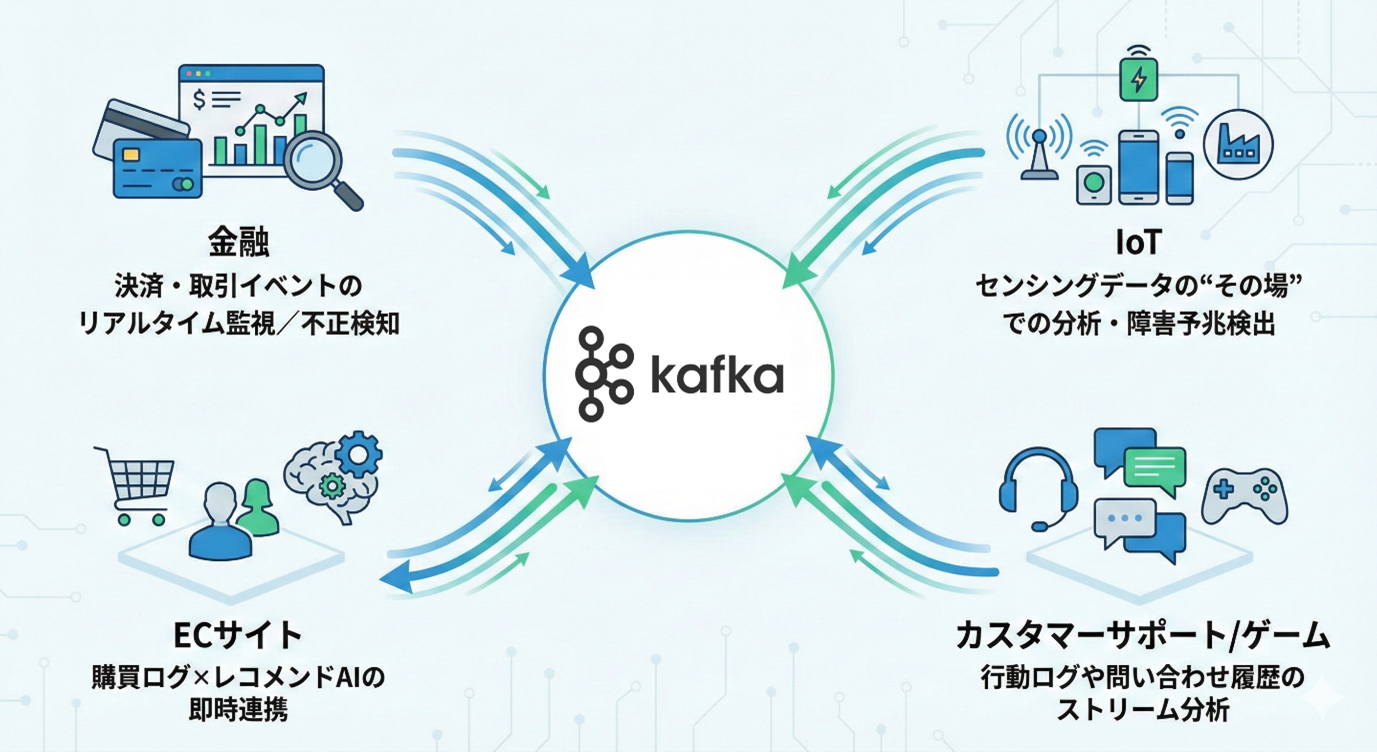
既存DB、DWH、APIにも自在に接続でき、「リアルタイムに生まれる価値」を拡張できます。
いかがでしたでしょうか。
初めての記事ということもあり、非技術者の方々にとって少しわかりづらかったかもしれません。
今後も様々な職種・業種の方々に向けて更新していきますので、今後もぜひご覧いただけると嬉しいです。
今後のデータ活用に不可欠なのは「止まらない、さばける、つなげる」連携基盤です。
Apache Kafkaなら、刻々と変化するビジネス現場とシステムを、しなやかに結び続けることが可能です。
もし「データを活用したいのに、既存のやり方で限界を感じている」という場合は、ぜひKafka活用をご検討いただければと思います。
NebulaShift di・メッセージング基盤導入サービス

記載されている製品/サービス名称、社名、ロゴマークなどは該当する各社の商標または登録商標です。
本ブログ記事は正確性を保証するものではなく、記事の内容によって生じた結果について、いかなる責任も負いません。

