

目次

皆様、はじめまして
「Hybrid Cloud di」のDatabricks技術を担当しております、天野と申します。
これからよろしくお願いします。
早速ですが昨今、DX(デジタルトランスフォーメーション)や生成AIの活用が叫ばれる中、「データ活用」は企業にとって避けて通れない経営課題となりました。しかし、多くの企業様からこのようなお悩みをよく耳にします。
もし、あなたの会社でも同様の課題をお持ちなら、その解決策は「Databricks(データブリックス)」にあるかもしれません。
本記事では、Hybrid Cloud diの取扱製品群の1つであるDatabricksについて、なぜ今、世界中のトップ企業がこぞってDatabricksを採用しているのか。その魅力とメリット、具体的な活用事例を徹底解説します。
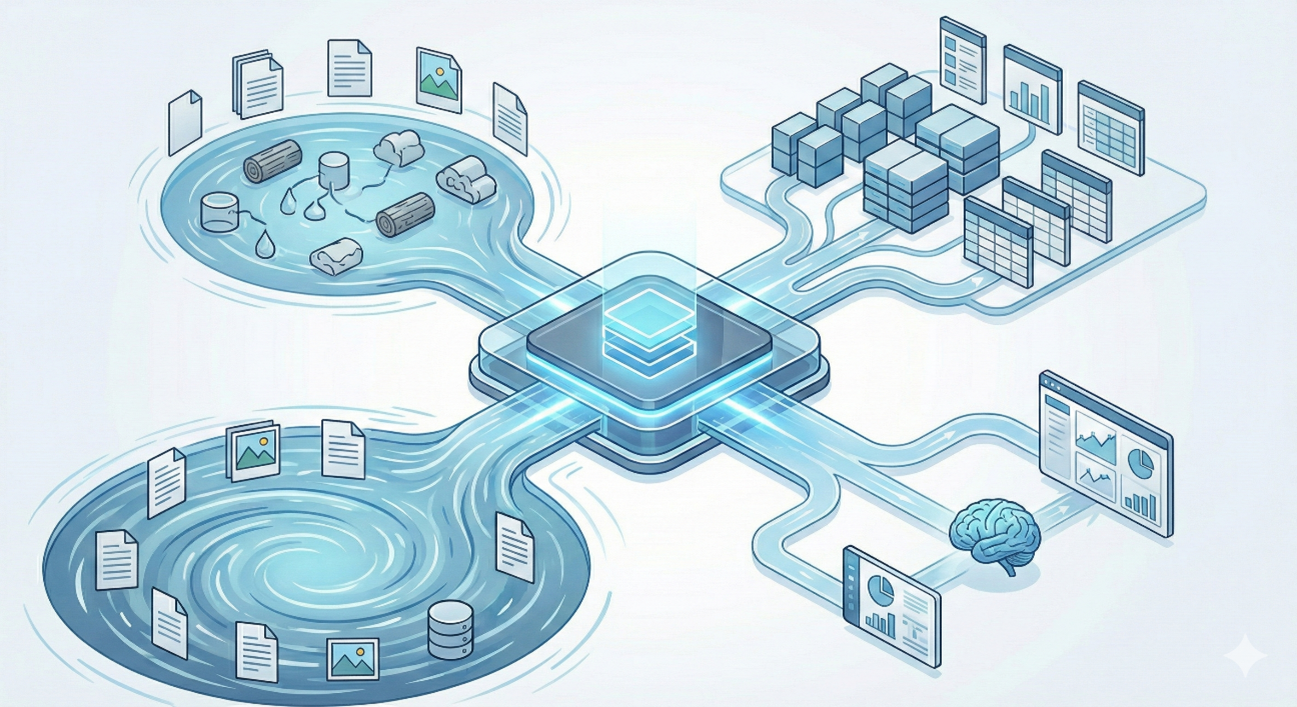
Databricksを一言で表すなら、「データレイクの柔軟性と、データウェアハウスの管理・性能を兼ね備えた統合データプラットフォーム」です。これを「データ・インテリジェンス・プラットフォーム」と呼びます。
これまで、データ基盤は大きく2つに分かれていました。
多くの企業はこれらを並立させていましたが、結果として「データの二重管理」「データ移動のコスト」「整合性の不一致」という大きな壁にぶつかっていました。
Databricksは、この壁を壊しました。データは全て「データレイク」にあるままで、DWHのような高速なSQL分析も、Pythonを使った高度なAI開発も、同じデータに対して行えます。 「分析のためにデータをコピーする」という無駄な作業は、もう必要ありません。
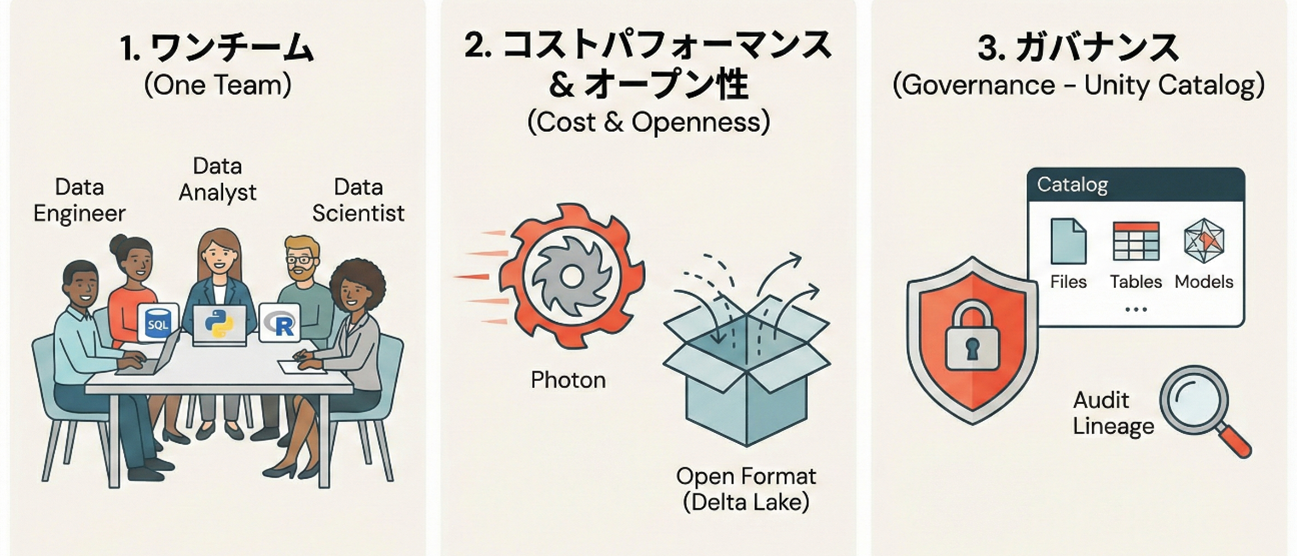
なぜDatabricksが選ばれるのか。ビジネスと技術、両面からのメリットをご紹介します。
従来の環境では、エンジニアがデータを整え、それをアナリストがSQLで集計し、サイエンティストが別の環境にデータを移してモデルを作る...というバケツリレーが発生していました。 Databricksなら、SQL、Python、R、Scalaなど、各自が得意な言語を使って、たった一つのプラットフォーム上で協業できます。これにより、データパイプラインの構築からモデルのデプロイまでのリードタイムが劇的に短縮されます。
DatabricksはオープンソースのApache Sparkを源流としており、独自の高速化エンジン「Photon」を搭載しています。これにより、大量データの処理において驚異的なスピードとコスト効率を実現します。 また、Databricksが採用しているデータ形式「Delta Lake」はオープンフォーマットです。特定のベンダーにデータがロックインされる心配がなく、将来にわたって自社の資産としてデータを保持できる点は、長期的なIT戦略において極めて重要です。
「データを活用させたいが、セキュリティが不安」というジレンマを解決するのが、Unity Catalogです。 ファイル、テーブル、そしてAIモデルに至るまで、あらゆるデータ資産の権限を一元管理できます。「誰が、いつ、どのデータを使ったか」という監査ログ(リネージ)も自動で記録されるため、セキュリティ担当者も安心して現場にデータを開放できます。
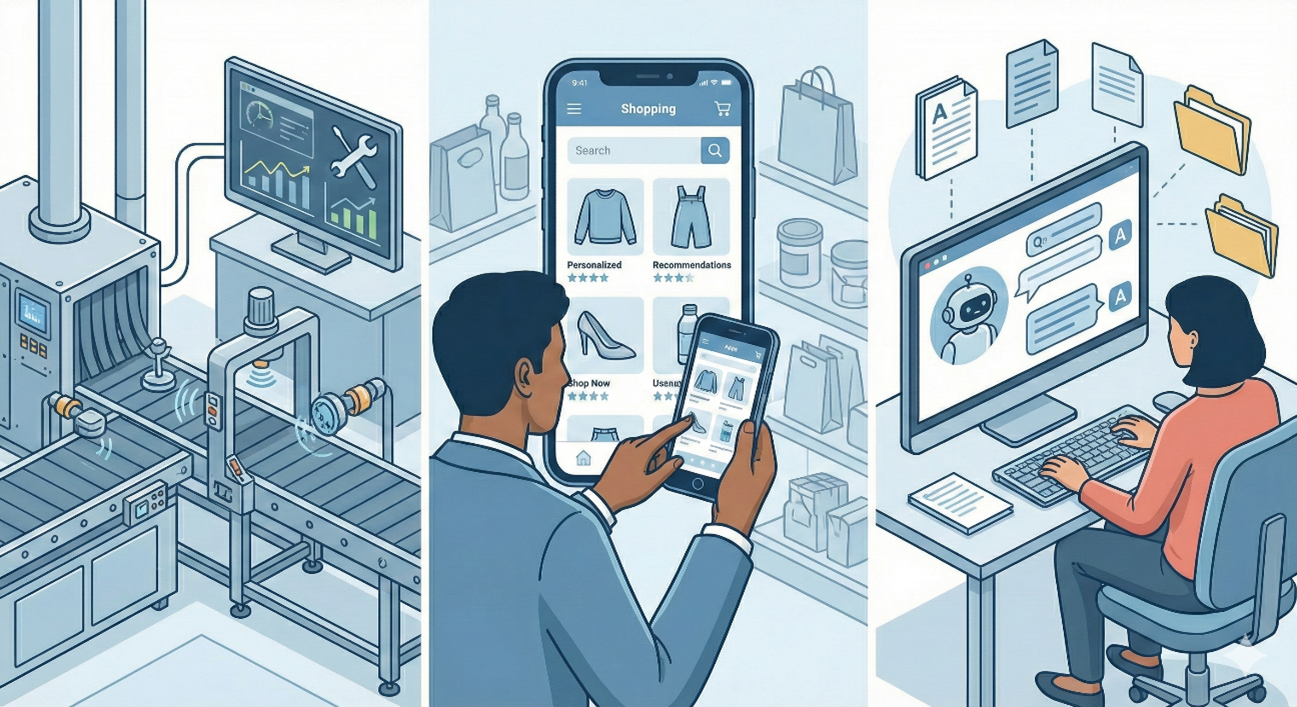
「機能はわかったけれど、具体的にどう使えるの?」という疑問にお答えするため、代表的なユースケースを3つご紹介します。
工場内のセンサーから送られてくる膨大なIoTデータ(時系列データ)。従来のリレーショナルデータベースでは処理しきれなかったこのデータを、Databricksのストリーミング機能でリアルタイムに取り込みます。
POSデータ、Webサイトの閲覧ログ、アプリの行動履歴。これらバラバラなデータをDatabricks上で統合し、「顧客一人ひとりの行動」を時系列で完全に可視化します。
今最も注目されているのが、ChatGPTなどのLLM(大規模言語モデル)と、自社の社内データを組み合わせる活用法です。
実際にSCSKのグループ会社 ネットワンシステムズ社においても、社内QAサポートにDatabricksで構築したRAG基盤を活用している事例がございます。
Databricksは非常に強力なプラットフォームですが、その真価を発揮するためには、「正しいアーキテクチャ設計」と「データエンジニアリングのノウハウ」が不可欠です。
弊社では、単なるライセンス販売にとどまらず、以下のようなご支援が可能です。
また、Databricks単体だけではなく、お客様のニーズに合わせてHybrid Cloud diの他取扱製品(今後本技術ブログでもそれぞれご紹介させていただく予定です。)と組み合わせたご提案についても、SCSKなら一括で実施できます。

データは「21世紀の石油」と言われますが、原油のままでは車のガソリンにはなりません。精製(加工)し、エンジン(AI・分析)に供給して初めて価値を生みます。 そのための最高の製油所兼エンジンこそが、Databricksです。
「データはあるが活用できていない」「AI導入を進めたいが基盤がない」 そんなお悩みをお持ちの企業様、まずは一度弊社にご相談ください。あなたの会社のビジネスを変革する最初の一歩を、私たちSCSKが全力でサポートいたします。

記載されている製品/サービス名称、社名、ロゴマークなどは該当する各社の商標または登録商標です。
本ブログ記事は正確性を保証するものではなく、記事の内容によって生じた結果について、いかなる責任も負いません。







