

こんにちは、SCSK株式会社 R&Dセンターの齋藤です。
これから3回にわたり、「ChainerRL」というOSSを使った深層強化学習の実装方法について解説いたします。
はじめに
2019年現在、世の中は第3次AIブームの真っただ中です。
最近では、様々なモノに “AI” という名前が付き、一般社会にも浸透してきています。
今回のブームの火付け役となった技術は、ディープラーニングという技術です。
ディープラーニングを使うことで、顔認識などの特定の分野において、人間を上回る能力を発揮したことでブームが始まりました。
今回解説する深層強化学習は、強化学習とディープラーニング(深層学習)を組み合わせたものです。
- 「深層強化学習」 = 「強化学習」 + 「ディープラーニング」
囲碁の対戦で、プロ棋士に勝ったDeepMind社の「AlphaGo」に使われていたこともあり、注目を集める技術の1つです。
機械学習の分類
深層強化学習の説明に入る前に、機械学習の学習方法について整理をしましょう。
機械学習には一般的に「教師あり学習」・「教師なし学習」・「強化学習」の3つに分けることができます。
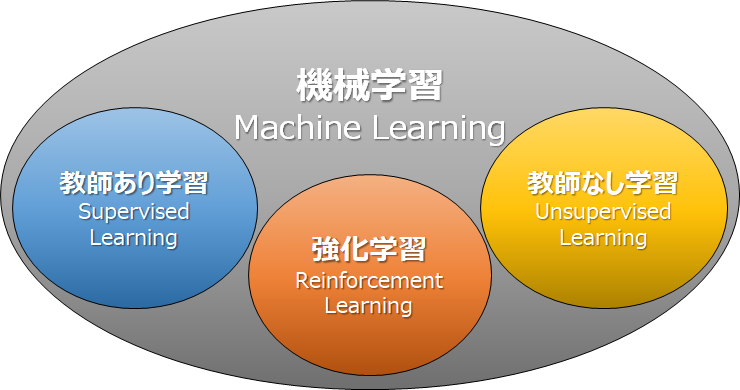
教師あり学習
教師あり学習では、正解ラベルのついた学習データから「入力と出力の関係」を学習します。
例えば、犬と猫の画像分類を教師あり学習で実装する際、犬の画像(学習データ)に対して「これは犬である」という情報(正解ラベル)を付与します。
この正解ラベルは、機械に出力させたいデータの見本です。
これにより、機械は自分の出力が見本通りになるように学習を進めることができます。
昨今のAIでは教師あり学習が主流の学習方法です。
明示的に正解を与えているため、人間が意図した答えを出力させやすいのですが、
学習データの収集やデータに正解ラベルを付与することの手間が課題となっています。
教師なし学習
教師なし学習では、正解ラベルのない学習データから「データ群の構造」を学習します。
例えば、画像の類似度を出すことを教師なし学習で実装する際、画像Aと画像Bが似ているという情報は付与しません。
大量の画像を学習データとして入力するだけで、画像の特徴から類似度を出力できます。
そのため、画像に正解ラベルを付与するという手間はありませんが、
正解がわからないため、見当違いな結果を出してしまうことがあります。
強化学習
強化学習では、試行錯誤をすることで「最適な行動系列」を学習します。
行動系列とは、何かを成し遂げるまでの一連の行動のことです。
基本的に学習データは不要なため、データの収集や正解ラベルの付与は行いません。
この考え方は、深層強化学習であっても同じです。
強化学習のイメージを持っていただくため、「CartPole」という有名な問題をご紹介します。
これは「台車を左右に動かすことで棒を倒さないようにする」という問題を、強化学習で解いています。
<学習前>
<学習後>
棒が大きく傾いた場合や、台車が大きく横に移動した場合などの失敗の試行結果と、一定時間棒を倒さないという成功の試行結果のどちらであっても、中央に戻って再度試行を行います。
学習前の動画では、棒がすぐに傾いてしまうので、すぐに中央に戻っています。
学習後の動画は、200回ほど試行を続けた後の状態です。
こちらは学習前よりも長時間、棒を倒さない状態を維持できています。
*こちらのソースコードについては、この記事後半に掲載しています。
ここで重要なのは、「棒の角度が何度傾いている時に、どちらにどれだけ移動したら倒れない」という学習データは、一切与えていないということです。
「教師あり学習」では、このような学習データを大量に与えることによって棒を倒さないようにするのに対し、
強化学習は、動画のような試行錯誤を繰り返す中から、どう動いたら棒が倒れないのかを見つけ出す仕組みになります。
試行錯誤する中で最適な行動を見つけるという学習方法は、人間に近いと言えます。
最近の家電は説明書を読まなくても操作できる製品が多いため、実際にボタンを押して、何が起きたのかを観察することで、使い方を理解していると思います。
もちろん、人間には過去の経験などからの予備知識があるため、明確に同じとは言えません。
機械においては、その予備知識というハンデを膨大な回数の試行によって埋めています。
また、学習データを与えていないため、人間が思いつかないような行動系列を発見できるのも、強化学習の大きなメリットの1つです。
ただし、もちろん何もない状態で学習を行うことはできません。
強化学習では学習データの代わりに、”試行錯誤ができる状態”を準備する必要があります。
“試行錯誤ができる状態”とは、「エージェント」と「環境」、そして「その間に生じる3つの相互作用」が定義されている状態を指します。
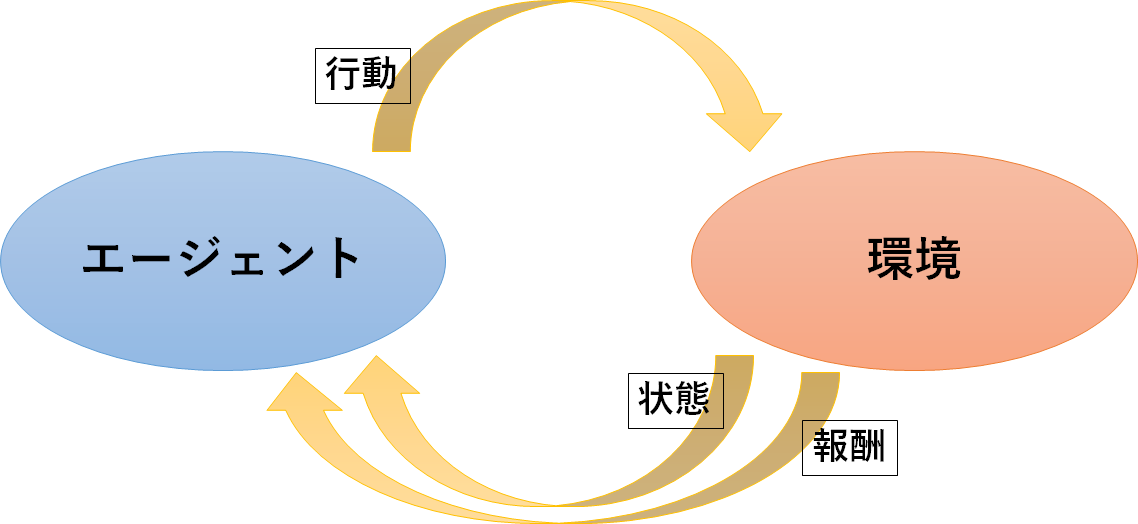
エージェント
試行錯誤を繰り返して、学習を行う主体です。
エージェントは、状態と報酬をもとに、次の行動を決めます。
「どの状態で、どんな行動を取ると、どういう報酬が得られるか」の情報を持たせることで、次に取る行動を選択できます。
後ほど説明しますが、深層強化学習と強化学習の大きな違いは、この選択にニューラルネットワークを用いるか否かです。
CartPoleの例では、台車の行動を決定する判定器がエージェントになります。
この判定器は人間で言うところの脳に該当します。
環境
エージェントが、働きかけを行う対象です。
強化学習は、膨大な回数の試行をするため、基本的にはシミュレーターで行います。
そのため、周辺環境を定義する必要があります。
仮に現実世界で試行をするのであれば、環境を定義する必要はありません。
ただし、前述した通り、膨大な回数の試行が行われます。
現実世界では、モノが壊れてしまうことも考えられますし、多くの場合、試行速度も落ちてしまいます。
そのため、最終調整以外はコンピューター上で学習することをお勧めします。
CartPoleの例では、棒や線路の物理的な対象に加えて、重力なども環境になります。
3つの相互作用
- 行動
「エージェント」から「環境」への働きかけを表します。
どんな行動を取ったら何が生じるか、ということは試行錯誤の中で学習できます。
ただ、行動の選択肢自体は事前に定義する必要があります。
CartPoleの例では、左に動くことと、右に動くことが行動になります。
- 状態
「エージェント」が観測できる「環境」の要素を表します。
エージェント自身が観測を行う場合や、外部から観測情報を受け取る場合があります。
CartPoleの例では、台車の位置や棒の傾きなどが状態になります。
- 報酬
「エージェント」にとっての「環境」に生じたことの良し悪しと、その度合いを表します。
報酬と聞くと良いものというイメージですが、強化学習の世界では報酬に負の値を設定することで、罰則を表現することができます。
何も知らない機械は、何が起きたら良いのか、何が起きたら悪いのかを判断することはできません。
そのため、事前に定義する必要があります。
CartPoleの例では、動画からはわかりませんが、棒が立ち続けている間、点数を1点与え続けています。
以上が、強化学習で定義する必要のあるものです。
「自分の取った行動に対して、周りの環境で起きた変化を観測し、さらにその変化が自分にとって良いものか、悪いものかを判断する。」
この試行錯誤を繰り返すことで、最も自分にとって良い変化を起こす行動系列を、見つけ出すことができます。
学習対象の違いに注意
「教師あり学習」、「教師なし学習」、「強化学習」の3つの学習方法を紹介しましたが、それぞれ学習対象が異なります。
そのため、解決できる問題も違うということに注意してください。
強化学習は基本的にデータ収集が不要だと述べましたが、問題によってはデータ収集が必要になってしまうケースもあります。
例えば、「質問に対して最適な回答をするAI」について教師あり学習と強化学習を比較します。
これは、「質問に対する最適な回答」という学習データを準備すれば「教師あり学習」で実装可能です。
Q&Aを自動で応答するチャットボットなどもこのように教師あり学習で実装されているケースが多いです。
では、このAIを強化学習で実装するとして、報酬の定義について考えます。
CartPoleでは棒の傾きなどの環境から得た値をもとに報酬を定義しました。
今回は回答結果の良し悪しによって報酬を決めることになるでしょう。
その回答結果の良し悪しを環境から値として得るためには、「正しい判断をするのに十分なデータ」を用意する必要があります。
しかし、「正しい判断をするのに十分なデータ」は結局「質問に対する最適な回答」になってしまうのです。
このデータを準備できたのであれば、教師あり学習で実装したほうがコストは少なくなります。
このように、データを準備しないと報酬を環境から予測できない問題は、強化学習は不向きと言えるでしょう。
3つの学習方法でどれが優れているということではなく、使い道が異なるということです。
強化学習に適した問題なのかどうかは、人間が見極める必要があります。
深層強化学習の概要
冒頭にも述べましたが、深層強化学習は、強化学習とディープラーニングを組み合わせたものです。
*ディープラーニングに関しましては、「TensorFlow + Keras 入門 ~ ウチでもできた⁉ ディープラーニング」でも、ご紹介していますので、併せてご参照ください。
強化学習では「どの状態で、どんな行動を取ると、どういう報酬が得られるか」を学習することで、最適な行動を選択します。
深層強化学習も学習対象は同じですが、行動の選択にニューラルネットワークを用いているという点で強化学習とは違います。
ニューラルネットワークを用いたことによる最も大きな変化は、連続値を扱えるようになったことです。
連続値を扱える
従来の強化学習では「どの状態で、どんな行動を取ると、どういう報酬が得られるか」を管理する際、Q Tableと呼ばれる下図のようなテーブルを用いていました。
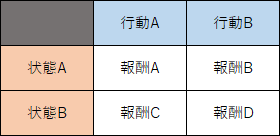
このテーブルを保有していれば、状態Aの時に行動Bを取ると報酬Bを受け取れるなどの判断をすることができます。
そして、その判断に基づいて最適な行動を選択できます。
しかし、このテーブルには限界があります。
CartPoleのように状態が連続する場合は、下記に示すように「離散化」させなくてはならないのです。
連続値や離散化について、状態の1つである棒の角度を例に説明します。
棒の角度は、最大値と最小値の制限はありますが、その間の値は無限に取り得ます。
これが連続値ということです。
離散化とは、連続値を特定の範囲で区分けして非連続の形で定義しなおすことです。
棒の角度で言えば、取り得る角度を「何度~何度の時は状態Aとする」のように定義して分割します。
そうすると、棒の角度は「状態A,状態B,状態Cの3つである」と取り得る値を数えることが可能になります。
一般に、連続値はこのように離散化することで様々な処理を行うことが可能になります。
連続値のままでは、取り得る値が無限のため、表にすることは不可能です。
そのため、表にするためには離散化する必要があります。
もちろん、状態は棒の角度だけではないので、それぞれについて離散化する必要があります。
ここで問題なのが、離散化することで一定幅の状態が同じとして扱われてしまうことです。
表現力が落ちるため、精度も落ちてしまいます。
ここでニューラルネットワークを使い、連続値を扱えるようにしたのが深層強化学習です。
CartPoleでは以下のようなニューラルネットワークになります。
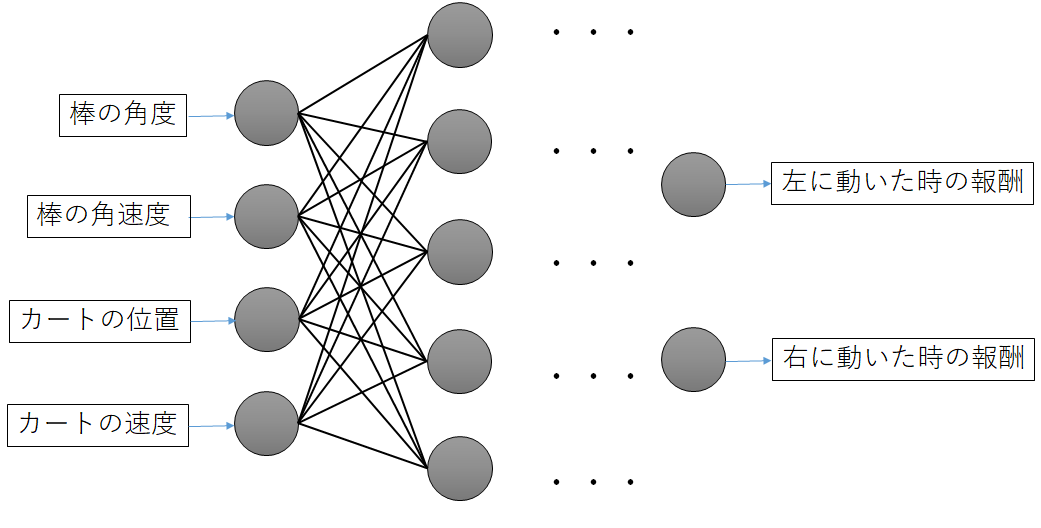
これにより、深層強化学習では表現力を落とさないで情報を扱えるようになりました。
また、深層強化学習のアルゴリズムとして有名なDQN (Deep Q-Network)では、入力の時系列を崩して学習させる、ニューラルネットワークの重みを更新するタイミングを制限する、報酬を[-1, 0, 1]に固定するなど、学習を成功させるための工夫がされています。
※Chainer(R)は、株式会社Preferred Networksの日本国およびその他の国における商標または登録商標です。
その他、本コンテンツ内で利用させて頂いた各プロダクト名やサービス名などは、各社もしくは各団体の商標または登録商標です。
